
Spark學習(伍)- DateFrame&Dataset
文章目錄
DataFrame產生背景
DataFrame它不是Spark SQL提出的,而是早起在R、Pandas語言就已經有了的。
- Spark RDD API vs MapReduce API Threshold
使用spark和mr開發需要學習對應語言scala和java等;門檻較高 - R/Pandas one machine
這些語言僅僅支援單機處理
sparksql裡的DataFrame誕生易於R和Pandas的人無縫對接;降低了很多人的門檻
DataFrame概述
- A distributed collection of rows organized into named columns(將行組織命名為列的分散式集合)(RDD with schema)
- 它在概念上等價於關係資料庫中的表或R/Python中的data frame,但是具有更豐富的優化
- 用於選擇、篩選、聚合和繪製結構化資料的抽象
- 受到R和panda單機小資料處理應用於分散式大資料的啟發
- 以前叫做SchemaRDD (Spark < 1.3)
A Dataset is a distributed collection of data:分散式的資料集
A DataFrame is a Dataset organized into named columns.
以列(列名、列的型別、列值)的形式構成的分散式資料集,按照列賦予不同的名稱;比如:
student
id:int
name:string
city:string
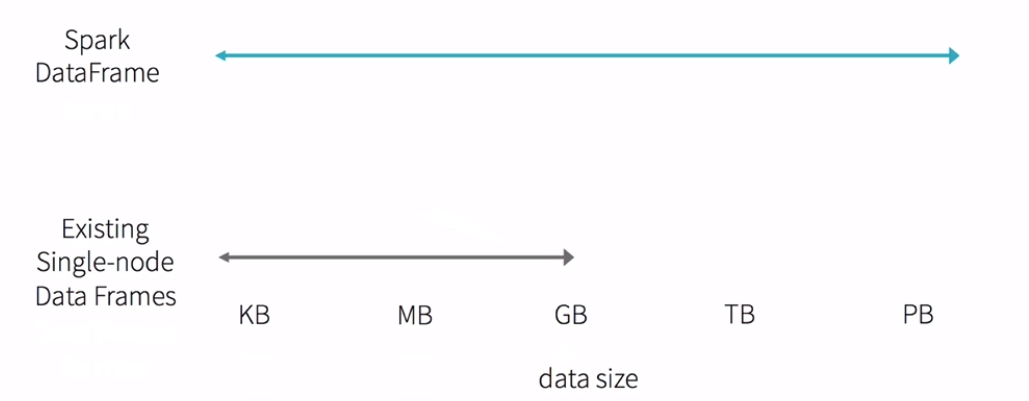
DataFrame和RDD的對比
RDD是Spark的核心
RDD彈性的分散式資料集五大特性
- 他有一系列的Partition組成的
- 每一個運算元作用在每一個partition上
- rdd之間是有依賴關係的
- 可選項:分割槽器作用在KV格式的RDD上 (1)分割槽器是在shuffle階段起作用(2) GroupByKey, reduceBykey, join, sortByKey等這些運算元會產生shuffle(3)這些運算元必須作用在KV格式的RDD
- RDD會提供一系列最佳計算位置,說白了就是暴露每一個partitior的位置這是資料本地化的基礎
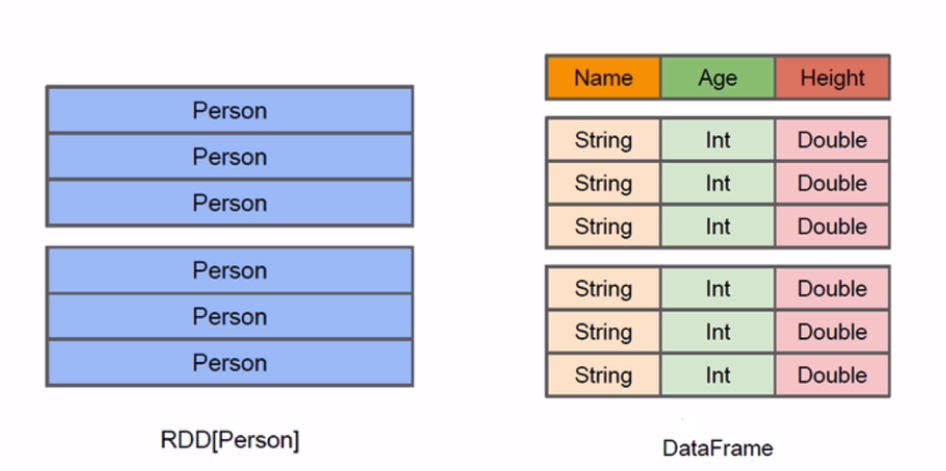
RDD:
java/scala ==> jvm
python ==> python runtime
DataFrame:
java/scala/python ==> Logic Plan
DataFrame基本API操作
Create DataFame
printSchema
show
select
filter
package com.kun.dataframe
import org.apache.spark.sql.SparkSession
/**
* DataFrame API基本操作
*/
object DataFrameApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("DataFrameApp").master("local[2]").getOrCreate()
// 將json檔案載入成一個dataframe
val peopleDF = spark.read.format("json").load("file:///Users/rocky/data/people.json")
// 輸出dataframe對應的schema資訊
peopleDF.printSchema()
// 輸出資料集的前20條記錄
peopleDF.show()
//查詢某列所有的資料: select name from table
peopleDF.select("name").show()
// 查詢某幾列所有的資料,並對列進行計算: select name, age+10 as age2 from table
peopleDF.select(peopleDF.col("name"), (peopleDF.col("age") + 10).as("age2")).show()
//根據某一列的值進行過濾: select * from table where age>19
peopleDF.filter(peopleDF.col("age") > 19).show()
//根據某一列進行分組,然後再進行聚合操作: select age,count(1) from table group by age
peopleDF.groupBy("age").count().show()
spark.stop()
}
}
DataFrame與RDD互操作方式
Spark SQL支援兩種不同的方法將現有的rdd轉換為資料集。第一種方法使用反射來推斷包含特定型別物件的RDD的模式。這種基於反射的方法可以生成更簡潔的程式碼,並且當您在編寫Spark應用程式時已經瞭解模式時,這種方法可以很好地工作。
建立資料集的第二種方法是通過程式設計介面,該介面允許您構建模式,然後將其應用於現有的RDD。雖然這個方法比較冗長,但它允許在直到執行時才知道列及其型別時構造資料集。
測試檔案infos.txt
1,zhangsan,20
2,lisi,30
3,wangwu,40
package com.kun.dataframe
import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* DataFrame和RDD的互操作
*/
object DataFrameRDDApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("DataFrameRDDApp").master("local[2]").getOrCreate()
//inferReflection(spark)
program(spark)
spark.stop()
}
