
《Convolutional Neural Networks for Sentence Classification》論文結構解讀
阿新 • • 發佈:2018-12-09
1.資料
以某一雙鞋子為例,評論結果作為標籤(2分類:好評,差評)
【穿了一段時間,不錯,喜歡的下單吧;好評】
【鞋子收到了,不是很滿意。沒有吊牌,一直都是還是隻有我這一雙是;差評】
資料處理步驟:
把所有評論資料集分詞,去除停用詞,然後構建word2index,然後表示“句子”,以“穿了一段時間,不錯,喜歡的下單吧”為例子,分詞後為【穿了/一段/時間/,/不錯/,/喜歡/的/下單/吧】,則表示成【2/3/677/89/…】等等,這裡句子長度為10,如果某個詞作為停用詞去掉,比如“的”,則在詞彙表中對映不到index,用某個數字比如“0”填充。這裡不需要每個句子的長度都統一固定。因為Embedding層能處理。
2.Embedding層的處理
Embedding層把“資料處理步驟”後得到的評論表示【2/3/677/89/…】重新解析為one-hot的表示形式,如果【2/3/677/89/…】的長度為46,則表示為【46 x 詞彙表長度】,Embedding層的輸入為(詞彙表長度)個神經元,輸出為(向量的表示長度,假設是128)個神經元,這裡的Embedding層只有weight,沒有bias。即【46 x 詞彙表長度】則代表有46條資料,輸入Embedding層,最終的輸出為【46 x 128】。
3.CNN_Text 層
假設一條資料的句子長度為46,向量的表示長度128,則Embedding層的處理之後有46*128的一張“圖”。
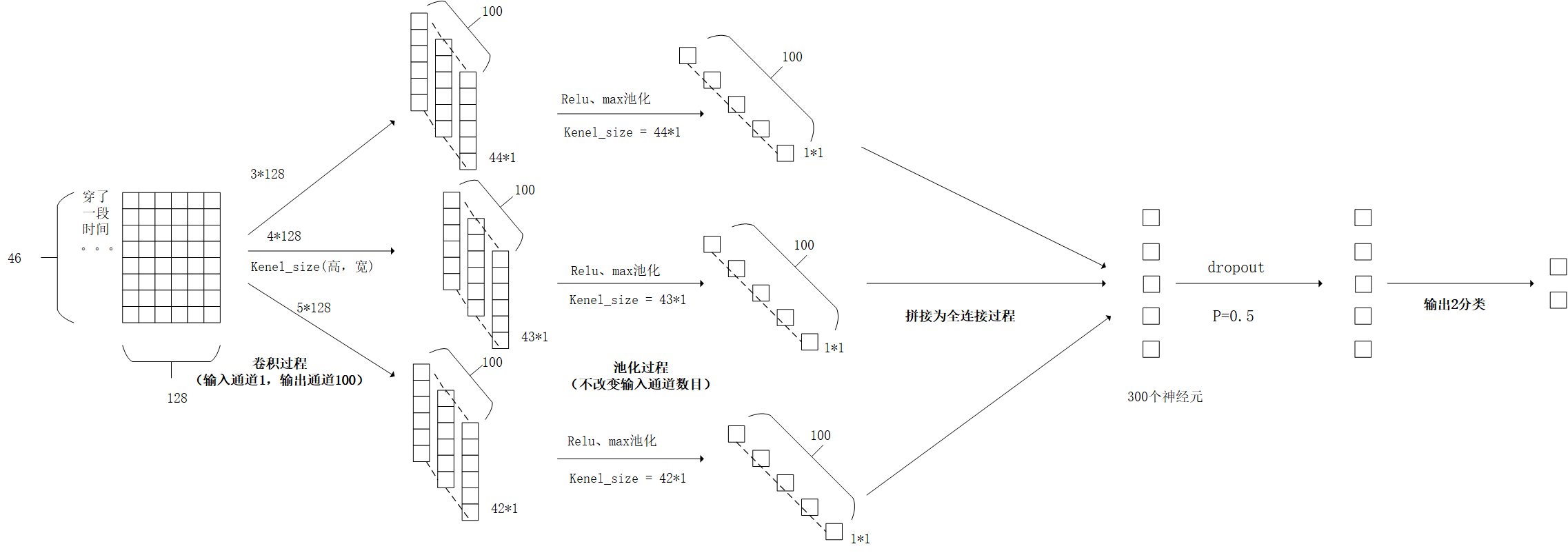
注意:假如下一條資料長度不是46,比如是68,則也是經過這個網路。所以,不需要固定句子長度。
參考
1.程式碼
2.《Convolutional Neural Networks for Sentence Classification》