
Spark執行架構(Good)
轉自與https://note.youdao.com/share/?id=7fc41e362e86a863a84e787573433a76&type=note#/
1、 Spark執行架構
1.1 術語定義
lApplication:Spark Application的概念和Hadoop MapReduce中的類似,指的是使用者編寫的Spark應用程式,包含了一個Driver 功能的程式碼和分佈在叢集中多個節點上執行的Executor程式碼;
lDriver:Spark中的Driver即執行上述Application的main()函式並且建立SparkContext
lExecutor:Application執行在Worker 節點上的一個程序,該程序負責執行Task,並且負責將資料存在記憶體或者磁碟上,每個Application都有各自獨立的一批Executor。在Spark on Yarn模式下,其程序名稱為CoarseGrainedExecutorBackend
lCluster Manager:指的是在叢集上獲取資源的外部服務,目前有:
Ø Standalone:Spark原生的資源管理,由Master負責資源的分配;
Ø Hadoop Yarn:由YARN
lWorker:叢集中任何可以執行Application程式碼的節點,類似於YARN中的NodeManager節點。在Standalone模式中指的就是通過Slave檔案配置的Worker節點,在Spark on Yarn模式中指的就是NodeManager節點;
l作業(Job):包含多個Task組成的平行計算,往往由Spark Action催生,一個JOB包含多個RDD及作用於相應RDD上的各種Operation;
l階段(Stage):每個Job會被拆分很多組Task,每組任務被稱為Stage,也可稱TaskSet,一個作業分為多個階段;
l任務(Task): 被送到某個Executor上的工作任務;

1.2 Spark執行基本流程
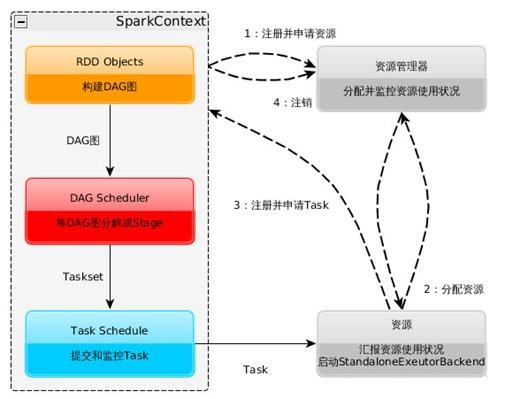
Spark執行基本流程參見下面示意圖
1. 構建Spark Application的執行環境(啟動SparkContext),SparkContext向資源管理器(可以是Standalone、Mesos或YARN)註冊並申請執行Executor資源;
2. 資源管理器分配Executor資源並啟動StandaloneExecutorBackend,Executor執行情況將隨著心跳傳送到資源管理器上;
3. SparkContext構建成DAG圖,將DAG圖分解成Stage,並把Taskset傳送給Task Scheduler。Executor向SparkContext申請Task,Task Scheduler將Task發放給Executor運行同時SparkContext將應用程式程式碼發放給Executor。
4. Task在Executor上執行,執行完畢釋放所有資源。

Spark執行架構特點:
l每個Application獲取專屬的executor程序,該程序在Application期間一直駐留,並以多執行緒方式執行tasks。這種Application隔離機制有其優勢的,無論是從排程角度看(每個Driver排程它自己的任務),還是從執行角度看(來自不同Application的Task執行在不同的JVM中)。當然,這也意味著Spark Application不能跨應用程式共享資料,除非將資料寫入到外部儲存系統。
lSpark與資源管理器無關,只要能夠獲取executor程序,並能保持相互通訊就可以了。
l提交SparkContext的Client應該靠近Worker節點(執行Executor的節點),最好是在同一個Rack裡,因為Spark Application執行過程中SparkContext和Executor之間有大量的資訊交換;如果想在遠端叢集中執行,最好使用RPC將SparkContext提交給叢集,不要遠離Worker執行SparkContext。
lTask採用了資料本地性和推測執行的優化機制。
1.2.1 DAGScheduler
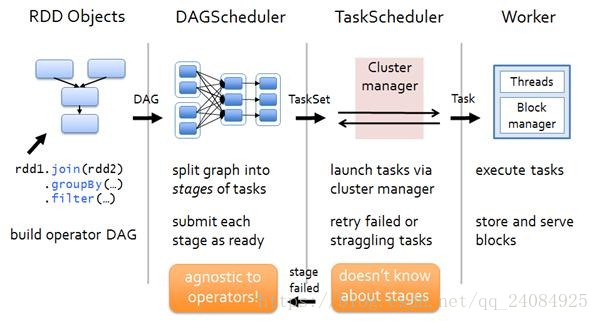
DAGScheduler把一個Spark作業轉換成Stage的DAG(Directed Acyclic Graph有向無環圖),根據RDD和Stage之間的關係找出開銷最小的排程方法,然後把Stage以TaskSet的形式提交給TaskScheduler,下圖展示了DAGScheduler的作用:

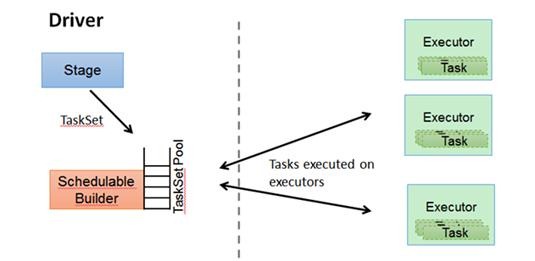
1.2.2 TaskScheduler
DAGScheduler決定了執行Task的理想位置,並把這些資訊傳遞給下層的TaskScheduler。此外,DAGScheduler還處理由於Shuffle資料丟失導致的失敗,這有可能需要重新提交執行之前的Stage(非Shuffle資料丟失導致的Task失敗由TaskScheduler處理)。
TaskScheduler維護所有TaskSet,當Executor向Driver傳送心跳時,TaskScheduler會根據其資源剩餘情況分配相應的Task。另外TaskScheduler還維護著所有Task的執行狀態,重試失敗的Task。下圖展示了TaskScheduler的作用:
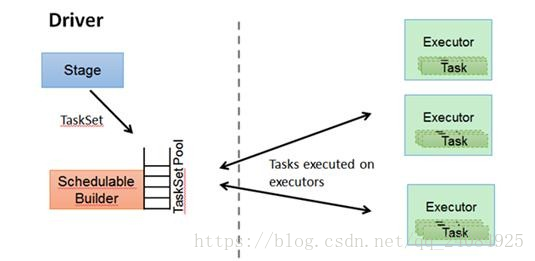
在不同執行模式中任務排程器具體為:
l Spark on Standalone模式為TaskScheduler;
l YARN-Client模式為YarnClientClusterScheduler
l YARN-Cluster模式為YarnClusterScheduler
1.3 RDD執行原理
那麼 RDD在Spark架構中是如何執行的呢?總高層次來看,主要分為三步:
1.建立 RDD 物件
2.DAGScheduler模組介入運算,計算RDD之間的依賴關係。RDD之間的依賴關係就形成了DAG
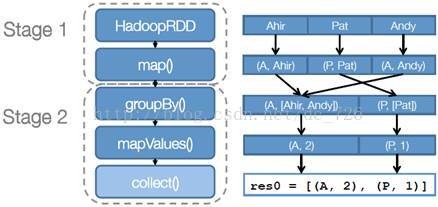
3.每一個JOB被分為多個Stage,劃分Stage的一個主要依據是當前計算因子的輸入是否是確定的,如果是則將其分在同一個Stage,避免多個Stage之間的訊息傳遞開銷。
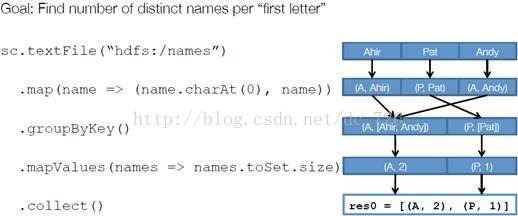
以下面一個按 A-Z 首字母分類,查詢相同首字母下不同姓名總個數的例子來看一下 RDD 是如何執行起來的。

步驟 1 :建立 RDD 上面的例子除去最後一個 collect 是個動作,不會建立 RDD 之外,前面四個轉換都會創建出新的 RDD 。因此第一步就是建立好所有 RDD( 內部的五項資訊 )。
步驟 2 :建立執行計劃 Spark 會盡可能地管道化,並基於是否要重新組織資料來劃分 階段(stage) ,例如本例中的 groupBy() 轉換就會將整個執行計劃劃分成兩階段執行。最終會產生一個 DAG(directed acyclic graph ,有向無環圖 ) 作為邏輯執行計劃。

步驟 3 :排程任務 將各階段劃分成不同的 任務 (task) ,每個任務都是資料和計算的合體。在進行下一階段前,當前階段的所有任務都要執行完成。因為下一階段的第一個轉換一定是重新組織資料的,所以必須等當前階段所有結果資料都計算出來了才能繼續。
假設本例中的 hdfs://names 下有四個檔案塊,那麼 HadoopRDD 中 partitions 就會有四個分割槽對應這四個塊資料,同時 preferedLocations 會指明這四個塊的最佳位置。現在,就可以創建出四個任務,並排程到合適的叢集結點上。