def program(spark: SparkSession): Unit = {//通過程式設計介面
// RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/rocky/data/infos.txt")
val infoRDD = rdd.map(_.split(",")).map(line => Row(line(0).toInt, line(1), line(2).toInt))
val structType = StructType(Array(StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)))
val infoDF = spark.createDataFrame(infoRDD,structType)
infoDF.printSchema()
infoDF.show()
//通過df的api進行操作
infoDF.filter(infoDF.col("age") > 30).show
//通過sql的方式進行操作
infoDF.createOrReplaceTempView("infos")
spark.sql("select * from infos where age > 30").show()
}
def inferReflection(spark: SparkSession) {//(第一種方式使用反射)
// RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/rocky/data/infos.txt")
//注意:需要匯入隱式轉換
import spark.implicits._
val infoDF = rdd.map(_.split(",")).map(line => Info(line(0).toInt, line(1), line(2).toInt)).toDF()
infoDF.show()
infoDF.filter(infoDF.col("age") > 30).show
infoDF.createOrReplaceTempView("infos")
spark.sql("select * from infos where age > 30").show()
}
case class Info(id: Int, name: String, age: Int)
}
DataFrame和RDD互操作的兩種方式:
1)反射:case class 前提:事先需要知道你的欄位、欄位型別
2)程式設計:Row 如果第一種情況不能滿足你的要求(事先不知道列)
3) 選型:優先考慮第一種
DataFrame API操作案例實戰
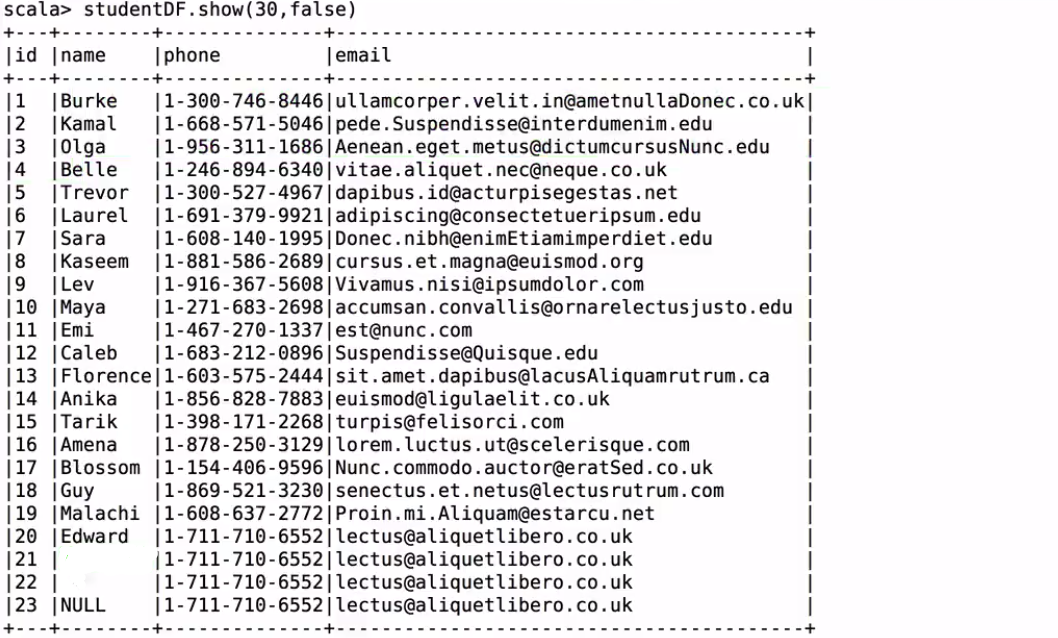
student.data檔案:
1|Burke|1-300-746-8446|[email protected]
2|Kamal|1-668-571-5046|[email protected]
