
論文筆記 Learning Visual Knowledge Memory Networks for Visual Question Answering (CVPR2018)
這篇文章的一個出發點也是希望VQA裡面的視覺內容與人的結構化知識相聯絡起來,提出了一種visual
knowledge memory network (VKMN)來將結構化知識與視覺特徵融合進端對端的學習框架。在經典VQA
資料集VQA v1.0與v2.0上在與知識推理相關的問題上取得不錯效果。

對於上圖這樣一個VQA範例,在視覺內容中並不存在Monkey這樣一種視覺物件,其需要外部知識來進行演
繹或者推理(deduction/reasoning)。
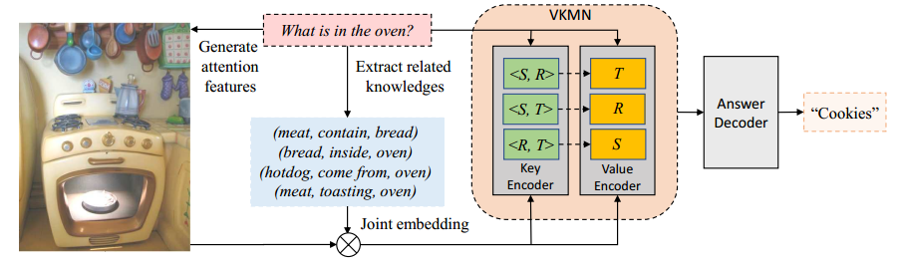
方法:
(1)Encoding of Image/Question Inputs
這兒值得關注的是其利用了MLB方法中的low-rank bilinear pooling對視覺特徵與文字特徵進行融合,對於
其它跨媒體問題也有一般性。
(2)Knowledge Spotting and Sub-graph Hashing
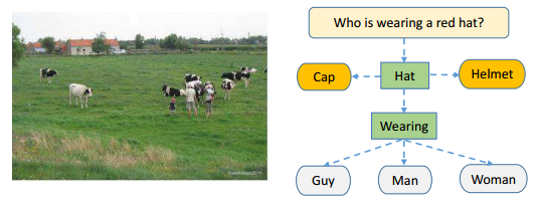
對於給定question,分析出相關實體與屬性,基於其構造的知識庫進行實體擴充套件,形成如上所示的triplet
關係群,作為Knowledge facts。
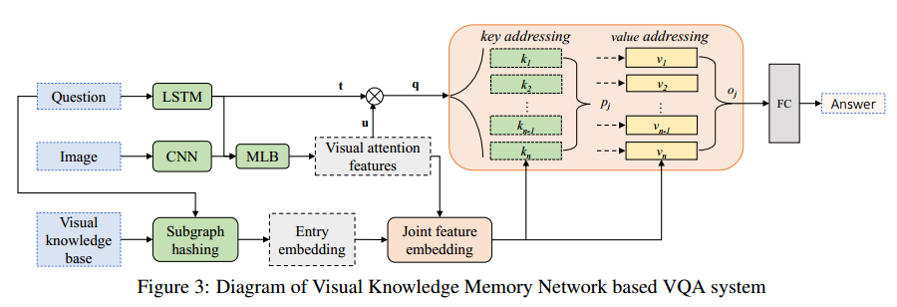
(3)Visual Knowledge Memory Network
對於triplet ,(即<主體,關係,客體>),構造Key-value這樣的鍵值對,因為VQA不確定對
中的哪一部分提問,故 , , 都可做為key,然後分別對key與value進行編碼。
這篇文章的memory機制的流程比較直觀與形象,簡述如下:
對於一個query(這在記憶機制中是個很關鍵的一點,很多非QA的問題,如果能很好地定義query也可引
入記憶機制,比如可往跨媒體檢索上面引),其與memory中的主鍵key進行相似度比較,然後進行value
的讀取,進行問題的回答。
Knowledge base:
本文自身構造了一個visual knowledge base,即知識條目triplet的構造其主要有兩種來源:
(1)從VQA v1.0中question與answer這樣的pair中抽取 。
(2)直接從現有的Visual Genome Relationship(VGR)中獲得knowledge triplet,通過這兩種方式構造自
己的視覺知識庫。
這篇文章的一些不足:
(1)雖然涉及memory的讀,但我發現其並沒有寫機制。
(2)triplet的擴充套件。該文是基於question中的實體與屬性,繼而在知識庫中進行關聯擴充套件,對於VQA中
視覺資訊的利用,該文僅僅只是提影象全域性特徵,其實另外一方面可以對圖片進行屬性/目標提取,與
前者question中分析出的概念共同作為query,來形成更為豐富與完備的知識條目。
實驗結果
baseline
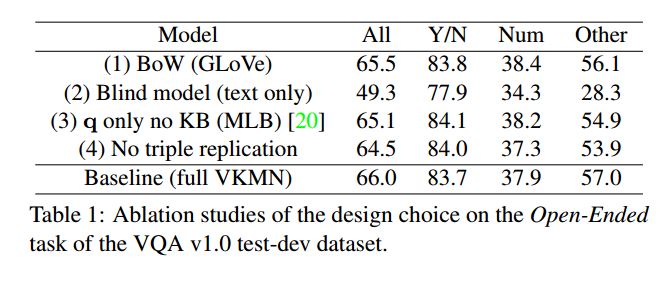
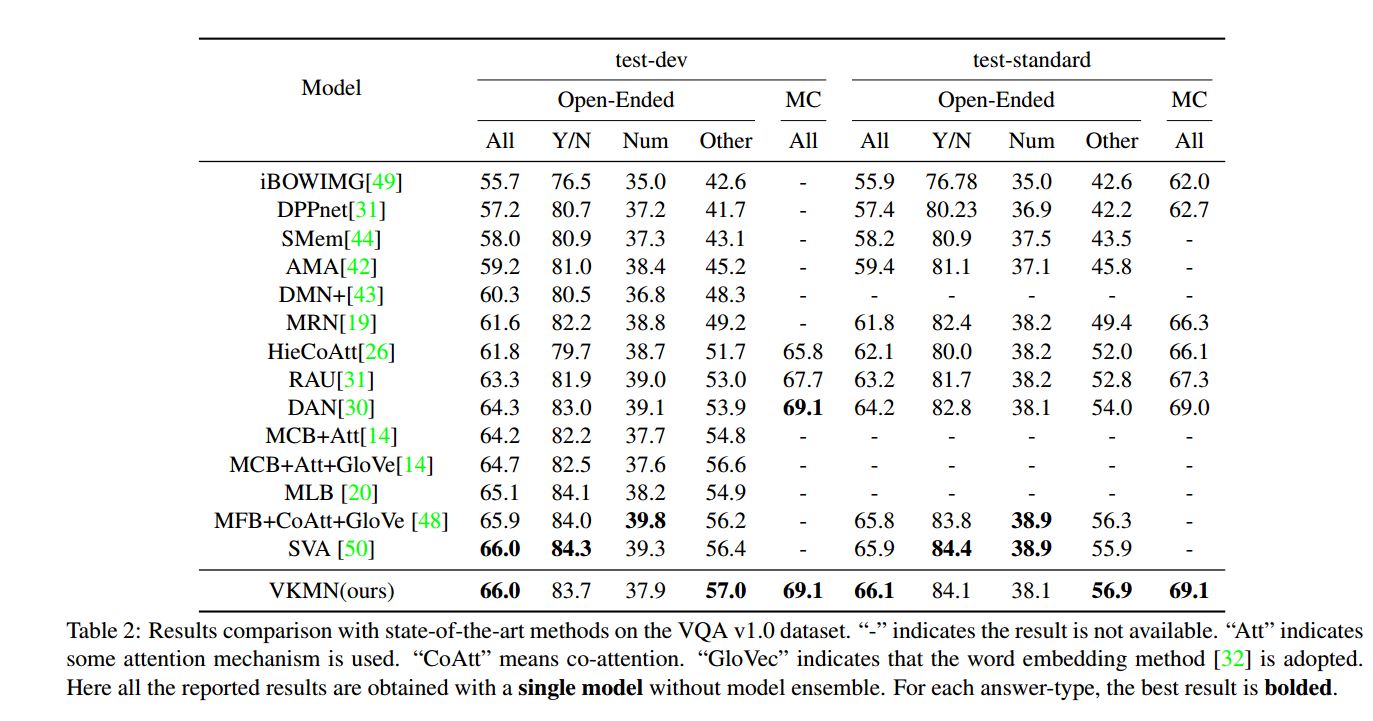
VQA 1.0
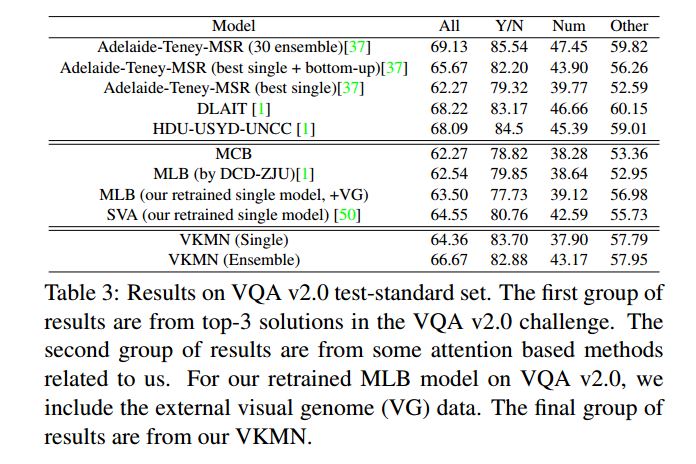
VQA 2.0
視覺化

參考原文:Learning Visual Knowledge Memory Networks for Visual Question Answering