
Spark學習(肆)- 從Hive平滑過渡到Spark SQL
文章目錄
- SQLContext的使用
- HiveContext的使用
- SparkSession的使用
- spark-shell&spark-sql的使用
- thriftserver&beeline的使用
- jdbc方式程式設計訪問
SQLContext的使用
Spark1.x中Spark SQL的入口點: SQLContext
val sc: SparkContext // An existing SparkContext.
val sqlContext = 建立一個scala maven專案
SQLContext測試:
新增相關pom依賴
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.0</spark.version>
</ 測試資料:
{“name”: “zhangsan”, “age”:30}
{"name ": “Michael”}
{“name” : “Andy”, “age”:30}
{“name” : “Justin”, “age” :19}
package com.imooc.spark
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.SparkConf
/**
* SQLContext的使用:
* 注意:IDEA是在本地,而測試資料是在伺服器上 ,能不能在本地進行開發測試的?
*
*/
object SQLContextApp {
def main(args: Array[String]) {
val path = args(0)
//1)建立相應的Context
val sparkConf = new SparkConf()
//在測試叢集或者生產叢集中,AppName和Master我們是通過指令碼進行指定
//sparkConf.setAppName("SQLContextApp").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
//2)相關的處理: json
val people = sqlContext.read.format("json").load(path)
people.printSchema()
people.show()
//3)關閉資源
sc.stop()
}
}
本地測試:
列印結果是一個表結構
| age | name |
|---|---|
| 30 | zhangsan |
| null | Michaeti |
| 30 | Andy |
| 19 | Justin |
叢集測試:
1)編譯:mvn clean package -DskipTests
2)上傳到叢集
提交Spark Application到環境中執行
spark-submit
–name SQLContextApp
–class com.kun.sparksql.SQLContextApp
–master local[2]
/home/hadoop/lib/sql-1.0.jar
/home/hadoop/app/spark-2.1.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json
結果同上本地測試結果
HiveContext的使用
Spark1.x中Spark SQL的入口點: HiveContext
要使用HiveContext,只需要有一個hive-site.xml
將Hive的配置檔案hive-site.xml拷貝到${spark_home}/conf目錄下
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
新增maven依賴
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
測試:
package com.kun.sparksql
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* HiveContext的使用 (展示hive裡emp表的內容)
* 使用時需要通過--jars 把mysql的驅動傳遞到classpath
*/
object HiveContextApp {
def main(args: Array[String]) {
//1)建立相應的Context
val sparkConf = new SparkConf()
//在測試或者生產中,AppName和Master我們是通過指令碼進行指定
//sparkConf.setAppName("HiveContextApp").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
//2)相關的處理:
hiveContext.table("emp").show
//3)關閉資源
sc.stop()
}
}
本地測試和叢集測試步驟同SQLContext的使用雷同
提交Spark Application到環境中執行
spark-submit
–name HiveContextApp
–class com.kun.sparksql.HiveContextApp
–master local[2]
/home/hadoop/lib/sql-1.0.jar
–jar /mysql驅動包路徑
SparkSession的使用
Spark2.x中Spark SQL的入口點: SparkSession
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
測試:
package com.kun.sparksql
import org.apache.spark.sql.SparkSession
/**
* SparkSession的使用
*/
object SparkSessionApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkSessionApp")
.master("local[2]").getOrCreate()
val people = spark.read.json("file:///Users/rocky/data/people.json")
people.show()
spark.stop()
}
}
spark-shell&spark-sql的使用
檢查程序:

spark-shell
進入hive裡:
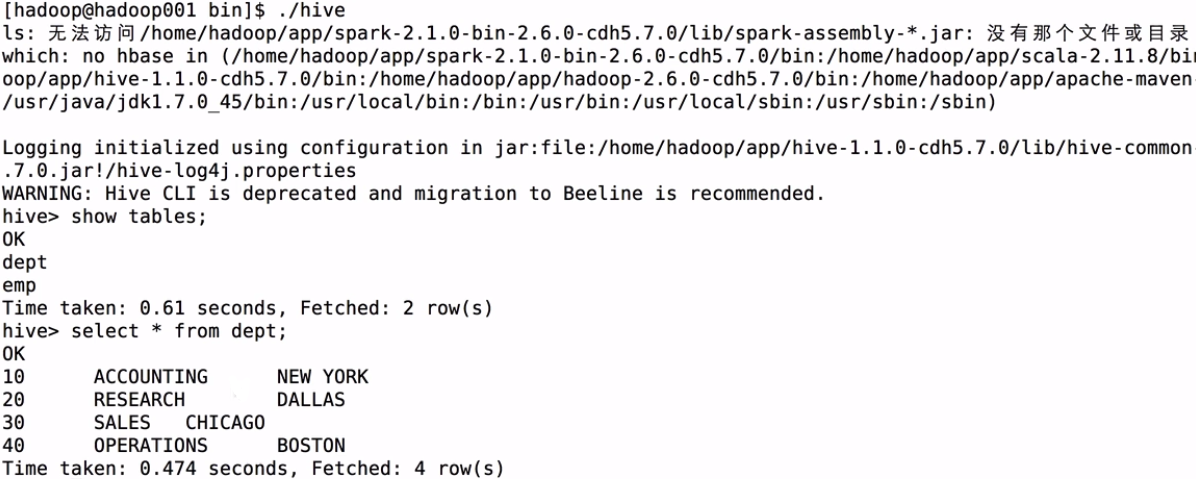
使用 spark-shell --master local[2] 命令來啟動spark-shell
沒有配置hive-site.xml前spark裡是空表
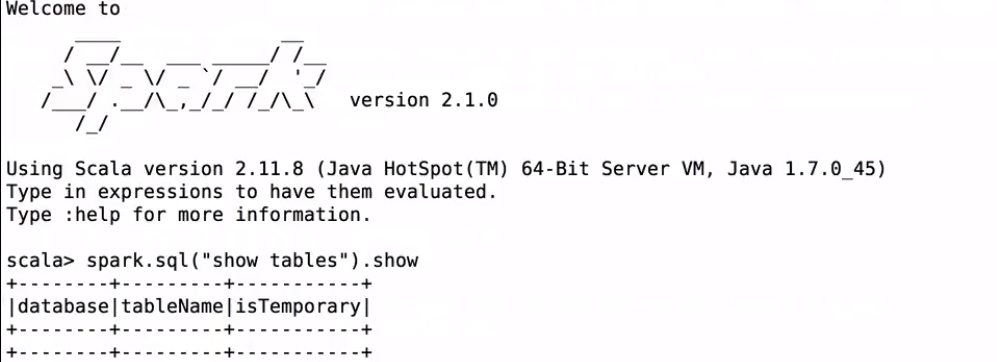
將Hive的配置檔案hive-site.xml拷貝到${spark_home}/conf目錄下;重新啟動spark-shell,啟動時需要通過–jars 把mysql的驅動傳遞到classpath
檢視hive裡的表:
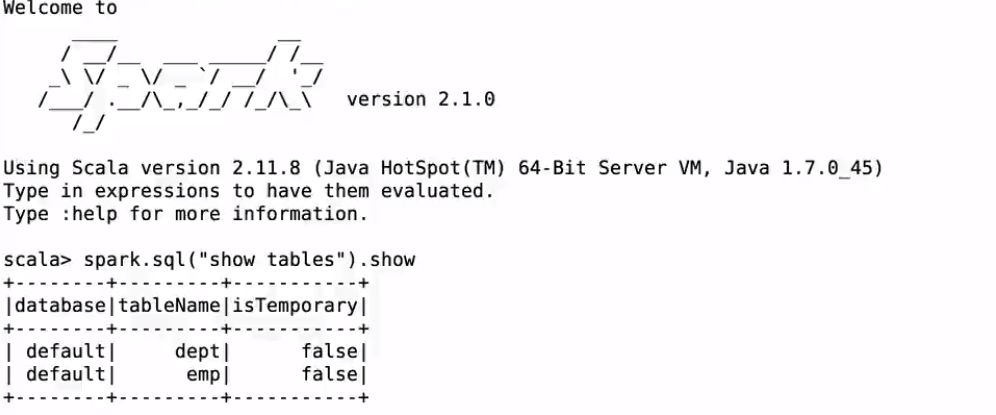
訪問dept表:
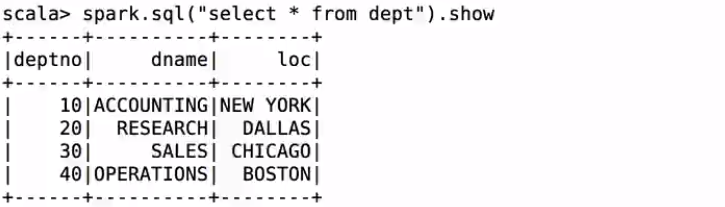
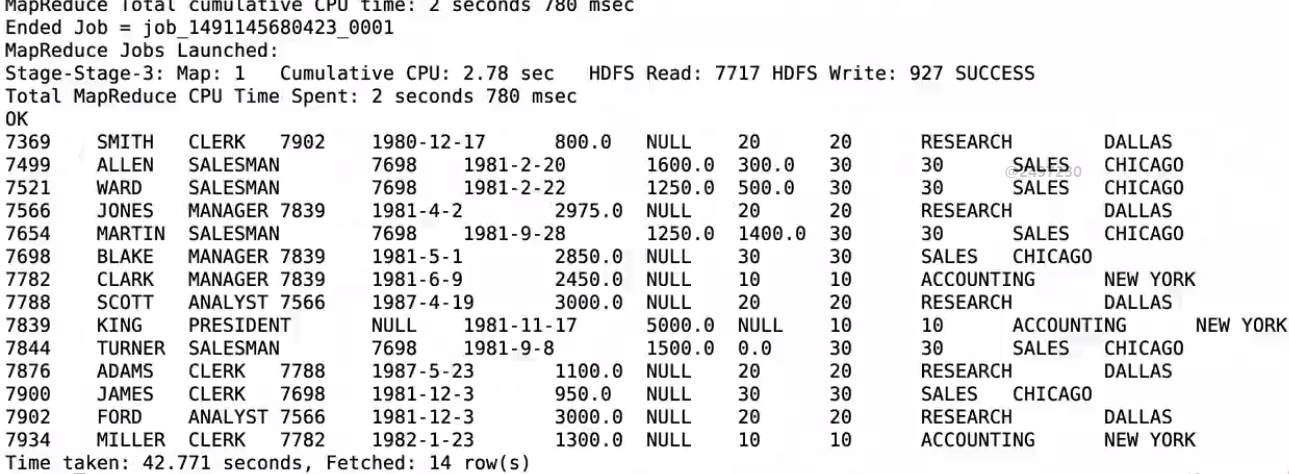
使用相同的查詢語句;hive會進入mr作業;spark會直接出資料

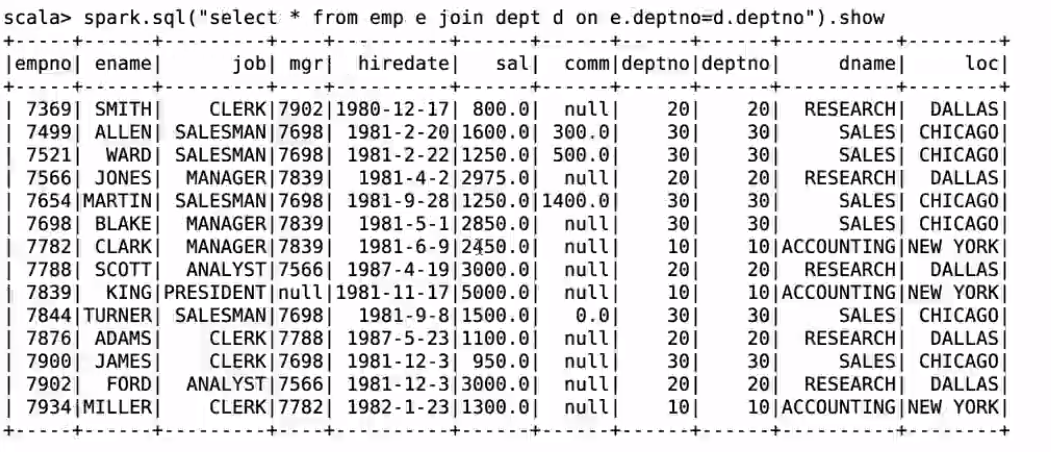
spark-sql
啟動sparksql
執行一條查詢語句:
select * form emp;
此時重新整理spark ui頁面會有作業job輸出
檢視spark sql執行計劃(sql語句是任意寫的;只是為了檢視執行計劃)