3|Olga|1-956-311-1686|[email protected]
4|Belle|1-246-894-6340|[email protected]
5|Trevor|1-300-527-4967|[email protected]
6|Laurel|1-691-379-9921|[email protected]
7|Sara|1-608-140-1995|[email protected]
8|Kaseem|1-881-586-2689|[email protected]
9|Lev|1-916-367-5608|[email protected]
10|Maya|1-271-683-2698|[email protected]
11|Emi|1-467-270-1337|[email protected]
12|Caleb|1-683-212-0896|[email protected]
13|Florence|1-603-575-2444|[email protected]
14|Anika|1-856-828-7883|[email protected]
15|Tarik|1-398-171-2268|[email protected]
16|Amena|1-878-250-3129|[email protected]
17|Blossom|1-154-406-9596|[email protected]
18|Guy|1-869-521-3230|[email protected]
19|Malachi|1-608-637-2772|[email protected]
20|Edward|1-711-710-6552|[email protected]
21||1-711-710-6552|[email protected]
22||1-711-710-6552|[email protected]
23|NULL|1-711-710-6552|[email protected]
package com.kun.dataframe
import org.apache.spark.sql.SparkSession
/**
* DataFrame中的其他操作
*/
object DataFrameCase {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("DataFrameRDDApp").master("local[2]").getOrCreate()
// RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/rocky/data/student.data")
//注意:需要匯入隱式轉換
import spark.implicits._
val studentDF = rdd.map(_.split("\\|")).map(line => Student(line(0).toInt, line(1), line(2), line(3))).toDF()