2、Spark在不同叢集中的執行架構
Spark注重建立良好的生態系統,它不僅支援多種外部檔案儲存系統,提供了多種多樣的叢集執行模式。部署在單臺機器上時,既可以用本地(Local)模式執行,也可以使用偽分散式模式來執行;當以分散式叢集部署的時候,可以根據自己叢集的實際情況選擇Standalone模式(Spark自帶的模式)、YARN-Client模式或者YARN-Cluster模式。Spark的各種執行模式雖然在啟動方式、執行位置、排程策略上各有不同,但它們的目的基本都是一致的,就是在合適的位置安全可靠的根據使用者的配置和Job的需要執行和管理Task。
2.1 Spark on Standalone執行過程
Standalone模式是Spark實現的資源排程框架,其主要的節點有Client節點、Master節點和Worker節點。其中Driver既可以執行在Master節點上中,也可以執行在本地Client端。當用spark-shell互動式工具提交Spark的Job時,Driver在Master節點上執行;當使用spark-submit工具提交Job或者在Eclips、IDEA等開發平臺上使用”new SparkConf.setManager(“spark://master:7077”)”方式執行Spark任務時,Driver是執行在本地Client端上的。
其執行過程如下:
1.SparkContext連線到Master,向Master註冊並申請資源(CPU Core 和Memory);
2.Master根據SparkContext的資源申請要求和Worker心跳週期內報告的資訊決定在哪個Worker上分配資源,然後在該Worker上獲取資源,然後啟動StandaloneExecutorBackend;
3.StandaloneExecutorBackend向SparkContext註冊;
4.SparkContext將Applicaiton程式碼傳送給StandaloneExecutorBackend;並且SparkContext解析Applicaiton程式碼,構建DAG圖,並提交給DAG Scheduler分解成Stage(當碰到Action操作時,就會催生Job;每個Job中含有1個或多個Stage,Stage一般在獲取外部資料和shuffle之前產生),然後以Stage(或者稱為TaskSet)提交給Task Scheduler,Task Scheduler負責將Task分配到相應的Worker,最後提交給StandaloneExecutorBackend執行;
5.StandaloneExecutorBackend會建立Executor執行緒池,開始執行Task,並向SparkContext報告,直至Task完成。
6.所有Task完成後,SparkContext向Master登出,釋放資源。

2.2 Spark on YARN執行過程
YARN是一種統一資源管理機制,在其上面可以執行多套計算框架。目前的大資料技術世界,大多數公司除了使用Spark來進行資料計算,由於歷史原因或者單方面業務處理的效能考慮而使用著其他的計算框架,比如MapReduce、Storm等計算框架。Spark基於此種情況開發了Spark on YARN的執行模式,由於藉助了YARN良好的彈性資源管理機制,不僅部署Application更加方便,而且使用者在YARN叢集中執行的服務和Application的資源也完全隔離,更具實踐應用價值的是YARN可以通過佇列的方式,管理同時執行在叢集中的多個服務。
Spark on YARN模式根據Driver在叢集中的位置分為兩種模式:一種是YARN-Client模式,另一種是YARN-Cluster(或稱為YARN-Standalone模式)。
2.2.1 YARN框架流程
任何框架與YARN的結合,都必須遵循YARN的開發模式。在分析Spark on YARN的實現細節之前,有必要先分析一下YARN框架的一些基本原理。
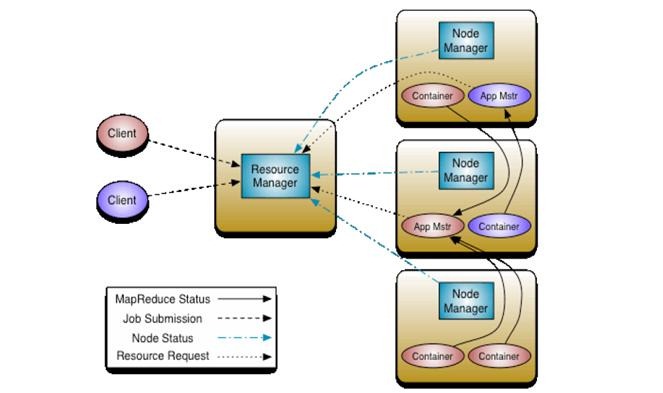
Yarn框架的基本執行流程圖為:
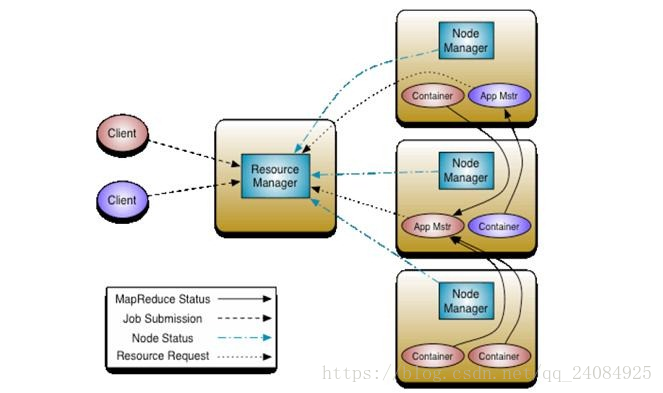
其中,ResourceManager負責將叢集的資源分配給各個應用使用,而資源分配和排程的基本單位是Container,其中封裝了機器資源,如記憶體、CPU、磁碟和網路等,每個任務會被分配一個Container,該任務只能在該Container中執行,並使用該Container封裝的資源。NodeManager是一個個的計算節點,主要負責啟動Application所需的Container,監控資源(記憶體、CPU、磁碟和網路等)的使用情況並將之彙報給ResourceManager。ResourceManager與NodeManagers共同組成整個資料計算框架,ApplicationMaster與具體的Application相關,主要負責同ResourceManager協商以獲取合適的Container,並跟蹤這些Container的狀態和監控其進度。
2.2.2 YARN-Client
Yarn-Client模式中,Driver在客戶端本地執行,這種模式可以使得Spark Application和客戶端進行互動,因為Driver在客戶端,所以可以通過webUI訪問Driver的狀態,預設是http://hadoop1:4040訪問,而YARN通過http:// hadoop1:8088訪問。
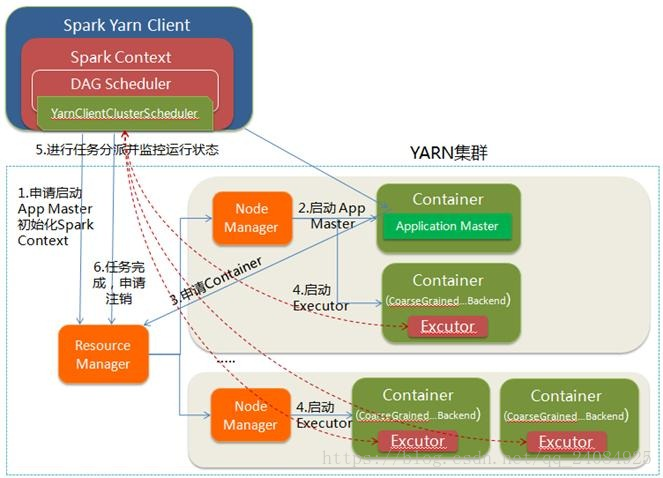
YARN-client的工作流程分為以下幾個步驟:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
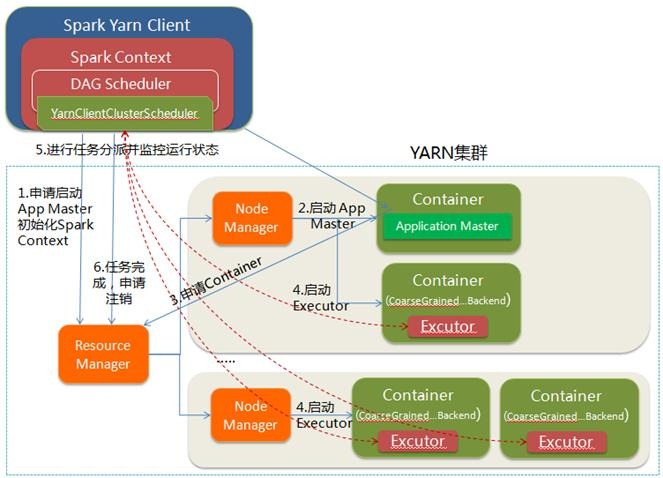
1.Spark Yarn Client向YARN的ResourceManager申請啟動Application Master。同時在SparkContent初始化中將建立DAGScheduler和TASKScheduler等,由於我們選擇的是Yarn-Client模式,程式會選擇YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到請求後,在叢集中選擇一個NodeManager,為該應用程式分配第一個Container,要求它在這個Container中啟動應用程式的ApplicationMaster,與YARN-Cluster區別的是在該ApplicationMaster不執行SparkContext,只與SparkContext進行聯絡進行資源的分派;
3.Client中的SparkContext初始化完畢後,與ApplicationMaster建立通訊,向ResourceManager註冊,根據任務資訊向ResourceManager申請資源(Container);
4.一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通訊,要求它在獲得的Container中啟動啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向Client中的SparkContext註冊並申請Task;
5.Client中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend