
機器學習與深度學習系列連載: 第二部分 深度學習(九)Keras- “hello world” of deep learning
Keras
Kearas 是深度學習小白程式碼入門的最佳工具之一。
- 如果想提升、練習程式碼能力,還是建議演算法徒手python實現。
- 複雜的深度神經網路專案還是推薦TensorFlow或者Pytorch
Keras是一個高層神經網路API,Keras由純Python編寫而成並基Tensorflow、Theano以及CNTK後端。
Keras 為支援快速實驗而生,能夠把你的idea迅速轉換為結果,如果你有如下需求,請選擇Keras:
簡易和快速的原型設計(keras具有高度模組化,極簡,和可擴充特性)支援CNN和RNN,或二者的結合無縫CPU和GPU切換。

Deep learning 程式設計其實是:搭積木!

“Hello world”
每種程式語言都有自己的hello world,我們開始deep learning 的hello world 之旅,手寫數字識別。用最簡單的DNN實現。
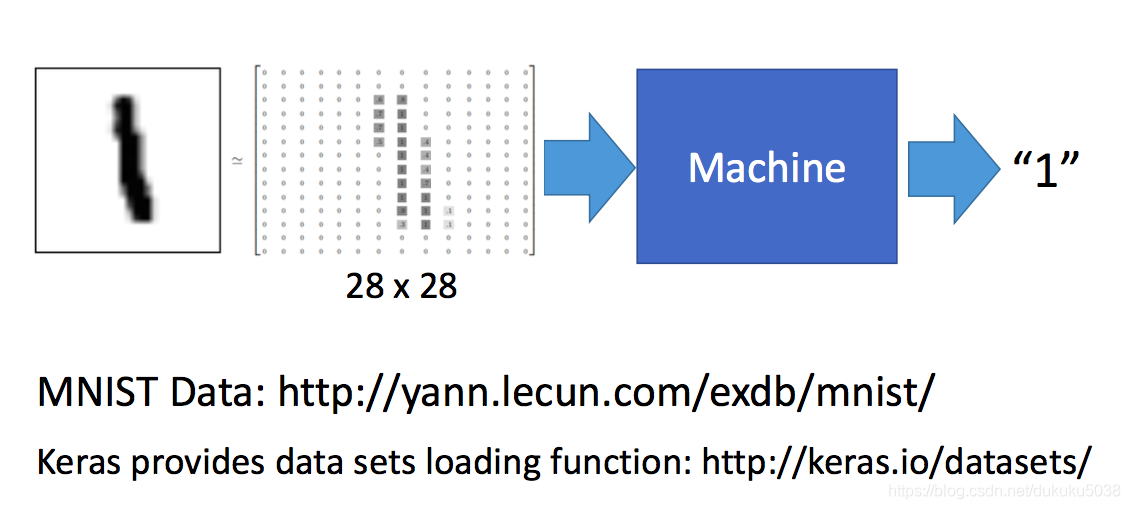
我們把架構和程式碼結合起來:
1.building network
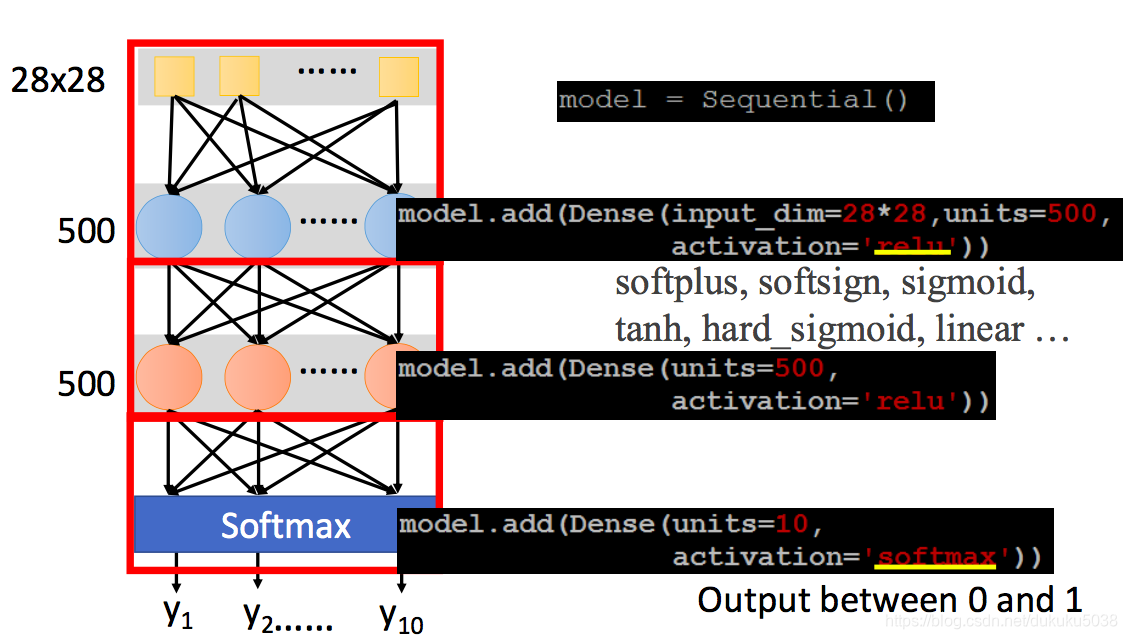
2. configuration

3. pick the best function
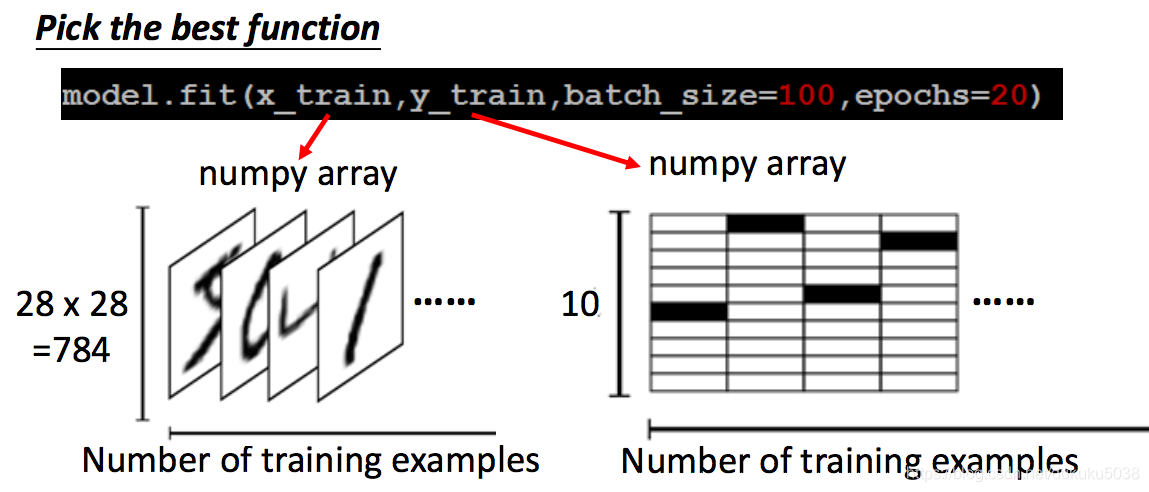
為了加快實驗:
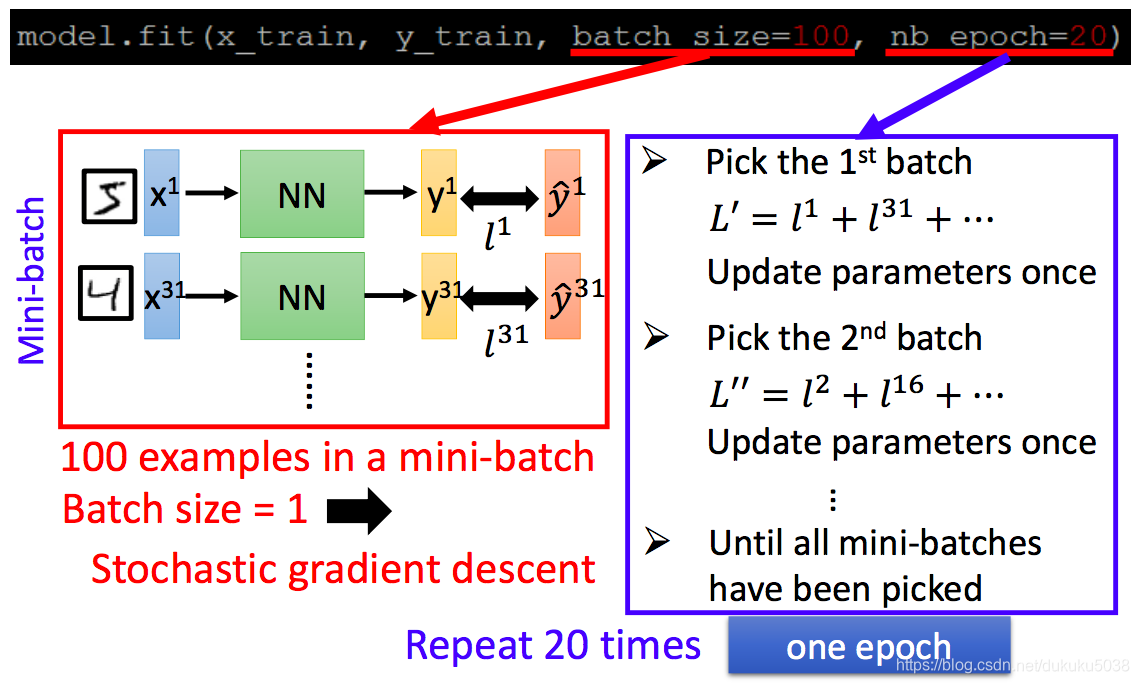
本專欄圖片、公式很多來自臺灣大學李弘毅老師、斯坦福大學cs229,斯坦福大學cs231n 、斯坦福大學cs224n課程。在這裡,感謝這些經典課程,向他們致敬!