//show預設只顯示前20條
studentDF.show
studentDF.show(30)
studentDF.show(30, false)
studentDF.take(10)
studentDF.first()
studentDF.head(3)
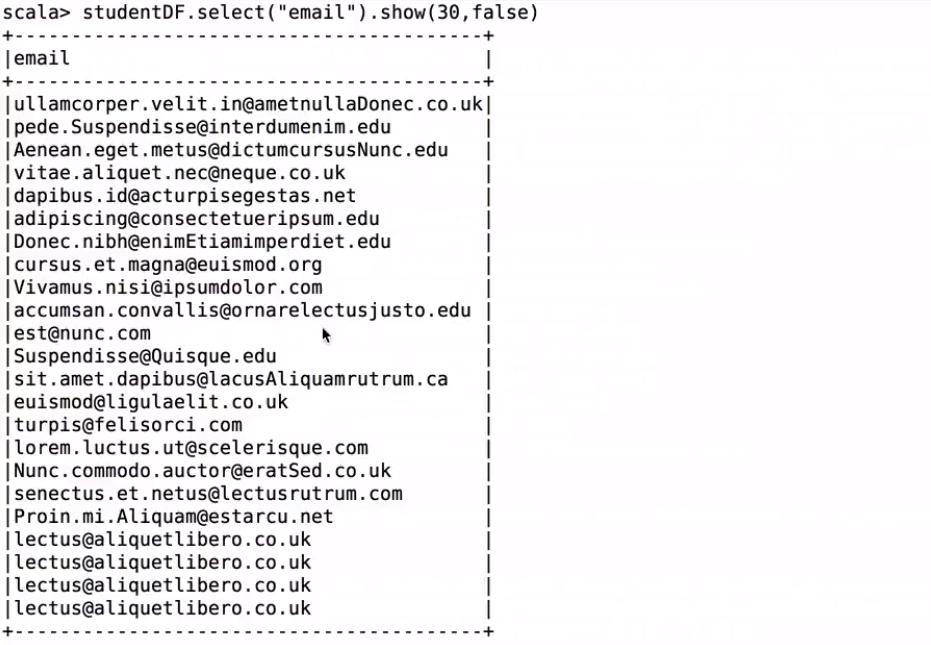
studentDF.select("email").show(30,false)
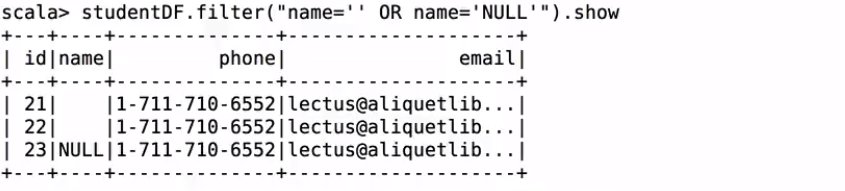
studentDF.filter("name=''").show
studentDF.filter("name='' OR name='NULL'").show
//name以M開頭的人
studentDF.filter("SUBSTR(name,0,1)='M'").show
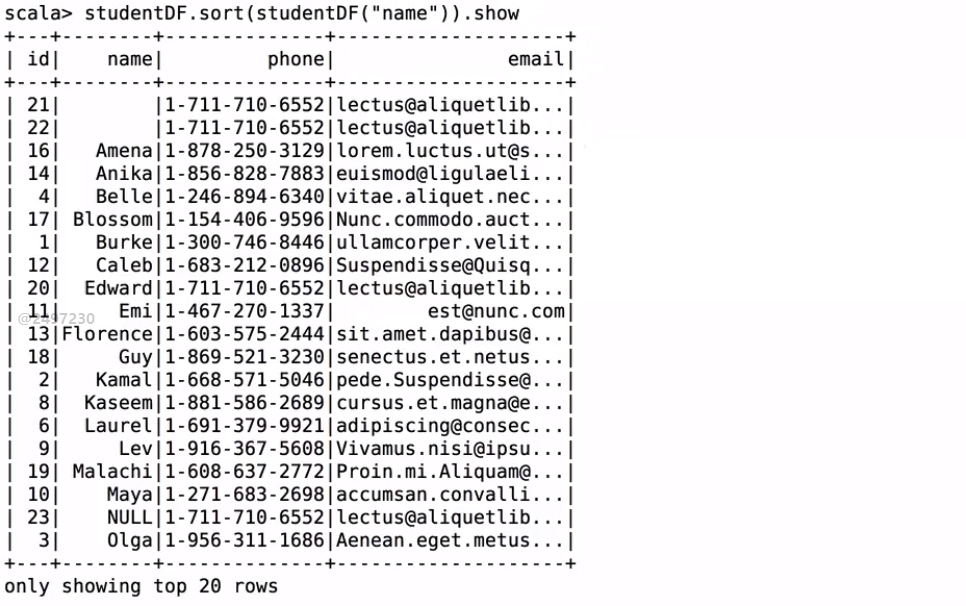
studentDF.sort(studentDF("name")).show
studentDF.sort(studentDF("name").desc).show
studentDF.sort("name","id").show
studentDF.sort(studentDF("name").asc, studentDF("id").desc).show
studentDF.select(studentDF("name").as("student_name")).show
val studentDF2 = rdd.map(_.split("\\|")).map(line => Student(line(0).toInt, line(1), line(2), line(3))).toDF()
studentDF.join(studentDF2, studentDF.col("id") === studentDF2.col("id")).show
spark.stop()
}
case class Student(id: Int, name: String, phone: String, email: String)
}
同樣可以在spark-shell裡測試;速度比idea裡要快
show()
take取幾個
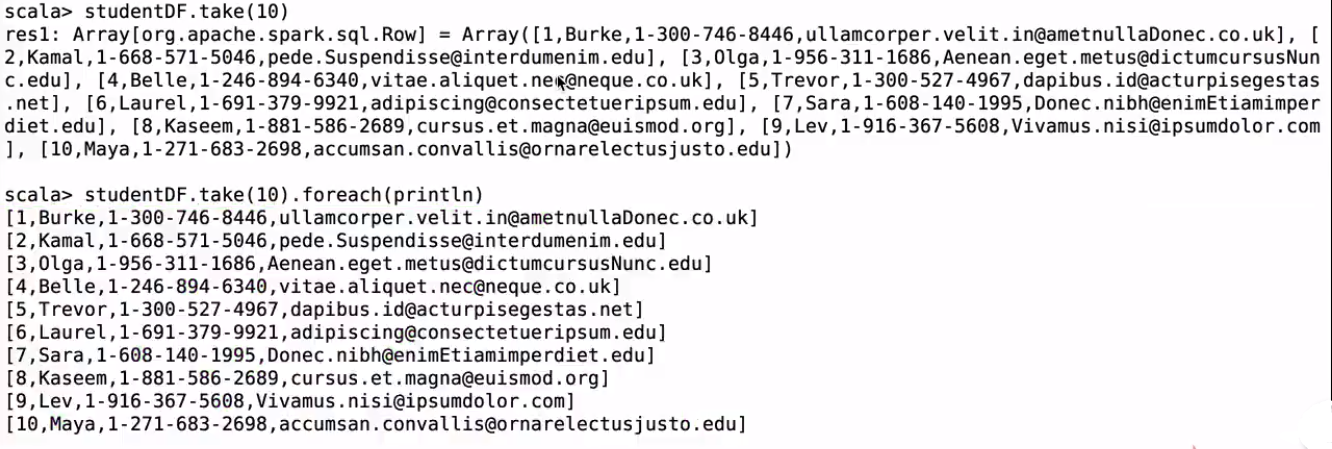
first取第一個;head取前幾個

檢視email 30個
filter過濾name=“”的

filter過濾name=“”和name=null的
filter過濾名字開頭為M的

檢視函式:

filter過濾名字開頭為M的

排序
降序排
按照name和id排序
按照name升序和id降序排序
更改name為student_name
進行jion操作注意是三個=號

DataSet概述及使用
