
機器學習7:SVM(支援向量機)
支援向量機
優化目標
-
對於邏輯迴歸的假設函式而言,在y=1的情況下,我們希望假設函式約等於1,且z遠大於0;在y=0的情況下,我們希望假設函式約等於0,且z遠小於0。
-
對於支援向量機,則希望在y=1的情況下,z大於等於0,;在y=0的情況下,z取其他值(小於0)
-
對於邏輯迴歸的代價函式,其中的 替代為 ,這兩個函式的圖如下:
其中的 替代為 ,這兩個函式的圖如下:
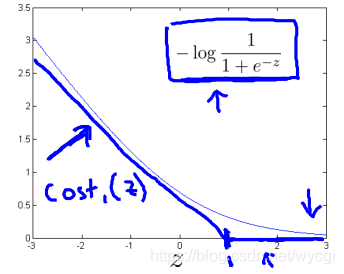
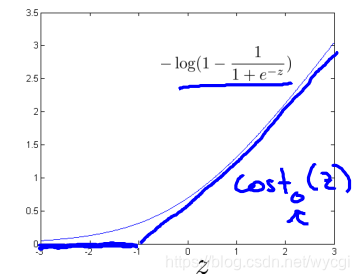
也就是說,在y=1的情況下,目標函式需要z大於等於1;在y=0的情況下,目標函式需要z小於等於-1。
- 對於支援向量機的代價函式而言,如上所述替代後,再去掉m項,將
用C代替(
),如下所示:
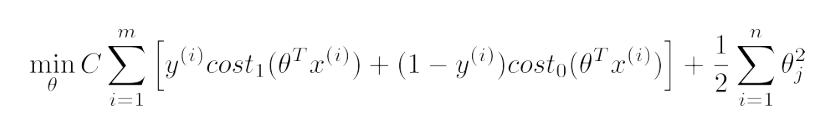
大間距分類器
如上所述,在y=1的情況下,目標函式需要z大於等於1;在y=0的情況下,目標函式需要z小於等於-1。
也就是說,對於決策邊界(z=0)而言,與訓練樣本的距離儘量保持在1以上,因此會糾正過擬合的問題,取分類兩組資料的中間,與雙方保持一定距離的線為邊界,如下方的margin(圓圈和紅叉表示兩種型別的樣本):

但是如果C取值過大,也即
的值過小,即便採用上述演算法還是會容易過擬合,如下:

數學原理
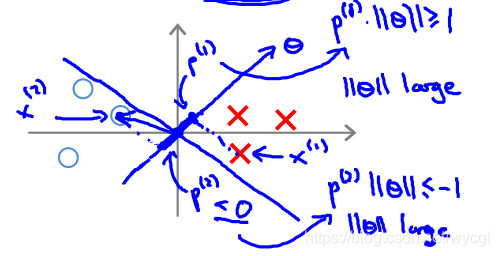
目標函式中,有該項 ,也即等同於求向量 的長度平方的二分之一: 。
因此,在決定決策邊界時,如果如下圖所示(
,相當於兩個向量的內積):
由於上圖所示,樣本
投影到向量
(注意的是,向量
與決策邊界垂直,因為與決策邊界的內積z為0)上的值p較小,而為了與p值相乘大於等於1或小於等於-1,就會導致
的值較大,不符合目標函式的預期。
如果如下圖所示:
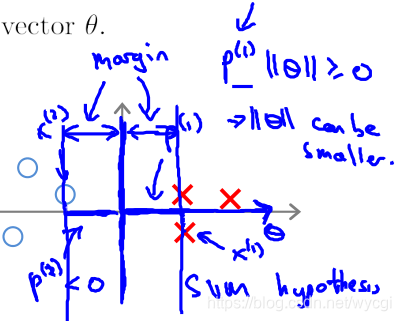
那麼,樣本投影到向量 上得到的值p較大,同理,可知,能使 的值較小,符合目標函式的預期。
核函式一
對於非線性邊界如下圖所示的,在邏輯迴歸中通常採用多項式構造特徵:
而如果採用支援向量機這一演算法,那就要將
替代為
。
的定義如下:
其中的
為輸入特徵,
為下圖中的點(可表示為長度為特徵數目n的向量):
的性質有:如果
,則
;如果如果
與
相差過大,則
。

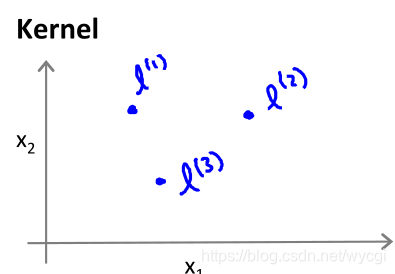
中的
過小時,容易低偏差,高方差,過大時容易高偏差,低方差,當
時,
的影象如下:
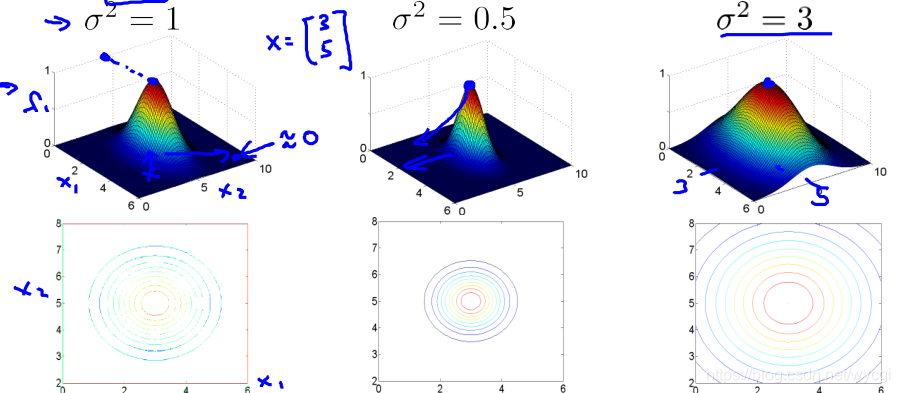
當