
深度學習論文翻譯解析(五):Siamese Neural Networks for One-shot Image Recognition
論文標題:Siamese Neural Networks for One-shot Image Recognition
論文作者: Gregory Koch Richard Zemel Ruslan Salakhutdinov
論文地址:https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
宣告:小編翻譯論文僅為學習,如有侵權請聯絡小編刪除博文,謝謝!
小編是一個機器學習初學者,打算認真研究論文,但是英文水平有限,所以論文翻譯中用到了Google,並自己逐句檢查過,但還是會有顯得晦澀的地方,如有語法/專業名詞翻譯錯誤,還請見諒,並歡迎及時指出。

摘要
為機器學習應用程式學習一個好的特徵的過程可能在計算上非常昂貴,並且在資料很少的情況下可能會變得困難。一個典型的例子就是一次學習設定,在這種情況下,我們必須僅給出每個新類的一個示例,就可以正確的做出預測。在本文中,我們探索了一種學習孿生神經網路的方法,該方法採用獨特的結構自然對輸入之間的相似性進行排名。一旦網路被調整好,我們就可以利用強大的判別功能,將網路的預測能力不僅用於新資料,而且適用於未知分佈中的全新類別。使用卷積架構,我們可以在單次分類任務上獲得近乎最先進的效能,從而超過其他深度學習模型的強大結果。

人類展現出強大的獲取和識別新模式的能力。特別是,我們觀察到,當受到刺激時,人們似乎能夠快速理解新概念,然後在將來的感知中認識到這些概念的變化(Lake等,2011)。機器學習已成功用於各種應用程式中的最先進效能,例如Web搜尋,垃圾郵件檢測,字幕生成以及語音和影象識別。但是,當被迫對幾乎沒有監督資訊的資料進行預測時,這些演算法通常會崩潰。我們希望歸納這些不熟悉的類別,而無需進行大量的重新培訓,由於資料有限或在線上預測設定(例如網路檢索)中,重新培訓可能即昂貴又不可能。

圖1:使用Omniglot 資料集進行20次單發分類任務的示例。孤獨的測試影象顯示在29張影象的網格上方,代表我們可以為測試影象選擇的可能看不見的型別。這20張圖片是我們每個類別中唯一已知的示例。


一個特別有趣的任務是在這樣的限制下進行分類:我們可能只觀察每個可能類的單一示例。這杯稱為單次學習,這是我們在該工作中提出的模型的主要重點(Fei-Feiet等,2006;Lake等,2011)。這應該與零散學習區分開來,在零散學習中,模型無法檢視目標類別中的任何示例(Palatucci等,2009)。
通過開發特定領域的功能或推理程式可以一直解決一次性學習的問題,這些功能或推理程式具有針對目標任務的高度區分性。結果,結合了這些方法的系統在類似情況下往往會表現出色,但無法提供可應用於其他類似問題的可靠解決方案。在本文中,我們提出了一種新穎的方法,該方法可以限制輸入結構的假設,同時自動獲取使模型能夠成功地從幾個示例中成功推廣的特徵。我們建立在深度學習框架的基礎上,該框架使用多層非線性來捕獲不變性以在輸入空間中進行變換,通常是通過利用具有許多引數的模型,然後使用大量資料來防止過度擬合(Bengio,2009;Hinton等,2006)。這些功能非常強大,因為我們可以在不強加先驗的情況下學習他們,儘管學習演算法本身的成本可能很高。
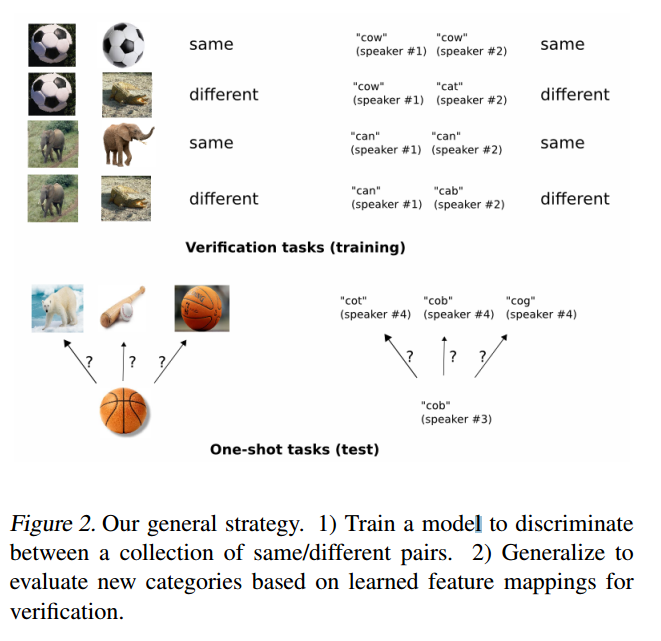
圖2,我們的總體策略。1)訓練模型以區分相同/不同對的集合。2)根據學習到的特徵對映進行概括以評估新類別,以進行驗證。


通常,我們通過具有監督性的基於度量的方法使用孿生神經網路來學習影象表示,然後將該網路的功能重新用於一次學習,而無需進行任何重新訓練。
在我們的實驗中,我們將注意力集中在字元識別上,儘管基本方法幾乎可以用於任何形式(圖二)。對於這個領域,我們使用大量的孿生卷積神經網路,其中a)能夠學習通用影象特徵,這些特徵對於做出關於未知類分佈的預測非常有用,即使這些新分佈中的例子很少。 b)使用標準優化技術對從元資料採用的對進行輕鬆訓練;c)通過利用深度學習技術,提供了一種不依賴於特定領域知識的競爭性方法。
要開發用於單次影象分類的模型,我們的目標是首先學習一個可以區分影象對的類身份的神經網路,這是影象識別的標準驗證任務。我們假設,在驗證方面表現出色的網路應該推廣到一鍵式分佈。驗證模型學習根據輸入對屬於相同類別或不同類別的可能性來識別輸入對。然後可以使用該模型以成對的方式針對測試影象評估新影象,每個新穎類恰好一個。然後根據驗證網路將得分最高的配對授予一次任務的最高概率。如果驗證模型學習到的特徵足以確認或拒絕一組字母中的字元的身份,那麼對於其他字母來說,他們應該就足夠了,只要該模型已暴露於各種字母中以鼓勵之間的差異學習的功能。



總體而言,對一次性學習演算法的研究還很不成熟,並且機器學習社群對此的關注還很有限。但是,本文之前還有一些關鍵的工作領域。
一鍵式學習的開創性工作可以追溯到2000年初的李飛飛等人。作者開發了一個變種的貝葉斯框架,用於 oneshot 影象分類,前提是在給定類別中只有很少的示例可用時,可以利用先前學習的類別來幫助預測未來的類別(Fe-Fei等,2003;Fei-Fei 等)等(2006)。最近,Lake等人。從認知科學的角度解決了一次性學習的問題,通過一種被稱為“層次貝葉斯程式學習”(HBPL)的方法解決了用於字元識別的一次性學習(2013)。在一系列的幾篇論文中,作者模擬了生成字元的過程,以將影象分解成小塊(Lake等,2011;2012)。HBPL的目標是確定所觀察畫素的結構說明。但是,由於聯合引數空間很大,因此在HBPL下進行推理很困難,從而導致難以解決的整合問題。
一些研究人員考慮了其他方法或轉移學習方法。湖等。最近有一些工作,該工作針對語言原語來識別未知說話者的新單詞(2014年)。Maas和Kemp在使用貝葉斯網路預測 Ellis Island 乘客資料的屬性(2009年)的著作中只有少數發表,Wu和Dennis在機器人制動的路徑規劃演算法的背景下解決了一次性學習(2012)。Lim著重研究如何通過調整衡量損失函式中的每個訓練樣本應加權每個類別多少的度量,來“借用” 訓練集中其他類別的示例。對於某些類別幾乎沒有示例的資料集,此想法可能很有用,它提供了一種靈活且連續的方式,將類別間資訊納入模型。

圖三,用於邏輯分類P的二進位制分類的簡單兩層孿生網路。網路的結構在頂部和底部進行復制,以形成雙胞胎網路,每一層都有共享的權重矩陣。

3,用於影象驗證的深度孿生網路
孿生網路由Bromley 和 LeCun 於 1990年代首次引入,以解決作為影象匹配問題的簽名驗證(Bromley等, 1993)。孿生神經網路由雙胞胎網路組成,該雙胞胎網路接受不同的輸入,但是在頂部由能量函式連線。此函式在每側的最高層特徵表示之間計算一些度量(圖3)。雙網之間的引數是繫結的,加權繫結保證了兩個及其相似的影象可能無法通過各自的網路對映到特徵空間中非常不同的位置,因為每個網路都計算相同的功能。而且,網路是對稱的,因此每當我們向雙胞胎網路呈現兩個不同的影象時,最上層的連線層將計算相同的度量,就像我們要呈現相同的兩個影象但像相對的雙胞胎一樣。


在LeCun等人中,作者使用了包含兩個項的對比能力函式,以減少相似對的能力並不相似對的能量(2005年)。但是,在本文中,我們使用雙特徵向量h1和h2之間的加權L1距離結合S型啟用,將其對映到區間 [0, 1]。因此,交叉熵目標是訓練網路的自然選擇。請注意,在LeCun等人中,他們直接學習了相似性指標,該相似性指標由能量損失隱式定義,而我們按照 Facebook DeepFace論文中的方法(Taigman等人,2014)固定了上述指標。我們效能最佳的模型在完全連線的層和頂級能量函式之前使用多個卷積層。在許多大型計算機視覺應用中,特別是在影象識別任務中,卷積神經網路已經取得了優異的成績(Bengio,2009; Krizhevsky等,2012; Simonyan&Zisserman,2014; Srivastava,2013)。

有幾個因素使卷積網路特別有吸引力。區域性連通性可以大大減少模型中的引數數量,從而固有的提供某種形式的內建正則化,儘管卷積層在計算上比標準非線性要貴。同樣,在這些網路中使用的卷積運算具有直接過濾的解釋,其中每個特徵圖都與輸入特徵進行卷積,以將模式識別為畫素分組。因此,每個卷積層的輸出對應於原始輸入控制元件中的重要控制元件特徵,併為簡單變換提供了一定的魯棒性。最後,現在可以使用非常快的CUDA庫來構建大型卷積網路,而無需花費大量的訓練時間(Mnih,2009年; Krizhevsky等人,2012年; Simonyan&Zisserman,2014年)。
現在,我們詳細介紹了孿生網路的結構以及實驗中使用的學習演算法的細節。


我們的標準模型時一個孿生卷積神經網路,每個L層都具有 N1 個單位,其中h1,l 代表第一個雙胞胎在 l 層中的隱藏向量, h2,l 代表第二隊雙胞胎的相同。我們在前 L-2 層中僅使用整流線性(ReLU)單元,而在其餘層中使用 S型單元。
該模型由一系列卷積層組成,每個卷積層使用單個通道,並具有大小可變且固定步長為1的濾波器。將卷積濾波器的數量指定為16的倍數以優化效能。網路將ReLU啟用功能應用於輸出特徵圖,還可以選擇在最大池化之後使用過濾器大小和跨度為2。因此,沒層中的第K個過濾器採用如下形式:

其中Wl-1 , l是第 l 層特徵圖的三維張量,我們採用 * 是有效的卷積運算,對應於僅返回哪些在每個卷積濾波器和輸入特徵圖之間完全重疊的結果的輸出單元。
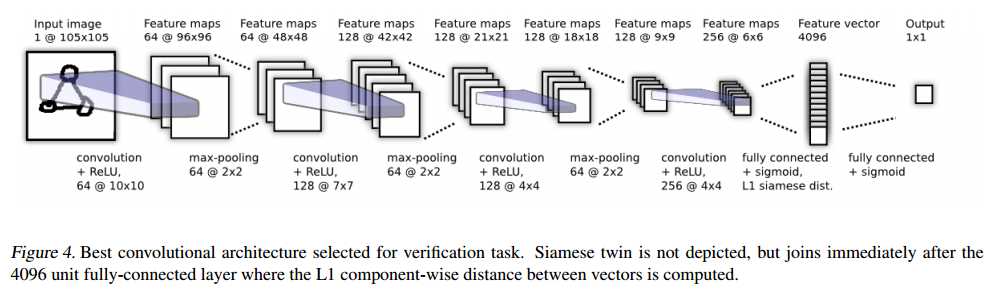
圖四,選擇用於驗證任務的最佳的卷積架構。沒有顯示連體雙胞胎,但在4096個單位的完全連線層之後立即加入連體,其中計算了向量之間的L1分量方向距離。

最終卷積層中的單位被展平為單個向量。該卷積層之後是一個完全連線的層,然後再一層計算每個孿生雙胞胎之間的感應距離度量,該距離度量被提供給單個S型輸出單元。更準確的說,預測向量為 P=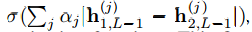 ),其中 其中σ是S型啟用函式。 最後一層在第 (L-1)隱藏層的學習特徵空間上引入度量,並對兩個特徵之間的相似性進行評分。αj是模型在訓練過程中學習的其他引數,加權了分量方向距離的重要性。這為網路定義了最後的 Lth全連線層,該層將兩個孿生雙胞胎相連。
),其中 其中σ是S型啟用函式。 最後一層在第 (L-1)隱藏層的學習特徵空間上引入度量,並對兩個特徵之間的相似性進行評分。αj是模型在訓練過程中學習的其他引數,加權了分量方向距離的重要性。這為網路定義了最後的 Lth全連線層,該層將兩個孿生雙胞胎相連。
我們在上面描述了一個示例(圖4),該示例顯示了我們考慮的模型的最大版本。該網路還為驗證任務中的任何網路提供了最佳結果。

3.2 Learning
損失功能:令M代表小批量的大小,其中 i 索引第 i 個小批量。現在讓 y(x1, x2) 是一個長度為M的向量,其中包括小批量的標籤,其中,當 x1 和 x2 來自同一字元類時,我們假設 y(x1, x2) =1 ,否則,我們在以下形式中的二進位制分類器上強加一個正規化的交叉熵目標:
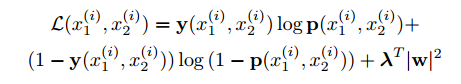


優化器:這個目標與標準的反向傳播演算法結合在一起,在該演算法中,由於權重的關係,整個雙子網路的梯度是相加的。我們將學習速率ηj,動量µj和L2正則化權重λj分層定義,從而將小批量大小固定為128,因此在時間點T的更新規則如下:
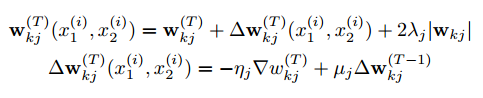
其中 ∇wkj 是相對於某層第 j 個神經元和連續層第 k 個神經元之間權重的偏導數。

權重初始化。我們從零均值和 10-2的標準差的正態分佈初始化卷積層中的所有網路權重。偏差也從正態分佈初始化卷積層中的所有網路權重。偏差也從正態分佈初始化,但平均值為 0.5,標準差為10-2。在完全連線的層中,以與卷積層相同的方式來初始化偏差,但是權重時從更寬的正態分佈中得出的,均值為零,標準差為 2*10-1。

學習時間表。儘管我們為每一層設定了不同的不學了,但是每個epoch的學習率在網路上均勻下降了 1%,因此 η(T)j =0.99η(T -1)j。 我們發現,通過對學習速率進行退火,網路能夠更輕鬆地收斂到區域性最小值,而不會陷入錯誤表明。我們將動量固定為每層從 0.5 開始,每個時代線性增加,直達達到值 j,即第 j 層的各個動量項。
我們對每個網路進行了最多200個epochs的訓練。但是監視了從驗證集中的字母和抽屜隨機生成的320個 oneshot 學習任務集中的一次驗證錯誤。當驗證錯誤在20個epochs內未減少時,我們根據一次驗證錯誤停止並在最佳時期使用模型的引數。如果在整個學習計劃中驗證錯誤繼續減少,我們將儲存此過程生成的模型的最終狀態。


超引數優化。我們仨還有貝葉斯優化框架Whetlab的Beta版來執行超引數選擇。對於學習計劃和正則化超引數,我們設定分層學習率ηj∈[10-4,10-1],分層動量µj∈[0,1]和分層L2正則化懲罰λj∈[0,0.1]。對於網路超引數,我們讓卷積濾波器的大小在3x3到20x20之間變化,而每層中的卷積濾波器的數量在16到256之間(使用16的倍數)變化。全連線層的範圍從128打破4096單位不等,也是16的倍數。我們將優化器設定為最大化一次驗證設定的準確性。分配給單個Whetlab迭代的分數是在任何時期發現的該指標的最高值。

仿射失真。此外,我們在訓練集上增加一些仿射失真(圖五)。對於每個影象對x1,x2,我們生成了一對仿射變換T1,T2,以產生x1 = T1(x1),x2 = T2(x2),其中T1,T2由多維均勻分佈隨機確定。 因此,對於任意變換T,我們有T =(θ,ρx,ρy,sx,sy,tx,tx),其中θ∈[−10.0,10.0],ρx,ρy∈[−0.3,0.3],sx, sy∈[0.8,1.2]和tx,ty∈[−2,2]。 轉換的每個這些分量都以0.5的概率包括在內。

圖5,Omniglot資料集中為單個字串生成的隨機放射失真的樣子


4,實驗
我們在首先描述的Omniglot資料集的子集上訓練了模型。然後我們提供有關驗證和單發性能的詳細資訊。
4.1 Omniglot 資料集
Omniglot資料集是由Brenden Lake及其同事在麻省理工學院通過亞馬遜的Mechanical Turk收集的,以產生一個標準的基準,可以從手寫字元識別領域的一些示例中學習(Lake等,2011)。1Omniglot包含了來自50個字母的示例從諸如拉丁語和韓語等公認的國際語言到鮮為人知的當地方言。它還包括一些虛構的字符集,例如Aurek-Besh和Klingon(圖6)。
每個字母中的字母數量從大約15個字元到最多40個字元不等。這些字母中的所有字元都是由20個抽屜中的每個抽屜一次生成的,Lake將資料分為40個字母背景集和10個字母評估集。我們保留這兩個術語是為了與可以從背景集生成的正常訓練,驗證和測試集區分開,以調整模型以進行驗證。背景集用於通過學習超引數和特徵對映來開發模型。相反,評估集僅用於測量單次分類效能。

圖6. Omniglot資料集包含來自世界各地字母的各種不同影象。


4.2 驗證
為了訓練我們的驗證網路,我們通過對隨機相同和不同的樣本對進行取樣,將三個不同的資料集大小與30000,90000和120000 個訓練示例放在一起。我們預留了總培訓資料的 60%:50個字母中的30個字母和20個抽屜的12個抽屜。
我們固定了每個字母的訓練樣本數量,以使每個字母在優化過程中都能得到相同的表示,儘管這不能保證每個字母中的各個字元類。通過新增仿射失真,我們還生成了與這些大小中的每個大小的增強版本相對應的資料集的附加副本。我們為每個訓練示例添加了八個變換,因此相應的資料集包含 270000,810000和1350000有效示例。

為了監控培訓期間的表現,我們使用了兩種策略。首先,我們建立了一個驗證集,用於從10個字母和4個其他抽屜中提取的10,000個示例對進行驗證。我們保留了最後10個字母和4個抽屜用於測試,在這裡我們將它們限制為與Lake等人使用的相同。 (Lake et al。,2013)。我們的其他策略是利用相同的字母和抽屜為驗證集生成一組320次單次識別試驗,以模擬評估集中的目標任務。實際上,確定停止時間的第二種方法至少與驗證任務的驗證錯誤一樣有效,因此我們將其用作終止標準。
在下表(表1)中,我們列出了六種可能的訓練集的最終驗證結果,其中列出的測試準確性在最佳驗證檢查點和閾值處報告。我們報告了六個不同訓練執行的結果,這些結果改變了訓練集的大小和切換的失真。
在圖7中,我們從驗證任務的前兩個效能最高的網路中提取了前32個濾波器,這些濾波器在具有仿射失真和圖3所示架構的90k和150k資料集上進行了訓練。過濾器之間的適應性,很容易看出某些過濾器相對於原始輸入空間承擔了不同的角色。
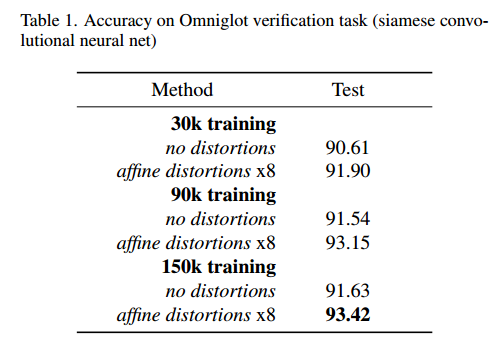
表一,Omniglot驗證任務的準確性(孿生卷積神經網路)

圖7,孿生網路學習到的第一層卷積濾波器的示例。通過過濾器具有不同的作用:一些過濾器尋找非常小的逐點特徵,而另一些過濾器則發揮更大的邊緣檢測器的作用。


4.3 單樣本學習
一旦我們優化了孿生網路以完成驗證任務,就可以在一次學習中展示我們所學功能的區分潛力。假設給定一個測試影象 X,我們希望將其分類為C類之一。我們還得到了其他一些影象{xc} C c = 1,這是代表這些C類中每個類別的列向量的集合。現在,我們可以使用 x, xc作為輸入查詢網路,範圍為C=1 ....... c2 然後預測與最大相似度相對應的類別。


為了憑經驗估計一次性學習成績,Lake開發了20種字母內部分類任務,其中首先從為評估集保留的字母中選擇一個字母,然後隨機抽取20個字元。還從評估抽屜池中選擇了二十個抽屜中的兩個。然後,這兩個抽屜將產生二十個字元的樣本。第一個抽屜產生的每個字元都表示為測試影象,並分別與第二個抽屜中的所有二十個字元進行比較,目的是從第二個抽屜的所有字元中預測與測試影象相對應的類別。圖7顯示了一次學習實驗的一個單獨示例。此過程對所有字母重複兩次,因此,十個評估字母表中的每一個都有40個一次學習試驗。這總共構成了400次單次學習試驗,由此計算出分類準確性。
表2給出了一次性結果。我們借鑑(Lake等人,2013)的基線結果與我們的方法進行比較。我們還包括來自具有兩個完全連線層的非卷積孿生網路的結果。
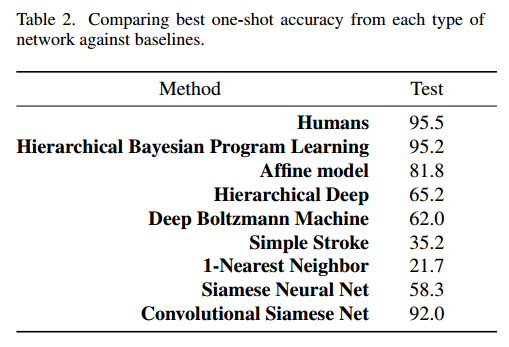
表2. 將每種型別的網路與基準的最佳單次準確度進行比較。


我們的卷積方法達到了92%,比HBPL本身以外的任何模型都強。 這僅略低於人為錯誤率。 雖然HBPL總體上顯示出更好的結果,但我們表現最好的卷積網路並未包含有關字元或筆觸的任何其他先驗知識,例如有關繪圖過程的生成資訊。 這是我們模型的主要優勢。

表3,MNIST 10 對1 單分類任務的結果

4.4 MNIST單分類訓練
Omniglot資料集包含少量樣本,用於每種可能的字母類別。因此,原始作者將其稱為“ MNIST轉置”,其類數遠遠超過訓練例項的數量(Lake等,2013)。我們認為監視在Omniglot上訓練的模型可以很好地推廣到MNIST會很有意思,在MNIST中,我們將MNIST中的10位數字視為字母,然後評估10向單發分類任務。我們遵循與Omniglot類似的程式,在MNIST測試集上進行了400次單次試驗,但不包括對訓練集的任何微調。所有28x28影象均被上取樣至35x35,然後提供給我們的模型的簡化版本,該模型在Omniglot的35x35影象上進行了訓練,這些影象被下采樣了3倍。我們還評估了此任務的最近鄰基線。
表3顯示了該實驗的結果。最近的鄰居基準提供與Omniglot相似的效能,而卷積網路的效能下降幅度更大。但是,我們仍然可以從Ominglot上學到的功能中獲得合理的概括,而無需對MNIST進行任何培訓。


5,總結
我們提出了一種通過首先學習深度卷積暹羅神經網路進行驗證來執行單發分類的策略。我們概述了將網路效能與為Omniglot資料集開發的現有最新分類器進行比較的新結果。我們的網路大大超越了所有可用的基準,並且接近先前作者所獲得的最佳數字。我們認為,這些網路在此任務上的強大效能不僅表明我們的度量學習方法可以實現人類水平的準確性,而且該方法應擴充套件到其他領域的單次學習任務,尤其是影象分類。
在本文中,我們僅考慮通過使用全域性仿射變換處理影象對及其失真來訓練驗證任務。我們一直在嘗試一種擴充套件演算法,該演算法利用有關單個筆劃軌跡的資料來產生最終的計算失真(圖8)。希望通過在筆劃上施加區域性仿射變換並將其覆蓋到合成影象中,我們希望我們可以學習更好地適應新示例中常見變化的特徵。

圖8.針對Omniglot中不同字元的兩組筆畫變形。 列描繪了從不同抽屜中抽取的字元。 第1行:原始圖片。 第2行:全域性仿射變換。 第3行:筆畫仿射變換。 第4行:在筆劃變換之上分層的全域性仿射變換。 請注意,筆畫變形如何會增加噪音並影響各個筆畫之間的空間關