create table t(key string, value string);
explain extended select a.key*(2+3), b.value from t a join t b on a.key = b.key and a.key > 3;
執行計劃:
== Parsed Logical Plan ==
'Project [unresolvedalias(('a.key * (2 + 3)), None), 'b.value]
+- 'Join Inner, (('a.key = 'b.key) && ('a.key > 3))
:- 'UnresolvedRelation `t`, a
+- 'UnresolvedRelation `t`, b
== Analyzed Logical Plan ==
(CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE)): double, value: string
Project [(cast(key#321 as double) * cast((2 + 3) as double)) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#325, value#324]
+- Join Inner, ((key#321 = key#323) && (cast(key#321 as double) > cast(3 as double)))
:- SubqueryAlias a
: +- MetastoreRelation default, t
+- SubqueryAlias b
+- MetastoreRelation default, t
== Optimized Logical Plan ==
Project [(cast(key#321 as double) * 5.0) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#325, value#324]
+- Join Inner, (key#321 = key#323)
:- Project [key#321]
: +- Filter (isnotnull(key#321) && (cast(key#321 as double) > 3.0))
: +- MetastoreRelation default, t
+- Filter (isnotnull(key#323) && (cast(key#323 as double) > 3.0))
+- MetastoreRelation default, t
== Physical Plan ==
*Project [(cast(key#321 as double) * 5.0) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#325, value#324]
+- *SortMergeJoin [key#321], [key#323], Inner
:- *Sort [key#321 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#321, 200)
: +- *Filter (isnotnull(key#321) && (cast(key#321 as double) > 3.0))
: +- HiveTableScan [key#321], MetastoreRelation default, t
+- *Sort [key#323 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(key#323, 200)
+- *Filter (isnotnull(key#323) && (cast(key#323 as double) > 3.0))
