論文筆記 Multiomdal Learning and Reasoning for Visual Question Answering (NIPS 2017)
阿新 • • 發佈:2018-12-11
文章的主要貢獻點如下:值得學習的是,文章的寫作挺好的。
文章的一個主要思想就是modular neural network,通過學習關於question與image的多模態(multimodal)與多方面(multifaceted)的表徵,在VQA1.與VQA2.0上取得不錯效果。

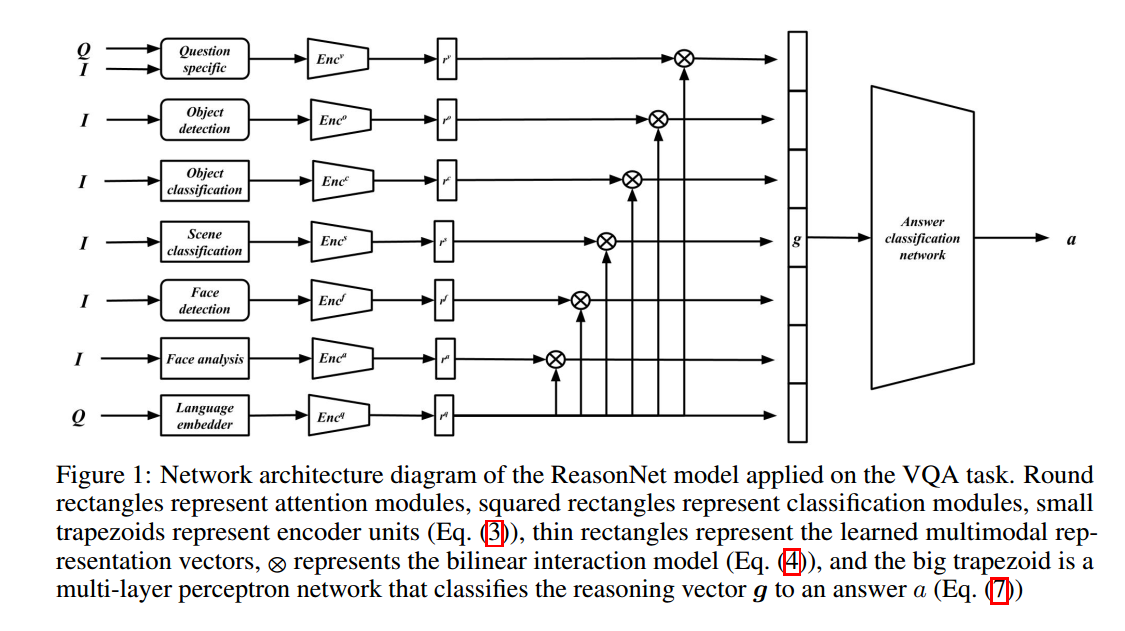
如上圖所示,主要分為6個module
(1)對resnet提出的
做question guided的attention,得到
(2)object detection檢測出的物體做attention,得到
,pretrained on existing work.
(3)object classification,其類別標籤文字,得到
,pretrained on COCO.
(4)scene classification,其類別標籤文字,得到
, pretrained on place365.
(5)face detection做attention,得到
, pretrained on existing face work.
(6)face根據gender,emotion,age分類標籤,得到
每個module的輸出分別於question進行bilinear互動,最終拼接成一個向量 ,作為分類的輸入。
Ablaion study
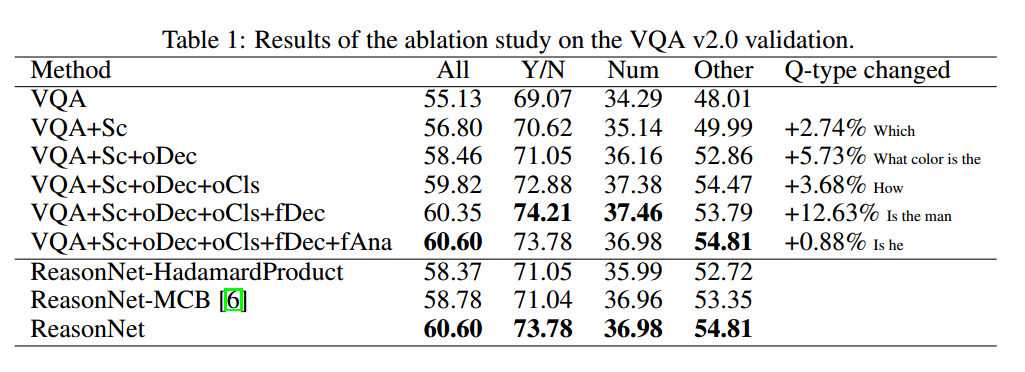
Comparing with state of the art