
Elastic Stack-Elasticsearch使用介紹(二)
一、前言
寫部落格,更要努力寫部落格!
二、Mapping介紹
Mapping類似於資料庫中的表結構的定義:這裡我們試想一下表結構定義需要那些:
1.欄位和欄位型別,在Elasticsearch中的體現就是索引的結構,定義索引的欄位Field Name和欄位型別,上一篇有簡單介紹一下欄位有那些型別;
2.索引,在資料庫中我們可以定義欄位索引,在Elasticsearch中就是相當於是否分詞,按照分詞器分詞;
先來用我們的神器先自定義一個Mapping:
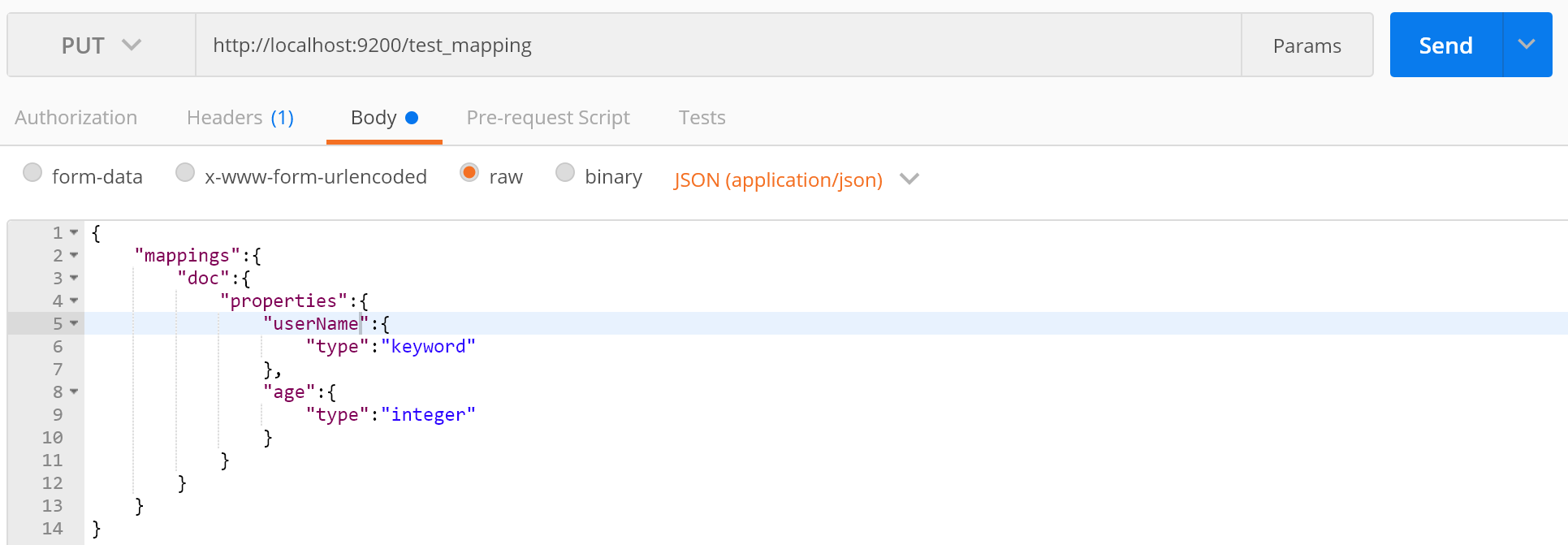
接下來在在查詢下Mapping的結構:

三、Mapping常用引數介紹
type:指定引數的型別;
analyzer:指定分詞器;
boost:指定欄位的權重,
copy_to:指定某幾個欄位合併;
dynamic:欄位動態新增 ,有3種取值:
true:無限制;
false:資料可寫入但該欄位不保留;
strict:無法寫入拋異常;
format:"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" ,格式化 此引數代表可接受的時間格式 3種都接受;
ignore_options:這個選項用於控制倒排索引記錄的內容,有4種配置:
docs:只記錄文件號;
freqs:文件號 + 詞頻;
postions:文件號 + 詞頻 + 位置;
offsets:文件號 + 詞頻 + 位置 + 偏移量;
index:指定某欄位是否被索引;
fileds:可以對一個欄位提供多種索引模式;
null_value:當欄位遇到null值時候的處理機制,預設為null空值,此時es會忽略該值,可以通過設定該值設定該欄位的預設值來改變null不顯示成空值:
properties:巢狀屬性;
search_analyzer:查詢分詞器;
similarity:用於指定文件評分模型,有2種配置:
default:Elasticsearch和Lucene使用的預設TF / IDF演算法;
BM25:Okapi BM25演算法;
基本上常用就是這些,有沒有介紹到的大家可以參考官方文件;
四、欄位的資料型別
上上篇介紹過一些簡單的資料型別在官方稱為核心資料型別,這裡不做過多的介紹了,這裡主要介紹一下複雜的資料型別、地理資料型別、專用資料型別這3種;
複雜的資料型別
1.陣列資料型別(Array datatype)
Elasticsearch中沒有專門的陣列型別,預設情況下每個欄位都可以儲存0個或者多個值,但是這些值得型別必須是一樣的;
2.物件資料型別(Object datatype)
提交文件的時候是Json文件,內部的欄位可以巢狀Json物件;
3.巢狀資料型別(Nested datatype)
巢狀資料型別就是1+2的組合,數組裡面放Json;
地理資料型別
1.地理資料型別(Geo-point datatype)
對經緯度的查詢搜尋;
2.形狀資料型別(Geo-Shape datatype)
對多邊形的的形狀的查詢;
專用資料型別
1.IP資料型別
2.完整的資料型別
提供search-as-you-type的搜尋,這個還是比較有用的大家可以參考下官方文件;
剩下的也使用不多,大家可以參考下官方文件,這裡就不做過多介紹;
五、Search API介紹
Search API實現了對Elasticsearch中儲存的資料進行查詢分析,通過_search方式去查詢,基本上有以下4種情況:

1.不指定索引的情況下查詢的是Elasticsearch中所有的資料;
2.指定index就是對單個的index查詢;
3.另外還可以指定多個索引;
4.還可以通過萬用字元的形式去匹配索引;
Search API查詢的方式主要有兩種:URL Search和Request Body Search,分別對以下兩種情況進行下介紹:
URL Search:
通過URL的形式指定Query引數實現搜尋,我們先來一個demo,然後介紹下常用下引數:
首先先新增些資料:

接下來進行下查詢
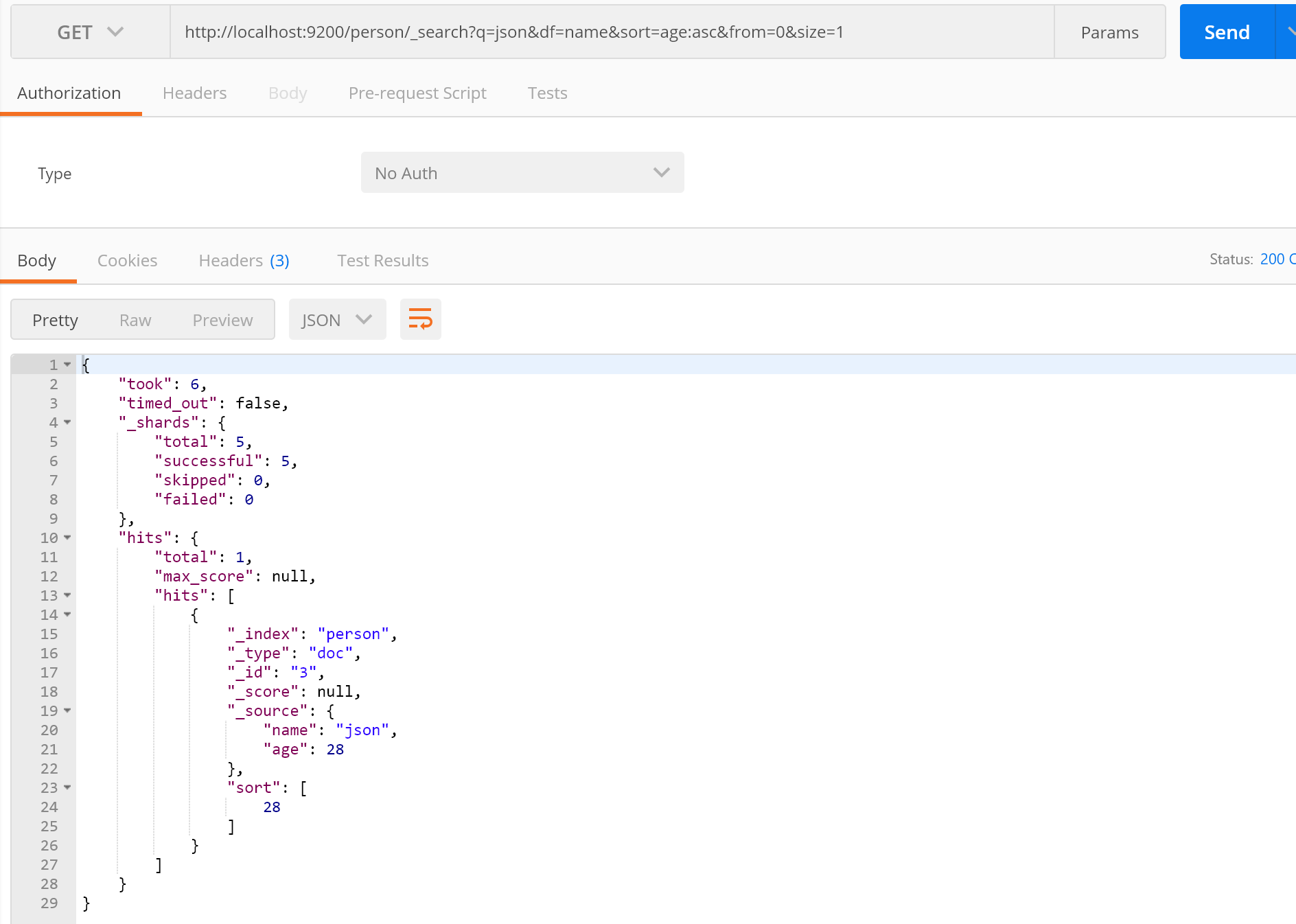
這樣就完成了ES查詢,接下來我們說說常用引數:
q:指定查詢的引數,也就是我們要搜尋的文件的內容;
df:指定我們查詢文件指定的欄位;
sort:指定排序的欄位;
form:第幾條開始;
size:一頁幾條;
剩下大家可以檢視下官方文件,
Request Body Search
這個是主要介紹的,也是我們經常使用的。主要是通過http requset body傳送json請求去對Elasticsearch中儲存的資料進行查詢分析,有個比較專業的名詞Query DSL;主要有兩種型別欄位查詢和複合查詢,接下來我們介紹這兩種查詢的方式:
欄位查詢:
欄位查詢又可以分成兩類:全文匹配和單詞匹配;
全文匹配:
主要對text型別的欄位進行全文檢索,對查詢的語句先進行分詞,例如match、match_pharse等;
match Query
這個是我們經常使用的,接下來我們使用我們神器給大家展示以下怎麼使用;
首先看下person中有哪些欄位:
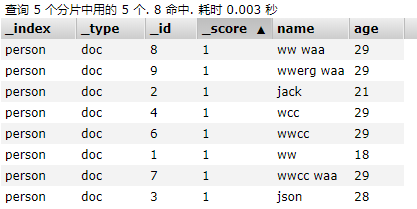
接下來看下使用的方式:

再看下匹配以後的型別,因為匹配到太多,我們用展示程式碼的方式來展示:


{ "took": 12, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": {//匹配文件的總數 "total": 4,//總數 "max_score": 0.80259144,//最匹配的得分 "hits": [//返回文件的總數 { "_index": "person", "_type": "doc", "_id": "1", "_score": 0.80259144,//文件得分 "_source": { "name": "ww", "age": 18 } }, { "_index": "person", "_type": "doc", "_id": "7", "_score": 0.5377023, "_source": { "name": "wwcc waa", "age": 29 } }, { "_index": "person", "_type": "doc", "_id": "8", "_score": 0.32716757, "_source": { "name": "ww waa", "age": 29 } }, { "_index": "person", "_type": "doc", "_id": "9", "_score": 0.32716757, "_source": { "name": "ww waa", "age": 29 } } ] } }View Code
看完上面返回的文件以後,可做如下推測查詢的過程就是將我們查詢的內容進行分詞然後在文件中查詢匹配的分詞,因為文件中不存在name等於waa這種情況,所以沒出現,如果不相信可以補一下這個文件再看下返回結果,過程如下圖:

可以通過設定operator引數來控制分詞間的匹配關係,預設是or,可以設定為and,當and的時候文件種必須同時出現查詢的分詞;
還可以通過minimum_should_match引數設定需要匹配引數的個數;
另外我們還有一個關注的選項就是得分,上面我們說過文件評分的模型有2種:TF/IDF和BM25,但是在介紹這個之前我們還需要知道4個概念:
1.Term Frequency(TF):詞頻,這個應該不陌生在上篇介紹倒排索引原理的時候介紹過這個概念;
2.Document Frequency(DF):文件頻率,單詞在文件中出現的頻率;
3.Inverse Document Frequency(IDF):逆向文件頻率,與文件頻率相反,可理解為1/DF。即單詞出現的文件數越少,相關度越高。
4.Field-length Norm:文件越短,相關度越高;
TF/IDF模型:
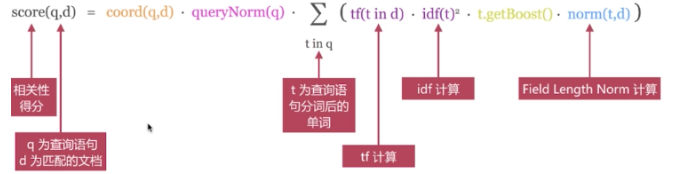
BM25模型