相關推薦
機器學習與深度學習系列連載: 第二部分 深度學習(九)Keras- “hello world” of deep learning
Keras Kearas 是深度學習小白程式碼入門的最佳工具之一。 如果想提升、練習程式碼能力,還是建議演算法徒手python實現。 複雜的深度神經網路專案還是推薦TensorFlow或者Pytorch Keras是一個高層神經網路API,Keras由純Pyt
機器學習與深度學習系列連載: 第二部分 深度學習(二)梯度下降
梯度下降 Gradient Decent 我們回憶深度學習“三板斧”, 選擇神經網路 定義神經網路的好壞 選擇最好的引數集合 其中步驟三,如何選擇神經網路的好壞呢? 梯度下降是目前,最有效的方法之一。 方法:我們舉兩個引數的例子
機器學習與深度學習系列連載: 第二部分 深度學習(十六)迴圈神經網路 4(BiDirectional RNN, Highway network, Grid-LSTM)
深度學習(十六)迴圈神經網路 4(BiDirectional RNN, Highway network, Grid-LSTM) RNN處理時間序列資料的時候,不僅可以正序,也可以正序+逆序(雙向)。下面顯示的RNN模型,不僅僅是simple RNN,可以是LSTM,或者GRU 1 B
機器學習與深度學習系列連載: 第二部分 深度學習(十五)迴圈神經網路 3(Gated RNN - GRU)
迴圈神經網路 3(Gated RNN - GRU) LSTM 是1997年就提出來的模型,為了簡化LSTM的複雜度,在2014年 Cho et al. 提出了 Gated Recurrent Units (GRU)。接下來,我們在LSTM的基礎上,介紹一下GRU。 主要思路是: •
機器學習與深度學習系列連載: 第二部分 深度學習(十四)迴圈神經網路 2(Gated RNN - LSTM )
迴圈神經網路 2(Gated RNN - LSTM ) simple RNN 具有梯度消失或者梯度爆炸的特點,所以,在實際應用中,帶有門限的RNN模型變種(Gated RNN)起著至關重要的作用,下面我們來進行介紹: LSTM (Long Short-term Memory )
機器學習與深度學習系列連載: 第二部分 深度學習(十三)迴圈神經網路 1(Recurre Neural Network 基本概念 )
迴圈神經網路 1(Recurre Neural Network 基本概念 ) 迴圈神經網路的特點: • RNNs 在每個時間點連線引數值,引數只有一份 • 神經網路出了輸入以外,還會建立在以前的“記憶”的基礎上 • 記憶體的要求與輸入的規模有關 當然,他的深度不只有一層:
機器學習與深度學習系列連載: 第二部分 深度學習(十二)卷積神經網路 3 經典的模型(LeNet-5,AlexNet ,VGGNet,GoogLeNet,ResNet)
卷積神經網路 3 經典的模型 經典的卷積神經網路模型是我們學習CNN的利器,不光是學習原理、架構、而且經典模型的超引數、引數,都是我們做遷移學習最好的源材料之一。 1. LeNet-5 [LeCun et al., 1998] 我們還是從CNN之父,LeCun大神在98年提出的模
機器學習與深度學習系列連載: 第二部分 深度學習(十一)卷積神經網路 2 Why CNN for Image?
