
針對Jmeter編碼問題簡單普及一下字元編碼知識
對於Jmerter中需要使用中文字元時,我們一般用UTF-8編碼,而且對於CSV Data Set Config的中文引數化,我們要求用編輯器(Sublime、UltraEdit等)儲存為無BOM的UTF-8編碼格式的,這是為什麼呢?從下面的字元編碼介紹,就知道原因了:
1、美國人發明儲存英文的是ASCII碼,擴充套件到全世界使用就成了ANSI碼,中國人發明了GB2312碼(ASCII碼的中文擴充),繼續擴充套件後成了GBK碼(加了新漢字和繁體字),再擴充套件成了GB18030(加了少數民族的字)。
2、最後為了統一全球文字,發明了unicode(萬國碼),但是不方便傳輸和推廣(因為在計算機上區別不了unicode和ascii),接著就發明了UTF碼(unicode碼的網際網路化實現方式),其中UTF-8表示每次傳輸8位資料,UTF-16表示每次16位轉輸(比如漢字人名中的生僻字,用UTF-8不夠轉輸,就需要用UTF-16)。
所以ASCII、GB2312、GBK和GB18030是向下相容的,區分中文編碼的方法是高位元組的最高位不為0。unicode則只相容ASCII。
3、對於UTF-8我們就需要關注BOM頭了,許多文字編輯器中能看到這樣的格式區分
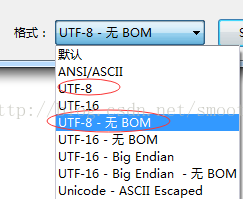
通常BOM是用來標示Unicode純文字位元組流的,用來提供一種方便的方法讓文字處理程式識別讀入的.txt檔案是哪個Unicode編碼(UTF-8,UTF-16BE,UTF-16LE),Windows程式相對對BOM處理比較好,開啟文字檔案時它會自動識別並剔除BOM。(吐槽:微軟對相容性的要求確實是到了非常偏執的地步,任何一點破壞相容性的做法都不允許,以至於很多時候是自己綁住自己的雙手),所以乾脆一步到位進入UTF-8。
BOM不受歡迎主要是在UNIX環境下(或是Java環境下的程式),因為很多UNIX程式不鳥BOM。主要問題出在UNIX那個所有指令碼語言通行的首行#!標示,這東西依賴於shell解析,而很多shell出於相容的考慮不檢測BOM,所以加進BOM時shell會把它解釋為某個普通字元輸入導致破壞#!標示,這就麻煩了。其實很多現代指令碼語言,比如Python,其直譯器本身都是能處理BOM的,但是shell卡在這裡,沒辦法,只能躺著也中槍。說起來這也不能怪shell,因為BOM本身違反了一個UNIX設計的常見原則,就是文件中存在的資料必須可見。BOM不能作為可見字元被文字編輯器編輯,就這一條很多UNIX開發者就不滿意。
最後引用網上的一些說明:為什麼bom頭會產生亂碼?
有bom頭的儲存或者位元組流,它一定是unicode字符集編碼。到底屬於那一種(utf-8還是utf-16或是utf-32),通過頭可以判斷出來。
由於已經說過utf-16,utf-32不指定bom頭,解析程式預設就認為是ansi編碼,出現亂碼。而utf-8指定或者不指定程式都可判斷知道對於的字符集編碼。
問題就出在這裡,可能有的應用程式(ie6瀏覽器),它就認為如果utf-8編碼,就不需要指定bom頭,它可以自己判斷,相反指定了bom頭,它還會出現問題
(因為它把頭當utf-8解析出現亂碼了)。眾多技術部落格裡談這個比較多,目前ie6會出現問題。其它ie7+,firefox,chrome不會出現,會忽略掉bom頭。
統一解決辦法是:存為utf-8編碼是,不需要加入bom頭,其它utf-16,utf-32加入。