推薦大家看下tf/idf評分演算法,另外可以通過explain引數來檢視得分的計算方法;
match_phrase Query
必須包含查詢的欄位,並且順序不能亂;
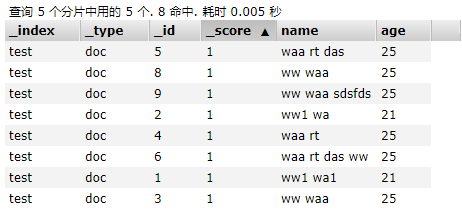
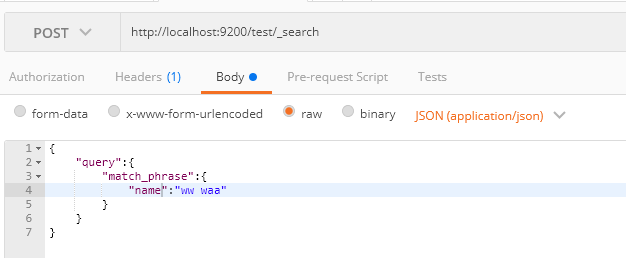
{ "took": 5, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 0.6135754, "hits": [ { "_index": "test", "_type": "doc", "_id": "8", "_score": 0.6135754, "_source": { "name": "ww waa", "age": 25 } }, { "_index": "test", "_type": "doc", "_id": "3", "_score": 0.51623213, "_source": { "name": "ww waa", "age": 25 } }, { "_index": "test", "_type": "doc", "_id": "9", "_score": 0.50104797, "_source": { "name": "ww waa sdsfds", "age": 25 } } ] } }View Code
query_string Query
query_string與Lucene查詢語句的語法結合非常嚴謹,允許在查詢中使用多個特殊條件關鍵字對多個欄位進行查詢,簡單的看下用法:
預設可以指定一個列:

指定多個列查詢

simple_string Query
simple_query_string查詢永遠不會丟擲異常,並丟棄查詢的無效部分,使用+、|、-來代替AND、OR、NOT等等;

我們常用的就是match和match_phrase,剩下的我感覺我是用的不多,大家可以看自己;
單詞匹配:
查詢語句作為整個單詞不進行分詞,主要有term、terms、range、prefix等;
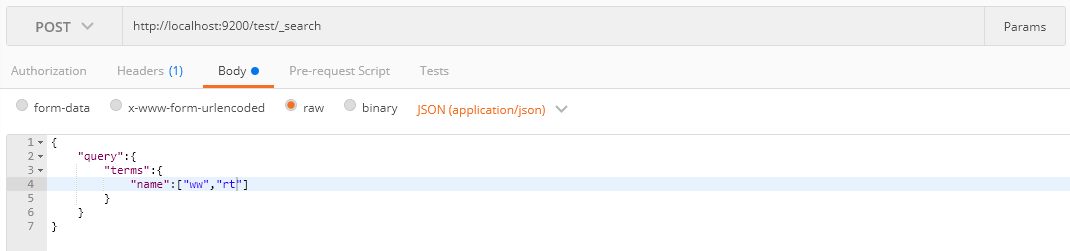
term和terms query
單個單詞進行查詢:

一次可以傳入多個單詞進行查詢
range query
主要是用來匹配某一範圍的值,比如日期、數值型別等等,我們上面有個age型別我們來根據這個查詢下20-30歲的人:

prefix query
查詢某個欄位中以給定字字首開始的文件,比如我們想要查詢以ki開始的使用者欄位;

