
Elastic Stack-Elasticsearch使用介紹(三)
一、前言
上一篇說了這篇要講解Search機制,但是在這個之前我們要明白下檔案是怎麼儲存的,我們先來將檔案的儲存然後再來探究機制;
二、文件儲存
之前說過文件是儲存在分片上的,這裡要思考一個問題:文件是通過什麼方式去分配到分片上的?我們來思考如下幾種方式:
1.通過文件與分片取模實現,這樣做的好處在於可以將文件平均分配到所以的分片上;
2.隨機分配當然也可以,這種可能造成分配不均,照成空間浪費;
3.輪詢這種是最不可取的,採用這種你需要建立文件與分片的對映關係,這樣會導致成本太大;
經過一輪強烈的思考,我們選擇方案1,沒錯你想對了,這裡Elasticsearch也和我們思考的是一樣的,我們來揭露下他分配的公式:
shard_num = hash(_routing)%num_primary_shards
routing是一個關鍵引數,預設是文件id,可以自行指定;
number_of_primary_shard 主分片數;
之前我們介紹過節點的型別,接下來我們來介紹下,當文件建立時候的流程:
假設的情況:1個主節點和2個數據節點,1個副本:
文件的建立:
1.客戶端向節點發起建立文件的請求;
2.通過routing計算文件儲存的分片,查詢叢集確認分片在資料節點1上,然後轉發文件到資料節點1;
3.資料節點1接收到請求建立文件,同時傳送請求到該住分片的副本;
4.主分片的副本接收到請求則開始建立文件;
5.副本分片文件完成以後傳送成功的通知給主分片;
6.當主分片接收到建立完成的資訊以後,傳送給節點建立成功的通知;
7.節點返回結果給客戶端;
這個地方我們在做一些深入的思考:我們搜尋的時候是通過倒排索引,但是倒排索引一旦建立是不能修改的,這樣做有那些好處壞處?
好處:
1.不用考慮併發寫入檔案的問題,杜絕鎖機制帶來的效能問題;
2.檔案不再更改,可以充分利用檔案系統快取,只需載入一次,只要內容足夠,對該檔案的讀取都會從記憶體中讀取,效能高;
壞處:
寫入新文件時,必須重新構建倒排索引檔案,然後替換老檔案後,新文件才能被檢索,導致文件實時性差;
問題:
對於新插入文件的時候寫入倒排索引,導致倒排索引重建的問題,假如根據新文件來重新構建倒排索引檔案,然後生成一個新的倒排索引檔案,再把使用者的原查詢切掉,切換到新的倒排索引。這樣開銷會很大,會導致實時性非常差。
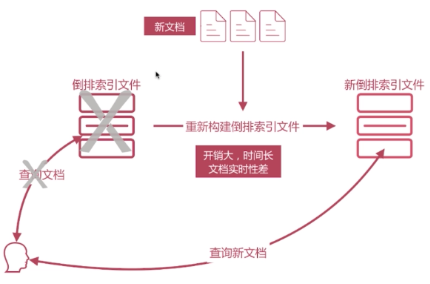
Elasticsearch如何解決檔案搜尋的實時性問題:

新文件直接生成新的倒排索引檔案,查詢的時候同時查詢所有的倒排檔案,然後做結果的彙總計算即可,ES是是通過Lucene構建的,Lucene就是通過這種方案處理的,我們介紹下Luncene構建文件的時候的結構:
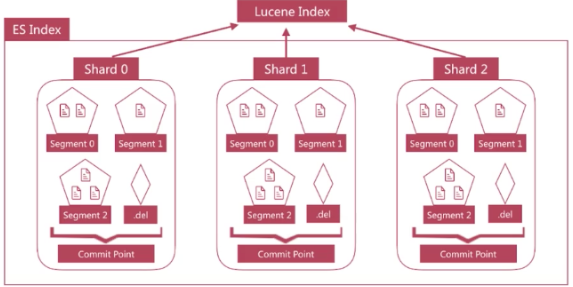
1.Luncene中單個倒排索引稱為Segment,合在一起稱為Index,這個Index與Elasticsearch概念是不相同的,Elasticsearch中的每個Shard對應一個Lucene Index;
2.Lucene會有個專門檔案來記錄所有的Segment資訊,稱為Commit Point,用來維護Segment的資訊;
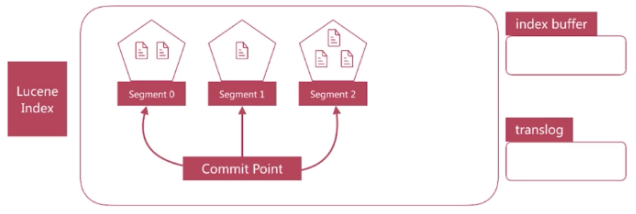
Segment寫入磁碟的時候過程中也是比較慢的,Elasticsearch提供一個Refresh機制,是通過檔案快取的機制實現的,接下我們介紹這個過程:
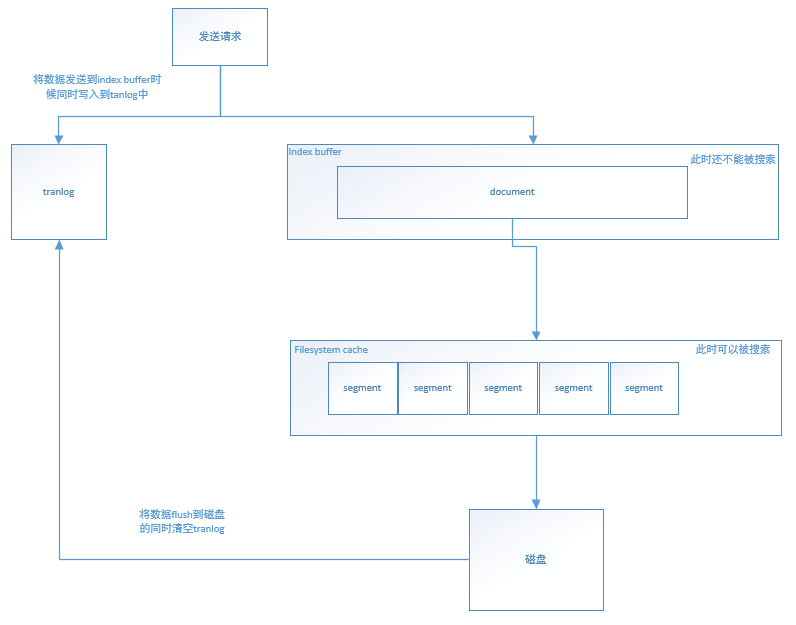
1.在refresh之前的文件會先儲存在一個Buffer裡面,refresh時將Buffer中的所有文件清空,並生成Segment;
2.Elasticsearch預設每1秒執行一次refresh,因此文件的實時性被提高到1秒,這也是Elasticsearch稱為近實時(Near Real Time)的原因;
Segment寫入磁碟前如果發生了宕機,那麼其中的文件就無法恢復了,怎麼處理這個問題?
Elasticsearch引入translog(事務日誌)機制,translog的寫入也可以設定,預設是request,每次請求都會寫入磁碟(fsync),這樣就保證所有資料不會丟,但寫入效能會受影響;如果改成async,則按照配置觸發trangslog寫入磁碟,注意這裡說的只是trangslog本身的寫盤。Elasticsearch啟動時會檢查translog檔案,並從中恢復資料;
還有一種機制flush機制,負責將記憶體中的segment寫入磁碟和刪除舊的translog檔案;
新增的時候搞定了,那刪除和更新怎麼辦?
刪除的時候,Lucene專門維護一個.del檔案,記錄所有已經刪除的文件,del檔案上記錄的是文件在Lucene內部的id,查詢結果返回前過濾掉.del中的所有文件;
更新就簡單了,先刪除然後再建立;
隨著Segment增加,查詢一次會涉及很多,查詢速度會變慢,Elasticsearch會定時在後臺進行Segment Merge的操作,減少Segment的數量,通過force_merge api可以手動強制做Segment Merge的操作;
另外可以參考下這篇文段合併;
三、Search機制
搜尋的型別其實有2種:Query Then Ferch和DFS Query Then Ferch,當我們明白如何儲存檔案的是時候,再去理解這兩種查詢方式會很簡單;
Query Then Ferch
Search在執行的時候分為兩個步驟運作Query(查詢)和Fetch(獲取),基本流程如下:
1.將查詢分配到每個分片;
2.找到所有匹配的文件,並在當前的分片的文件使用Term/Document Frequency資訊進行打分;
3.構建結果的優先順序佇列(排序,分頁等);
4.將結果的查詢到的資料返回給請求節點。請注意,實際文件尚未傳送,只是分數;
5.將所有分片的分數在請求節點上合併和排序,根據查詢條件選擇文件;
6.最後從篩選出的文件所在的各個分片中檢索實際的文件;
7.結果將返回給客戶端;
DFS Query Then Ferch
DFS是在進行真正的查詢之前, 先把各個分片的詞頻率和文件頻率收集一下, 然後進行詞搜尋的時候, 各分片依據全域性的詞頻率和文件頻率進行搜尋和排名,基本流程如下:
1.提前查詢每個shard,詢問Term和Document frequency;
2.將查詢分配到每個分片;
3.找到所有匹配到的文件,並且在所有分片的文件使用Term/Document Frequency資訊進行打分;
4.構建結果的優先順序佇列(排序,分頁等);
5.將結果的查詢到的資料返回給請求節點。請注意,實際文件尚未傳送,只是分數;
6.來自所有分片的分數合併起來,並在請求節點上進行排序,文件被按照查詢要求進行選擇;
7.最終,實際文件從他們各自所在的獨立的分片上檢索出來;
8.結果被返回給客戶端;
總結下,根據上面的兩種查詢方式來看的DFS查詢得分明顯會更接近真實的得分,但是DFS 在拿到所有文件後再從新完整的計算一次相關性算分,耗費更多的cpu和記憶體,執行效能也比較低下,一般不建議使用。使用方式如下:

另外要是當文件資料不多的時候可以考慮使用一個分片;
四、下節預告
本來還想說下聚合、排序方面的查詢,但是看篇幅也差不多了,留點時間出去浪,最近不光要撒狗糧,也要撒知識,國慶節期間準備完成Elastic Stack系列,下面接下來還會有4-5篇左右,歡迎大家加群438836709,歡迎大家關注我公眾號!
