
Elastic Stack-Elasticsearch使用介紹(四)
一、前言
上一篇說了一下查詢和儲存機制,接下來我們主要來說一下排序、聚合、分頁;
寫完文章以後發現之前文章沒有介紹Coordinating Node,這個地方補充說明下Coordinating Node(協調節點):搜尋請求或索引請求可能涉及儲存在不同資料節點上的資料。例如,搜尋請求在兩個階段中執行,當客戶端請求到節點上這個階段的時候,協調節點將請求轉發到儲存資料的資料節點。每個資料節點在分片執行請求並將其結果返回給協調節點。當節點返回到客端這個階段的時候,協調節點將每個資料節點的結果減少為單個節點的所有資料的結果集。這意味著每個節點具有全部三個node.master,node.data並node.ingest這個屬性,當node.ingest設定為false僅作為協調節點,不能被禁用。
二、排序
ES預設使用相關性算分來排序,如果想改變排序規則可以使用sort:
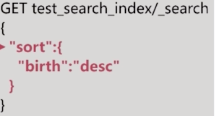
也可以指定多個排序條件:

排序的過程是指是對欄位原始內容排序的過程,在排序的過程中使用的正排索引,是通過文件的id和欄位進行排序的;Elasticsearch針對這種情況提供兩種實現方式:fielddata和doc_value;
fielddata
fielddata的資料結構,其實根據倒排索引反向出來的一個正排索引,即document到term的對映。只要我們針對需要分詞的欄位設定了fielddata,就可以使用該欄位進行聚合,排序等。我們設定為true之後,在索引期間,就會以列式儲存在記憶體中。為什麼存在於記憶體呢,因為按照term聚合,需要執行更加複雜的演算法和操作,如果基於磁碟或者 OS 快取,效能會比較差。用法如下:

fielddata載入到記憶體中有幾種情況,預設是懶載入。即對一個分詞的欄位執行聚合或者排序的時候,載入到記憶體。所以他不是在索引建立期間建立的,而是查詢在期間建立的。
fielddata在記憶體中載入的這樣就會出現一個問題,資料量很大的情況容易發生OOM,這種時候我們該如何控制OOM的情況發生?
1.記憶體限制
indices.fielddata.cache.size: 20% 預設是無限制,限制記憶體使用以後頻繁的導致記憶體回收,容易照成GC和IO損耗。
2.斷路器(circuit breaker)
如果查詢一次的fielddata超過總記憶體,就會發生記憶體溢位,circuit breaker會估算query要載入的fielddata大小,如果超出總記憶體,就短路,query直接失敗;
indices.breaker.fielddata.limit:fielddata的記憶體限制,預設60%
indices.breaker.request.limit:執行聚合的記憶體限制,預設40%
indices.breaker.total.limit:綜合上面兩個,限制在70%以內
3.頻率(frequency)
載入fielddata的時候,也是按照segment去進行載入的,所以可以通過限制segment文件出現的頻率去限制載入的數目;
min :0.01 只是載入至少1%的doc文件中出現過的term對應的文件;
min_segment_size: 500 少於500 文件數的segment不載入fielddata;
fielddata載入方式:
1.lazy
這個在查詢的放入到記憶體中,上面已經介紹過;
2.eager(預載入)
當一個新的segment形成的時候,就載入到記憶體中,查詢的時候遇到這個segment直接查詢出去就可以;
3.eager_global_ordinals(全域性序號載入)
構建一個全域性的Hash,新出現的文件加入Hash,文件中用序號代替字元,這樣會減少記憶體的消耗,但是每次要是有segment新增或者刪除時候回導致全域性序號重建的問題;
doc_value
fielddata對記憶體要求比較高,如果資料量很大的話對記憶體是一個很大的考驗。所以Elasticsearch又給我們提供了另外的策略doc_value,doc_value使用磁碟儲存,與fielddata結構完全是一樣的,在倒排索引基礎上反向出來的正排索引,並且是預先構建,即在建倒排索引的時候,就會建立doc values。,這會消耗額外的儲存空間,但是對於JVM的記憶體需求就會減少。總體來看,dov_valus只是比fielddata慢一點,大概10-25%,則帶來了更多的穩定性。
型別是string的欄位,生成分詞欄位(text)和不分詞欄位(keyword),不分詞欄位即使用keyword,所以我們在聚合的時候,可以直接使用field.keyword進行聚合,而這種預設就是使用doc_values,建立正排索引。不分詞的欄位,預設建立doc_values,即欄位型別為keyword,他不會建立分詞,就會預設建立doc_value,如果我們不想該欄位參與聚合排序,我們可以設定doc_values=false,避免不必要的磁碟空間浪費。但是這個只能在索引對映的時候做,即索引對映建好之後不能修改。
兩者對比:

三、分頁
有3種類型的分頁,如下圖:
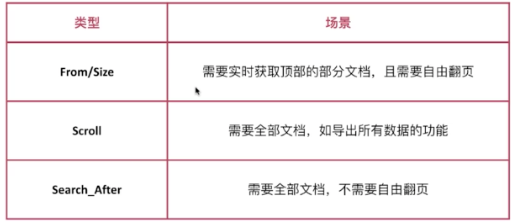
1.from/size
form開始的位置,size獲取的數量;

資料在分片儲存的情況下怎麼查詢前1000個文件?
在每個分片上都先獲取1000個文件,然後再由Coordinating Node聚合所有分片的結果後再排序選取前1000個文件,頁數越多,處理文件就越多,佔用記憶體越多,耗時越長。資料分別存放在不同的分片上,必須一個去查詢;為了避免深度分頁,Elasticsearch通過index.max_result_window限定顯示條數,預設是10000;

2.scroll
scroll按照快照的方式來查詢資料,可以避免深度分頁的問題,因為是快照所以不能用來做實時搜尋,資料不是實時的,接下來說一下scroll流程:
首先發起scroll查詢請求,Elasticsearch在接收到請求以後會根據查詢條件查詢文件i,1m表示該快照保留1分鐘;

接下來查詢的時候根據上一次返回的快照id繼續查詢,不斷的迭代呼叫直到返回hits.hits陣列為空時停止

過多的scroll呼叫會佔用大量的記憶體,可以通過刪除的clear api進行刪除:
刪除某個:

刪除多個:

刪除所有:

3.search after
避免深度分頁的效能問題,提供實時的下一頁文件獲取功能,通過提供實時遊標來解決此問題,接下來我們來解釋下這個問題:
第一次查詢:這個地方必須保證排序的值是唯一的

第二步: 使用上一步最後一個文件的sort值進行查詢
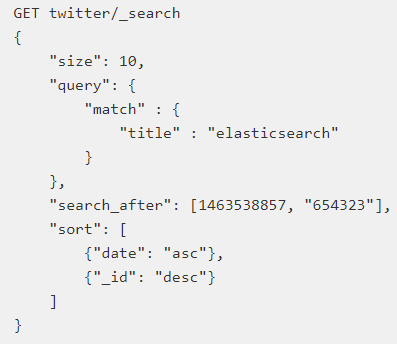
通過保證排序欄位唯一,我們實現類似資料庫遊標功能的效果;
四、聚合分析
Aggregation,是Elasticsearch除搜尋功能外提供的針對Elasticsearch資料做統計分析的功能,聚合的實時性很高,都是及時返回,另外還提供多種分析方式,接下來我們看下聚合的4種分析方式:
Metric
在一組文件中計算平均值、最大值、最小值、求和等等;
Avg(平均值)


Min最小值


Sum求和(過濾查詢中的結果查詢出帽子的價格的總和)


Percentile計算從聚合文件中提取的數值的一個或多個百分位數;
解釋下下面這個例子,網站響應時間做的一個分析,單位是毫秒,5毫秒響應占總響應時間的1%;


Cardinality計算不同值的近似計數,類似資料庫的distinct count


當然除了上面還包括很多型別,更加詳細的內容可以參考官方文件;
Bucket
按照一定的規則將文件分配到不同的桶裡,達到分類分析的目的;
比如把年齡小於10放入第一個桶,大於10小於30放入第二個桶裡,大於30放到第三個桶裡;
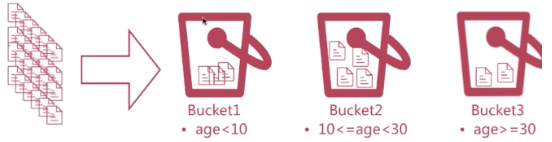
接下來我們介紹我們幾個常用的型別:
Date Range
根據時間範圍來劃分桶的規則;


to表示小於當前時間減去10個月;from大於當前時間減去10個月;format設定返回格式;form和to還可以指定範圍,大於某時間小於某時間;
Range
通過自定義範圍來劃分桶的規則;


這樣就可以輕易做到上面按照年齡分組統計的規則;
Terms
直接按照term分桶,類似資料庫group by以後求和,如果是text型別則按照分詞結果分桶;


比較常用的型別大概就是這3種,比如還有什麼Histogram等等,大家可以參考官方文件;
Pipeline
對聚合的結果在次進行聚合分析,根據輸出的結果不同可以分成2類:
Parent
將返回的結果內嵌到現有的聚合結果中,主要有3種類型:
1.Derivative
計算Bucket值的導數;
2.Moving Average
計算Bucket值的移動平均值,一定時間段,對時間序列資料進行移動計算平均值;
3.Cumulatove Sum
計算累計加和;
Sibling
返回的結果與現有聚合結果同級;
1.Max/Min/Avg/Sum
2.Stats/Extended
Stats用於計算聚合中指定列的所有桶中的各種統計資訊;
Extended對Stats的擴充套件,提供了更多統計資料(平方和,標準偏差等);
3.Percentiles
Percentiles 計算兄弟中指定列的所有桶中的百分位數;
更多介紹,請參考官方文件;
Matrix
矩陣分析,使用不多,參考官方文件;
原理探討與資料準確性探討:
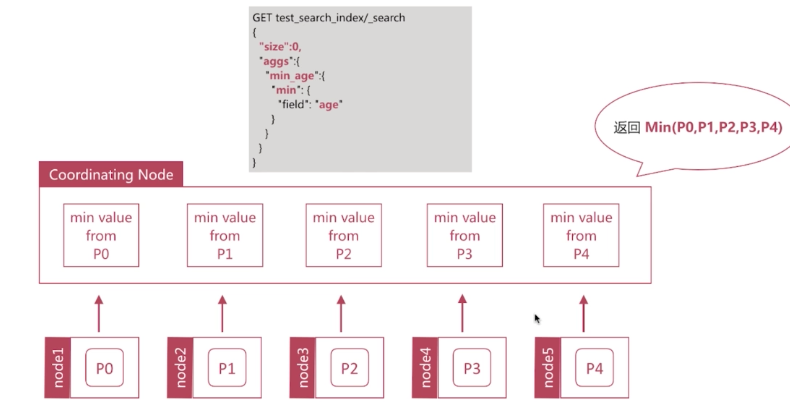
Min原理分析:
先從每個分片計算最小值 -> 再從這些值中計算出最小值
Terms聚合以及提升計算值的準確性:
Terms聚合的執行流程:每個分片返回top10的資料,Coordinating node拿到資料之後進行整合和排序然後返回給使用者。注意Terms並不是永遠準確的,因為資料分散在多個分片上,所以Coordinating node無法得到所有資料(這句話有同學會有疑惑請檢視上一篇文章)。如果要解決可以把分片數設定為1,消除資料分散的問題,但是會分片資料過多問題,或者設在Shard_Size大小,即每次從Shard上額外多獲取的資料,以提升準確度。
Terms聚合返回結果中有兩個值:
doc_count_error_upper_bound 被遺漏的Term的最大值;
sum_other_doc_count 返回聚合的其他term的文件總數;
在Terms中設定show_term_doc_count_error可以檢視每個聚合誤算的最大值;
Shard_Size預設大小:shard_size = (size*1.5)+10;
通過調整Shard_Size的大小可以提升準確度,增大了計算量降低響應的時間。
由上面可以得出在Elasticsearch聚合分析中,Cardinality和Percentile分析使用是近似統計演算法,就是結果近似準確但是不一定精確,可以通過引數的調整使其結果精確,意味著會有更多的時間和更大的效能消耗。
五、結束語
Search分析到此基本結束,下一篇介紹一些常用的優化手段和建立索引時的考慮問題;歡迎大家加群438836709,歡迎大家關注我公眾號!
