
機器學習——Bagging與隨機森林演算法及其變種
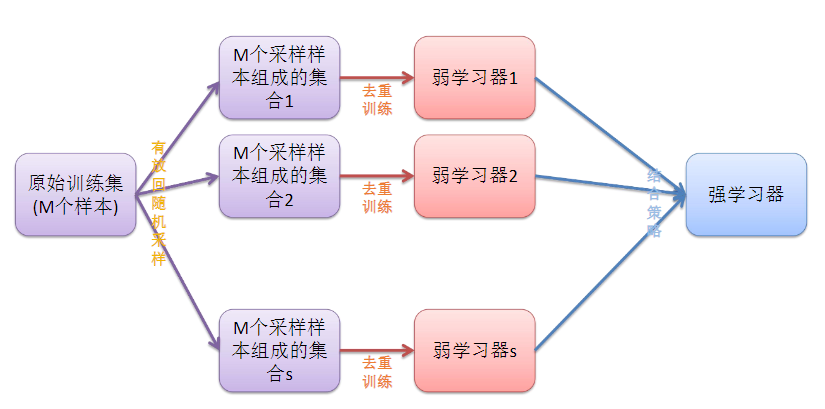
隨機森林演算法:
一般用於大規模資料,百萬級以上的。
在Bagging演算法的基礎上,如上面的解釋,在去重後得到三組資料,那麼再隨機抽取三個特徵屬性,選擇最佳分割屬性作為節點來建立決策樹。可以說是
隨機森林=決策樹+Bagging 如下圖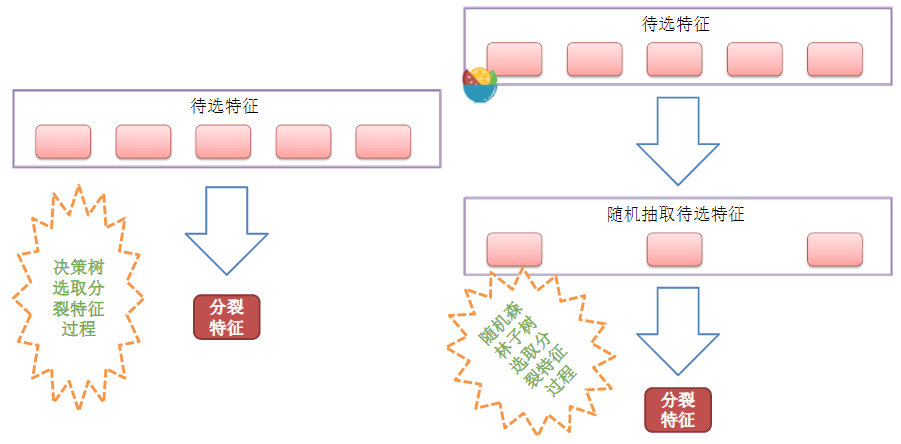
RF(隨機森林)的變種:
ExtraTree演算法
凡解:和隨機森林的原理基本一樣。主要差別點如下
①隨機森林是在含有m個數據的原資料集上有放回的抽取m個數據,而ExtraTree演算法是直接用原資料集訓練。
②隨機森林在選擇劃分特徵點的時候會和傳統決策樹一樣,會基於資訊增益、資訊增益率、基尼係數、均方差等原則來選擇最優特徵值;而ExtraTree會隨機的選擇一個特徵值來劃分決策樹。
TRTE演算法
不重要,瞭解一下即可
官解:TRTE是一種非監督的資料轉化方式。對特徵屬性重新編碼,將低維的資料集對映到高維,從而讓對映到高維的資料更好的應用於分類迴歸模型。
劃分標準為方差
看例子吧直接:

IForest
IForest是一種異常點檢測演算法,使用類似RF的方式來檢測異常點
此演算法比較坑,適應性不強。
1.在隨機取樣的過程中,一般只需要少量資料即可;
•2.在進行決策樹構建過程中,IForest演算法會隨機選擇一個劃分特徵,並對劃分特徵隨機選擇一個劃分閾值;
•3.IForest演算法構建的決策樹一般深度max_depth是比較小的。
此演算法可以用,但此演算法連創作者本人也無法完整的解釋原理。
RF(隨機森林)的主要優點:
●1.訓練可以並行化,對於大規模樣本的訓練具有速度的優勢;
●2.由於進行隨機選擇決策樹劃分特徵列表,這樣在樣本維度比較高的時候,仍然具有比較高的訓練效能;
●3.可以給出各個特徵的重要性列表;
●4.由於存在隨機抽樣,訓練出來的模型方差小,泛化能力強;
●5. RF實現簡單;
●6.對於部分特徵的缺失不敏感。
RF的主要缺點:
●1.在某些噪音比較大的特徵上(資料特別異常情況),RF模型容易陷入過擬合;
●2.取值比較多的劃分特徵對RF的決策會產生更大的影響,從而有可能影響模型的
效果。