卷積神經網路 2 Why CNN 為什麼處理圖片要用CNN? 原因是: 一個神經元無法看到整張圖片 能夠聯絡到小的區域,並且引數更少 圖片壓縮畫素不改變圖片內容 1. CNN 的特點 卷積: 一些卷積核遠遠小於圖片大小; 同樣的pat
機器學習與深度學習系列連載: 第二部分 深度學習(十)卷積神經網路 1 Convolutional Neural Networks
卷積神經網路 Convolutional Neural Networks 卷積神經網路其實早在80年代,就被神經網路泰斗Lecun 提出[LeNet-5, LeCun 1980],但是由於當時的資料量、計算力等問題,沒有得到廣泛使用。 卷積神經網路的靈感來自50年代的諾貝爾生物學獎
機器學習與深度學習系列連載: 第二部分 深度學習(十八) Seq2Seq 模型
Seq2Seq 模型 Seq2Seq 模型是自然語言處理中的一個重要模型,當然,這個模型也可以處理圖片。 特點是: Encoder-Decoder 大框架 適用於語言模型、圖片模型、甚至是預測 1. RNN相關的生成應用: (1) 作詩 (2) 圖片生成
機器學習與深度學習系列連載: 第二部分 深度學習(七)深度學習技巧4(Deep learning tips- Dropout)
深度學習技巧4( Dropout) Dropout 在2012年imagenet 比賽中大放異彩,是當時CNN模型奪冠的功勳環節之一。 那什麼是Dropout 我們先直觀的理解: 練武功的時候,訓練的時候腳上綁上重物 等到練成下山的時候: 我們從幾個方面來解
機器學習與深度學習系列連載: 第二部分 深度學習(八)可以自己學習的啟用函式(Maxout)
可以自己學習的啟用函式(Maxout) 在深度學習中啟用函式有sigma, tanh, relu,還有以後會將到的selu,但是有沒有一個啟用函式不是人為設定的,是機器學出來的呢?對抗網路(GAN)之父Goodfellow,給我們一個肯定的答案。Learnabl
機器學習與深度學習系列連載: 第二部分 深度學習(十四)迴圈神經網路 2(Gated RNN
迴圈神經網路 2(Gated RNN - LSTM ) simple RNN 具有梯度消失或者梯度爆炸的特點,所以,在實際應用中,帶有門限的RNN模型變種(Gated RNN)起著至關重要的作用,下面我們來進行介紹: LSTM (Long Short-term
機器學習與深度學習系列連載: 第二部分 深度學習(十八) Seq2Seq 模型
Seq2Seq 模型 Seq2Seq 模型是自然語言處理中的一個重要模型,當然,這個模型也可以處理圖片。 特點是: Encoder-Decoder 大框架 適用於語言模型、圖片模型、甚至是預測 1. RNN相關的生成應用: (1) 作詩 (2) 圖片生成
機器學習與深度學習系列連載: 第二部分 深度學習(十九) 注意力機制 Attention
注意力機制 Attention 我們以機器翻譯為例,來探究引入注意力機制Attention: 當我們使用Seq2Seq 進行機器翻譯的過程中,最後的輸入對結果影響響度比較大,因為Encode的輸出是在尾部(圖中粉紅色部分)。直覺上想,一段話的翻譯的的過程中,輸
機器學習與深度學習系列連載: 第二部分 深度學習(六)深度學習技巧3(Deep learning tips- Early stopping and Regularization)
深度學習技巧3( Early stopping and Regularization) 本節我們一起探討 Early stopping and Regularization,這兩個技巧不是深度學習特有的方法,是機器學習通用的方法。 1. Early stopp
機器學習與深度學習系列連載: 第二部分 深度學習(二十一) Beam Search
Beam Search 由於在NLP中Vocabulary的量非常大,Test過程中選擇結果序列是一件非常頭疼的事情。 如果每一步都用最大概率去選擇不一定得到最好的而結果。 1. Beam Search演算法來源 我們還是以NLP產生字母為例: 請看下圖:
機器學習9:“Hello World” of deep learning
一、框架 1、TensorFlow或者theano比較靈活,可以理解成微分器,你可以用來實現Gradient Decent,但用起來實際上是有難度的; 2、keras其實是TensorFlow或theano的API介面,可以幫助你快速做一個模型,現在TensorFlow預設使用Keras介面
李巨集毅機器學習 P15 “Hello world” of deep learning 筆記
我們今天使用Keras來寫一個deep learning model。 tensorflow實際上是一個微分器,它的功能比較強大,但同時也不太好學。因此我們學Keras,相對容易,也有足夠的靈活性。 李教授開了一個玩笑: 下面我們來寫一個最簡單的deep learning mo
機器學習與深度學習系列連載: 第一部分 機器學習(五) 生成概率模型(Generative Model)
生成概率模型(Generative Model) 1.概率分佈 我們還是從分類問題說起: 當我們把問題問題看做是一個迴歸問題, 分類是class 1 的時候結果是1 分類為class 2的時候結果是-1; 測試的時候,結果接近1的是class1