+- HiveTableScan [key#323, value#324], MetastoreRelation default, t
thriftserver&beeline的使用
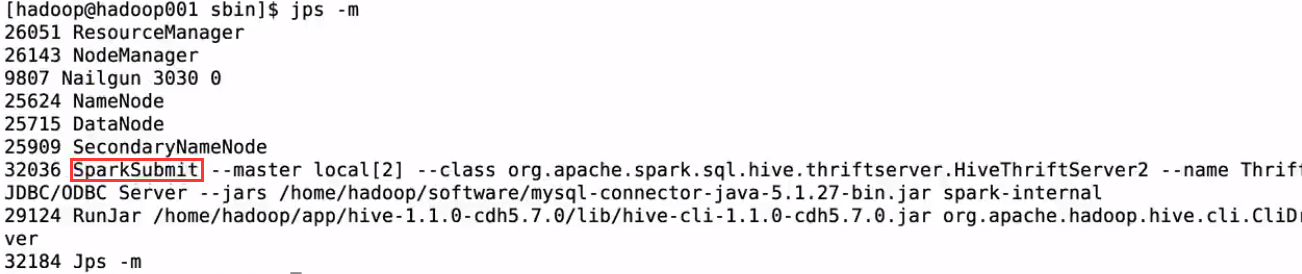
進入${Spark_home}/sbin下面;啟動thriftserver:
start-thriftserver.sh --master local[2] --jars mysql驅動包路徑
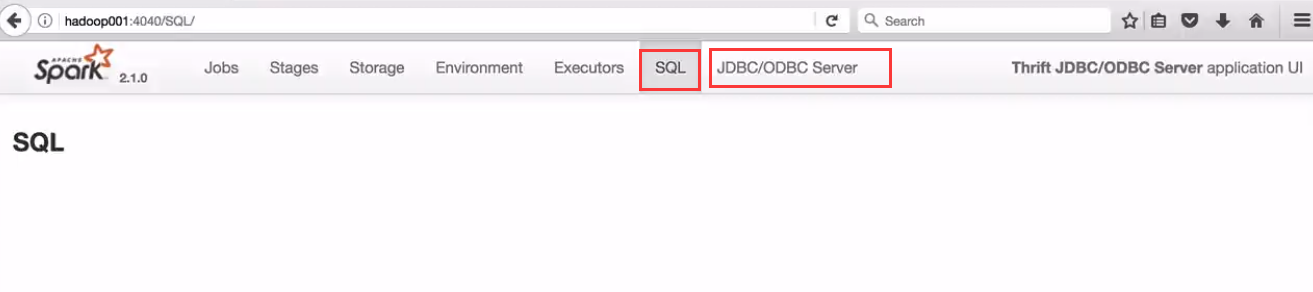
檢視是否啟動完成
- 啟動thriftserver: 預設埠是10000 ,可以修改
修改thriftserver啟動佔用的預設埠號:
./start-thriftserver.sh
–master local[2]
–jars ~/software/mysql-connector-java-5.1.27-bin.jar
–hiveconf hive.server2.thrift.port=14000
啟動thriftserver後;beeline的對應埠也要修改
beeline -u jdbc:hive2://localhost:14000 -n hadoop
2)啟動beeline(${spark_home}/bin/beeline)(可以啟動多個beenline客戶端)
beeline -u jdbc:hive2://localhost:10000 -n hadoop

執行的sql可以在介面JDBC/ODBC Server介面檢視
thriftserver和普通的spark-shell/spark-sql有什麼區別?
1)spark-shell、spark-sql都是一個spark application;
2)thriftserver, 不管你啟動多少個客戶端(beeline/code),永遠都是一個spark application
解決了一個數據共享的問題,多個客戶端可以共享資料;
jdbc方式程式設計訪問
注意事項:在使用jdbc開發時,一定要先啟動thriftserver
Exception in thread “main” java.sql.SQLException:
Could not open client transport with JDBC Uri: jdbc:hive2://hadoop001:14000:
java.net.ConnectException: Connection refused
新增maven依賴
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version>
</dependency>
package com.kun.sparksql
import java.sql.DriverManager
/**
* 通過JDBC的方式訪問
*/
object SparkSQLThriftServerApp {
def main(args: Array[String]) {
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://hadoop001:14000","hadoop","")
val pstmt = conn.prepareStatement("select empno, ename, sal from emp")
val rs = pstmt.executeQuery()
while (rs.next()) {
println("empno:" + rs.getInt("empno") +
" , ename:" + rs.getString("ename") +
" , sal:" + rs.getDouble("sal"))
}
rs.close()
pstmt.close()
conn.close()
}
}