SparkStreaming原始碼執行架構圖解
阿新 • • 發佈:2018-12-09
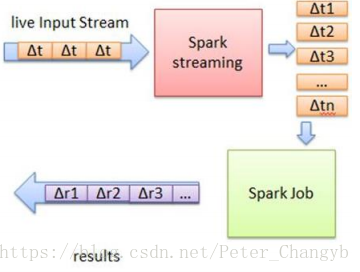
Spark Streaming基本原理:是將流資料分成小的時間片段(幾秒),以類似批處理方式來處理這部分小資料。
處理流程:
- Spark Streaming把實時輸入資料流以時間片Δt (如1秒)為單位切分成塊
- Spark Streaming會把每塊資料作為一個RDD,並使用RDD操作處理每一小塊資料
- 每個塊都會生成一個Spark Job處理
- 最終結果也返回多塊
Spark Streaming是建立在Spark上的實時計算框架,通過它提供豐富的API、基於記憶體的高速執行引擎,使用者可以結合流式、批處理和互動試查詢應用。
- Saprk的低延遲執行引擎(100MS+)可以用於實時處理
- 相比於strom(基於Record),RDD資料更容易做容錯。
- 可以與kafka,Flume,ZeroMQ等進行資料來源的對接
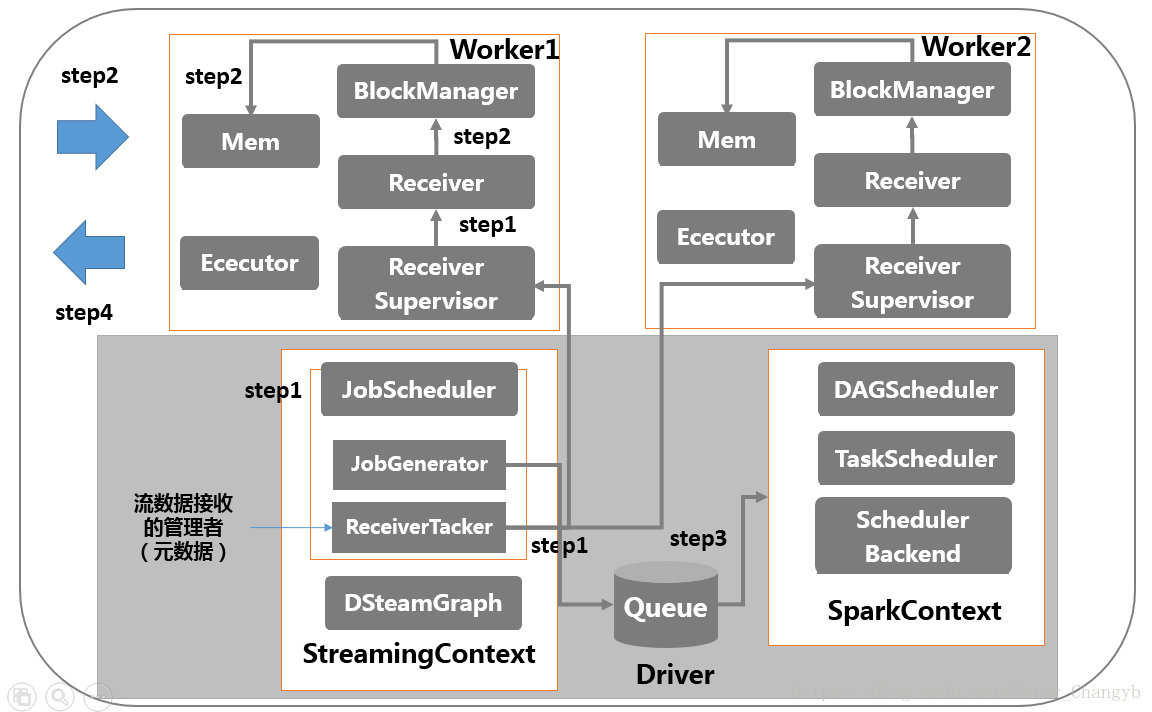
- 先說一下各個元件:SparkStreaming包括Driver和Client端,StreamingContext執行在Driver端,包括如圖中的幾個程序。
執行步驟如下:
- step1:啟動流處理引擎StreamingContext,建立DStreamGraph/JobScheduler(Receiver Tacker管理者),Receiver Tacker通知客戶端ReceiverSuperVisor管理者和Receiver幹事,要開始接收資料。
- step2:ReceiverSuperVisor通知Receiver寫記憶體或者磁碟,一旦寫滿,通知Receiver Tacker管理者,提交資料儲存位置,把元資訊給Receiver Tacker。
- step3:StreamingContext的定時器JobGenerator,通知Receiver Tacker管理者提交資料給叢集,並要求DStreamGraph生成作業序號。
- step4:資料處理結果給外部。