DataSet是資料的分散式集合。Dataset是Spark 1.6中新增的一個新介面,它提供了RDDs(強型別、使用強大lambda函式的能力)和Spark SQL優化執行引擎的優點。可以從JVM物件構造資料集,然後使用功能轉換(對映、平面對映、篩選器等)操作資料集。資料集API在Scala和Java中可用。Python不支援資料集API。但是由於Python的動態特性,資料集API的許多優點已經可用(例如,您可以通過行名自然地訪問行. columnname的欄位)。R的情況類似。
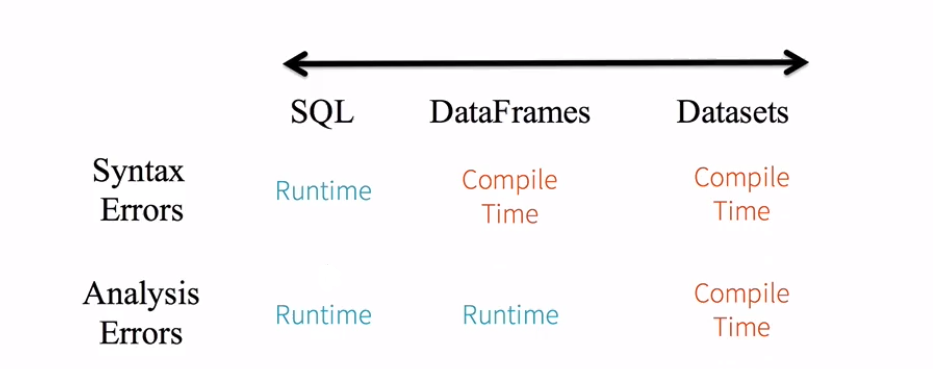
靜態型別(Static-typing)和執行時型別安全(runtime type-safety)
DataFrame = Dataset[Row]
Dataset:強型別 typed case class
DataFrame:弱型別 Row
SQL:
seletc name from person; compile ok, result no
錯誤sql語句編譯的時候是發現不問題的;ok的;但是執行的時候可以發現是有問題的。
DF:
df.seletc(“name”) compile no
錯誤的dateframe方法,編譯的時候就有問題的。
df.select(“nname”) compile ok
錯誤的dateframe列名;編譯的時候是發現不了的,執行的時候是有問題的。
DS:
ds.map(line => line.itemid) compile no
錯誤的dateset列名和方法名;編譯的時候是可以發現的。
package com.kun.dataframe
import org.apache.spark.sql.SparkSession
/**
* Dataset操作
*/
object DatasetApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("DatasetApp")
.master("local[2]").getOrCreate()
//注意:需要匯入隱式轉換
import spark.implicits._
val path = "file:///Users/rocky/data/sales.csv"
//spark如何解析csv檔案?
val df = spark.read.option("header","true").option("inferSchema","true").csv(path)
df.show
//dateframe轉換為dataset
val ds = df.as[Sales]
ds.map(line => line.itemId).show
spark.sql("seletc name from person").show
//df.seletc("name")
df.select("nname")
ds.map(line => line.itemId)
spark.stop()
}
case class Sales(transactionId:Int,customerId:Int,itemId:Int,amountPaid:Double)
}