比較常用的基本上就是這幾種,剩下可以查閱官方文件;
複合查詢(Compound queries):
複合查詢就是組合多個查詢在一起或改變查詢行為,比較常用就是Constant Score Query和bool Query,剩下的大家可以檢視官方文件,根據自己需求去選擇自己想要的;
constant_score Query
在內部包裝一個查詢,將返回結果中每個文件設定一個相同的得分;
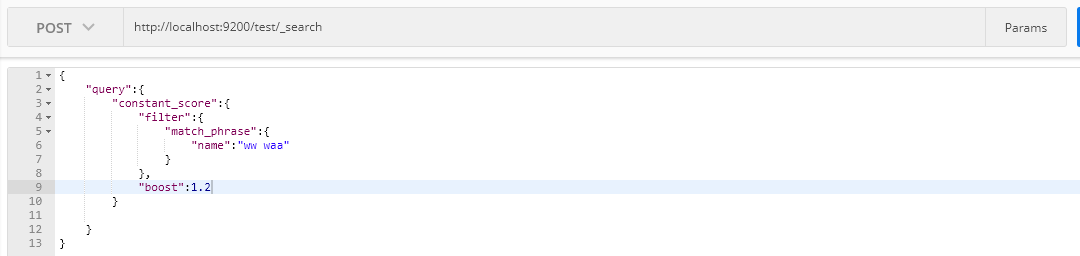
{ "took": 4, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1.2, "hits": [ { "_index": "test", "_type": "doc", "_id": "8", "_score": 1.2, "_source": { "name": "ww waa", "age": 25 } }, { "_index": "test", "_type": "doc", "_id": "9", "_score": 1.2, "_source": { "name": "ww waa sdsfds", "age": 25 } }, { "_index": "test", "_type": "doc", "_id": "3", "_score": 1.2, "_source": { "name": "ww waa", "age": 25 } } ] } }View Code
bool Query
由一個或者多個布林子句構成,主要包含以下4種類型:
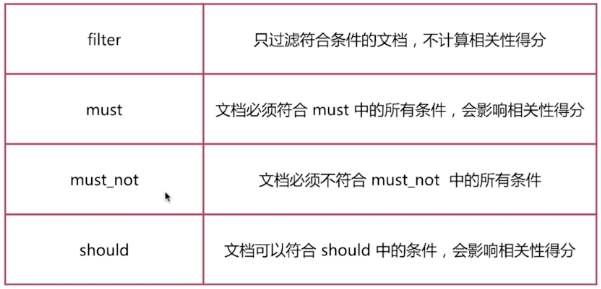
用法如下:
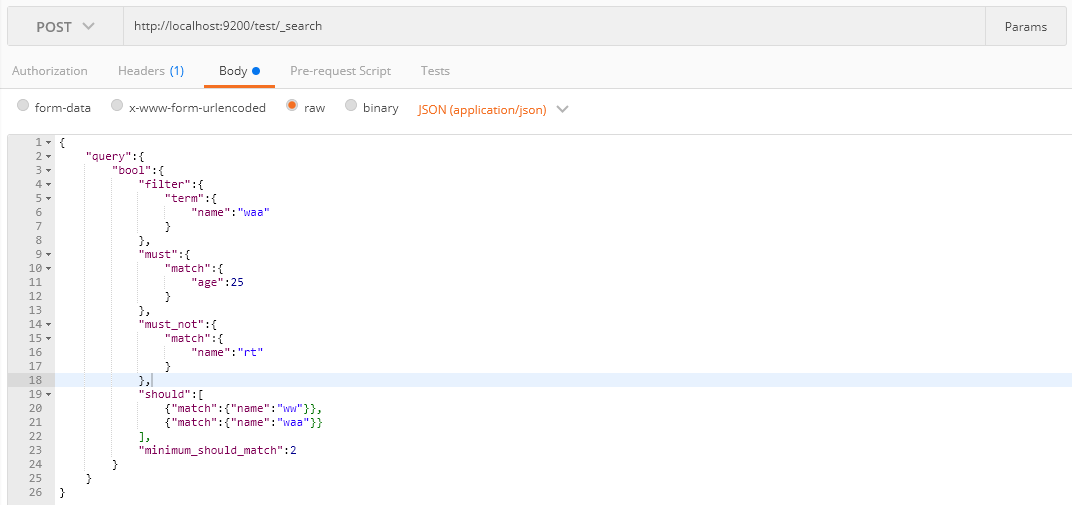
{ "took": 6, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 1.6135753, "hits": [ { "_index": "test", "_type": "doc", "_id": "8", "_score": 1.6135753, "_source": { "name": "ww waa", "age": 25 } }, { "_index": "test", "_type": "doc", "_id": "3", "_score": 1.5162321, "_source": { "name": "ww waa", "age": 25 } }, { "_index": "test", "_type": "doc", "_id": "9", "_score": 1.501048, "_source": { "name": "ww waa sdsfds", "age": 25 } } ] } }View Code
介紹minimum_should_match這個引數,當只有should,文件中引數必須要要滿足條件的個數才會顯示,同時包含should和must時,文件不滿足should中的條件,但是如果滿足條件會增加相關性得分:
在強調一點Filter查詢只過濾複合條件的文件,不會進行相關性算分;
六、結尾
這篇文章寫了好久,下一篇再來好好聊聊Search機制,歡迎大家加群438836709,歡迎大家關注我公眾號:
