
深度學習論文翻譯解析(十七):MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
論文標題:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
論文作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
論文地址:https://arxiv.org/abs/1704.04861.pdf
參考的 MobileNets 翻譯部落格:https://blog.csdn.net/qq_31531635/article/details/80508306
宣告:小編翻譯論文僅為學習,如有侵權請聯絡小編刪除博文,謝謝!
小編是一個機器學習初學者,打算認真研究論文,但是英文水平有限,所以論文翻譯中用到了Google,並自己逐句檢查過,但還是會有顯得晦澀的地方,如有語法/專業名詞翻譯錯誤,還請見諒,並歡迎及時指出。
如果需要小編其他論文翻譯,請移步小編的GitHub地址
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/DeepLearningNote


摘要
我們針對移動端以及嵌入式視覺的應用提出了一類有效的模型叫MobileNets。MobileNets 是基於一種流線型結構使用深度可分離卷積來構造權重深度神經網路。我們介紹兩個能夠有效權衡延遲和準確率的簡單的全域性超引數。這些超引數允許模型構造器能夠根據特定問題選擇合適大小的模型。我們在資源和準確率的權衡方面做了大量的實驗並且相較於其他在 ImageNet分類任務上著名的模型有很好的表現。然後,我們演示了MobileNets 在廣泛應用上的有效性,實驗例項包含目標檢測,細粒度分類,人臉屬性以及大規模地理位置資訊。


1,引言
自從著名的深度卷積神經網路 AlexNet 贏得 ImageNet競賽:ILSVRC 2012 之後,卷積神經網路普遍應用在計算機視覺領域。為了得到更高的準確率,普遍的趨勢是使網路更深更復雜。然而,這些在提升準確率的提升在尺寸和速度方面並不一定使網路更加有效。在大多現實世界應用中,比如機器人,無人駕駛和增強現實,識別任務需要在有限的計算平臺上實時實現。
本文描述了一個有效的網路結構以及兩組用於構建小型,低延遲模型的超引數,能在移動以及嵌入式視覺應用上輕易匹配設計要求。在第二節中回顧了現有構建小型模型的工作。第三節描述了MobileNet的結構以及兩種超引數-寬度乘法器(width multiplier)和解析度乘法器(resolution multiplier)來定義更小更有效的 MobileNets。第四節描述了在ImageNet上的實驗和大量不同的應用場景以及使用例項。第五節以總結和結論結束。

2,現有工作
近期已經有一些構造小而有效的神經網路的文獻,如SqueezeNet、Flattened convolutional neural networks for feedforward acceleration、Imagenet classification using binary convolutional neural networks、Factorized convolutional neural networks、Quantized convolutional neural networks for mobile devices。這些方法可以大概分為要麼是壓縮預訓練網路,要是直接訓練小型網路。本文提出一類神經網路結構允許特定模型開發人員對於其應用上可以選擇一個小型網路能匹配已有限制性的資源(延遲,尺寸)。MobileNets 首先聚焦於優化延遲,但也產生小型網路,許多文獻在小型網路上只聚焦尺度但是沒有考慮過速度問題。
MobileNets首先用於深度可分離卷積(Rigid-motion scattering for image classification中首先被提出)進行構建,隨後被用在Inception結構中(GoogLeNetv2)來減少首先幾層的計算量。Flattened Networks 構建網路運用完全分解的卷積並證明了極大分解網路的重要性。而 Factorized Networks介紹了一個相似的分解卷積和拓撲連線的視野。隨後,Xception Network描述瞭如何放大深度可分離濾波器來完成 InceptionV3網路。另一個小型網路是 SqueezeNet,使用 bottleneck 的方法來設計一個小型網路。


另一種不同的途徑就是收縮、分解、壓縮預訓練網路。基於乘積量化的壓縮(Quantized convolutional neural networks for mobile devices.)基於雜湊的壓縮(Compressing neural networks with the hashing trick)基於剪枝、向量量化、霍夫曼編碼的壓縮(Deep compression: Com- pressing deep neural network with pruning, trained quantiza- tion and huffman coding.)也被提出來。另外各種因子分解也被提出來加速預訓練網路(Speeding up convolutional neural networks with low rank expansions.)(Speeding-up convolutional neural net- works using fine-tuned cp-decomposition.)其他方法來訓練小型網路即為蒸餾法(Distillingtheknowledge in a neural network)即用一個大型的網路來教導一個小型網路。其於我們的方法相輔相成,在第4節中包含了一些我們的用例。另一種新興的方法即低位元網路(Training deep neural networks with low precision multiplications.)(Quantized neural networks: Training neural net- works with low precision weights and activations.)(Xnor- net: Imagenet classification using binary convolutional neu- ral networks.)。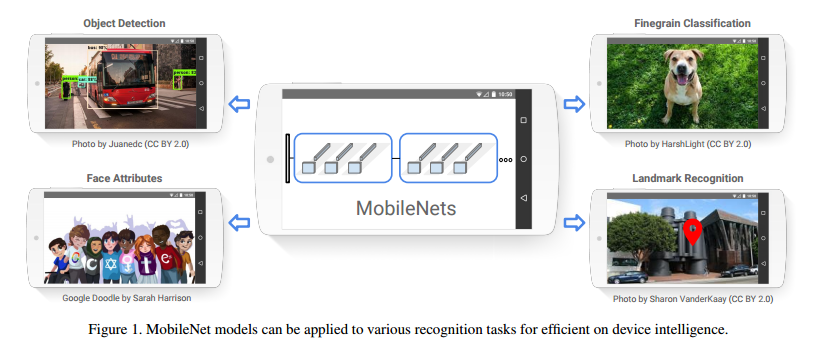

3,MobileNet 結構
本節首先描述MobileNet的核心部分也就是深度可分離卷積。然後描述MobileNet 的網路結構和兩個模型收縮超引數即寬度乘法器和解析度乘法器。
3.1 深度可分離卷積
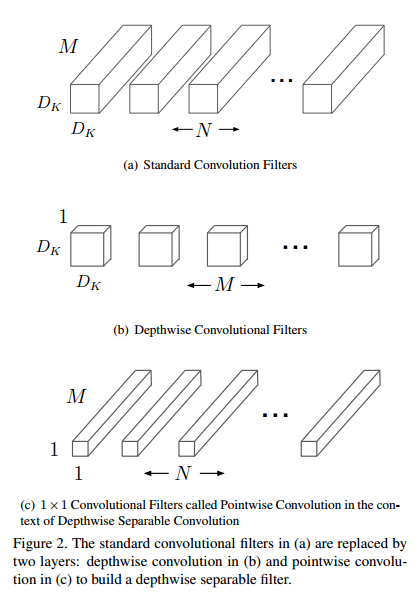
MobileNet 是一個基於深度可分離卷積的模型,深度可分離卷積是一種將標準卷積分解成深度卷積以及一個 1*1 的卷積即逐點卷積。對於Mobilenet 而言,深度卷積針對每個單個輸入通道應用單個濾波器進行濾波,然後逐點卷積應用 1*1 的卷積操作來結合所有深度卷積得到的輸出。而標準卷積一步即對所有的輸入進行結合得到新的一系列輸出。深度可分離卷積將其分為兩個部分,針對每個單獨層進行濾波然後下一步即結合,這種分解能夠有效地大量減少計算量以及模型的大小。如圖2所示,一個標準的卷積2(a)被分解成深度卷積2(b)和1*1的逐點卷積2(c)。
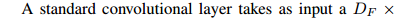




一個標準卷積層輸入 DF*DF*M 的特徵圖 F,並得到一個 DG*DG*N 的輸出特徵圖G,其中 DF 表示輸入特徵圖的寬和高,M是輸入的通道數(輸入的深度),DG 為輸出特徵圖的寬和高,N是輸出的通道數(輸出的深度)。
標準卷積層通過由大小為 DK*DK*M*N 個卷積核 K個引數,其中 DK 是卷積核的空間維數,M是輸入通道數,N是輸出通道數。
標準卷積的輸出的卷積圖,假設步長為1,則padding由下式計算:
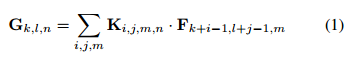
其計算量為:
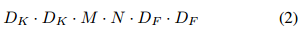
其由輸入通道數M,輸出通道數N,卷積核大小DK,輸出特徵圖大小DF 決定。MobileNet 模型針對其進行改進。首先,使用深度可分離卷積來打破輸出通道數與卷積核大小之間的相互連線作用。
標準的卷積操作基於卷積核和組合特徵來對濾波特徵產生效果來產生一種新的表示。濾波和組合能夠通過分解卷積操作來分成兩個獨立的部分,這就叫深度可分離卷積,可以大幅度降低計算成本。深度可分離卷積由兩層構成:深度卷積和逐點卷積。我們使用深度卷積來針對每一個輸入通道用單個卷積核進行卷積,得到輸入通道數的深度,然後運用逐點卷積,即應用一個簡單的 1*1 卷積,來對深度卷積中的輸出進行線性結合。MobileNets 對每層使用 batchnorm 和 ReLU 非線性啟用。
深度卷積對每個通道使用一種卷積核,可以寫成:
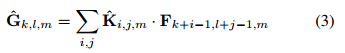
其中 Khat 是深度卷積核的尺寸 DK*DK*M,Khat 中第 m 個卷積核應用於 F 中的第 m個通道來產生第 m 個通道的卷積輸出特徵圖 Ghat。
深度卷積的計算量為:
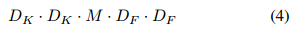
深度卷積相對標準卷積十分有效,然而其只對輸入通道進行卷積,沒有對其進行組合來產生新的特徵。因此下一層利用另外的層利用 1*1 卷積來對深度卷積的輸出計算一個線性組合從而產生新的特徵。
那麼深度卷積加上 1*1 卷積的逐點卷積的結合就叫做深度可分離卷積,最開始在(Rigid-motition scattering for image classification)中被提出。
深度可分離卷積的計算量為:
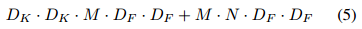
即深度卷積和 1*1 的逐點卷積的和。
通過將卷積分為濾波和組合的過程得到對計算量的縮減:
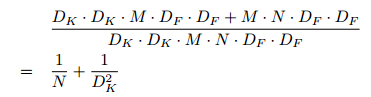 MobileNet 使用 3*3 的深度可分離卷積相較於標準卷積少了8~9倍的計算量,然而只有極小的準確率的下降如第四節。
MobileNet 使用 3*3 的深度可分離卷積相較於標準卷積少了8~9倍的計算量,然而只有極小的準確率的下降如第四節。
另外的空間維數的分解方式如(Flattenedconvolutional neural networks for feedforward acceleration)(Rethinking the inception architecture for computer vision.)中。但是相較於深度可分離卷積,計算量的減少也沒有這麼多。


3.2 網路結構和訓練
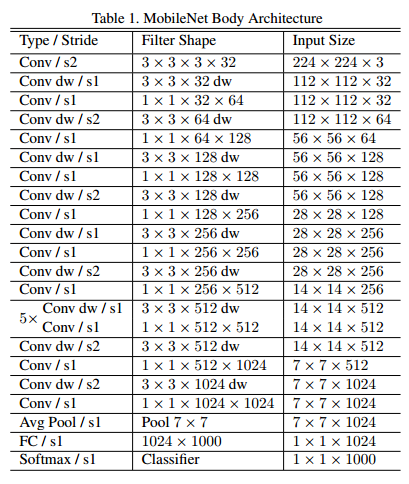
MobileNet 結構就像前面所提到的由深度可分離卷積所構成,且除了第一層之外為全卷積。通過用這些簡單的項定義網路能夠更容易的探索網路的拓撲結構來找到一個更好的網路。MobileNet結構由下表1定義。所有層跟著一個Batchnorm以及ReLU非線性啟用函式,除了最後一層全連線層沒有非線性啟用函式直接送入softmax層進行分類。下圖3比較了常規的卷積,Batchnorm,ReLU層以及分解層包含深度可分離卷積,1*1卷積,以及在每層卷積層之後的 Batchnorm 和 ReLU 非線性啟用函式。下采樣通過深度可分離卷積中第一層的深度卷積通過步長來進行控制,最後將卷積層中提取到的特徵圖經過全域性平均池化層降維到1維,然後送入全連線層分成 1000類。將深度卷積和逐點卷積做兩層,則MobileNet 含有 28層。
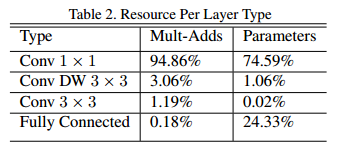
用這些少數的乘加運算來定義簡單的網路是不夠的。確保這些操作要十分有效也是非常重要的。例項化非結構稀疏矩陣操作除非有一個非常高的稀疏度,否則不一定比稠密矩陣操作更加快速。我們的模型結構幾乎將左右的計算量都放在稠密的 1*1 卷積中,這可以通過高度優化的 GEMM 通過矩陣乘法函式來實現。通常卷積由 GEMM(General Matrix Multiply Functions 的方式) 來實現,但是要求一個 im2col 即在記憶體中初始化重新排序來對映到 GEMM。比如,這個方法用在 caffe 模型架構中。而 1*1 卷積則不需要記憶體的重新排序,並且能直接用 GEMM方法實現,因此是最優化的數值線性代數演算法之一。MobileNet 95%的計算時間都花費在 1*1 的逐點卷積上,並且佔引數量的 75%,如表2所示。其他額外的引數幾乎都集中於全連線層。


MobileNet 模型在 TensorFlow框架中使用與 InceptionV3中一樣的 RMSprop 非同步梯度下降演算法,然而,與訓練大型網路不同的是,我們使用了非常少的正則化以及資料增強技術,因為小模型很少有過擬合的問題。當訓練 MobileNet時,我們沒有使用 side heads 或者標籤平滑操作,另外通過限制在大型 Inception 層訓練中小的裁剪的大小來減少失真圖片的數量。另外,我們發現在深度卷積中儘量不加入權重衰減(L2範數)是非常重要的,因為深度卷積中引數量很小。對於ImageNet 資料集,無論模型大小,所有的模型都被相同的超引數訓練模型,下一節來說明。



3.3 寬度乘法器:更薄的模型
儘管最基本的 MobileNet 結構已經非常小並且低延遲。而很多時候特定的案例或者應用可能會要求模型變得更小更快。為了構建這些更小並且計算量更小的模型,我們引入了一種非常簡單的引數 α 叫做寬度乘法器。寬度乘法器 α 的作用就是對每一層均勻薄化。給定一個層以及寬度乘法器 α,輸入通道數 M 變成了 αM 並且輸出通道數變成 αN。
加上寬度乘法器的深度可分離卷積的計算量如下:
 由於 α € (0, 1],一般設定為1, 0.75, 0.5, 0.25。當 α = 1 的時候就是最基本的 MobileNet,當 α <1 時,就是薄化的 MobileNet 。寬度乘法器對計算量和引數量的減少大約為 α2 倍。寬度乘法器可以應用在任何模型結構來定義一個更瘦的模型,並且權衡合理的精度,延遲的大小。寬度乘法器常用來薄化一個新的需要從頭開始訓練的網路結構。
由於 α € (0, 1],一般設定為1, 0.75, 0.5, 0.25。當 α = 1 的時候就是最基本的 MobileNet,當 α <1 時,就是薄化的 MobileNet 。寬度乘法器對計算量和引數量的減少大約為 α2 倍。寬度乘法器可以應用在任何模型結構來定義一個更瘦的模型,並且權衡合理的精度,延遲的大小。寬度乘法器常用來薄化一個新的需要從頭開始訓練的網路結構。


3.4 解析度乘法器:約化表達
第二個薄化神經網路計算量的超引數是解析度乘法器 Ρ 。我們將其應用在輸入圖片以及每一層的內部表達中。實際上,我們通過設定 P 來隱式的設定輸入的解析度大小。
我們現在可以對網路中的核心層的深度可分離卷積加上寬度乘法器 α 以及解析度乘法器 P 來表達計算量:
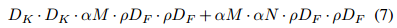
其中 P€ (0, 1],一般隱式的設定以便於輸入網路的影象解析度為 224/192/160/128 等。當 P=1 時為最基本的 MobileNet,當 P<1 時,則為薄化的 MobileNet。解析度乘法器對網路約化大約 P2 倍。
接下來舉個例子,MobileNet中的一個典型的層以及深度可分離卷積,寬度乘法器,解析度乘法器是如何約化計算量和引數量。表3中展示了一層計算量和引數量以及結構收縮的這些方法應用在這些層之後的變化。第一行顯示了全連線層的 Mult-Adds 和 引數量,其輸入特徵圖為 14*14*512,並且卷積核的尺寸為 3*3*512*512。我們將在下一節詳細闡述資源和準確率之間的權衡關係。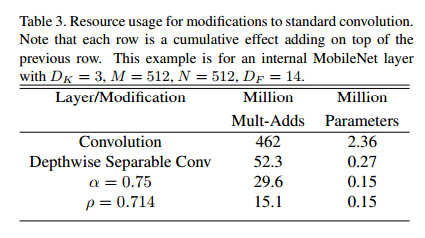


4,實驗
在這一節,我們首先調研了深度可分離卷積以及通過收縮網路的寬度而不是減少網路的層數帶來的影響。然後展示了基於兩個超引數:寬度乘法器和解析度乘法器,來收縮網路的權衡,並且與一些著名的網路模型進行了對比。然後調研了Mobilenet 運用在一些不同的應用上的效果。
4.1 模型選擇
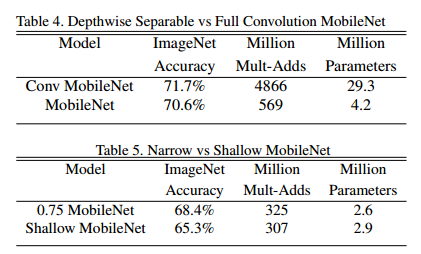
首先我們展示了運用深度可分離卷積的 MobileNet 與全標準卷積網路的對比,如表4,我們可以看見在 ImageNet 資料集上使用深度可分離卷積相較於標準卷積準確率只減少了 1%,但在計算量和引數量上卻減少了很多。
接下來,我們展示了利用寬度是乘法器的薄化模型與只有少數層的千層神經網路進行對比,為了使MobileNet 更淺,表1 中的 5層 14*14*512 的特徵尺寸的可分離卷積層都被去掉了。表 5 展示了相同計算量引數量的情況下,讓 Mobilenet 薄化 3% 比讓他更淺效果更好。

4.2 模型壓縮超引數
表6展示了利用寬度乘法器 α 對 MobileNet 網路結構進行薄化後準確率,計算量和尺寸之間的權衡關係。準確率直到寬度乘法器 α 下降到 0.25 才顯示下降很多。
表7展示了通過利用約化的 MobileNet 時不同解析度乘法器時準確率,計算量和尺寸之間的權衡關係。準確率隨著解析度下降而平滑減小。
圖4顯示了 16 個不同的模型在 ImageNet 中準確率和計算量之間的權衡。這 16 個模型由 4個不同的寬度乘法器{ 1.0, 0.75, 0.5, 0.25} 以及不同解析度 {112, 192, 160, 128}組成。當 α=0.25 時,模型變得非常小,整個結果呈現對數線性跳躍。
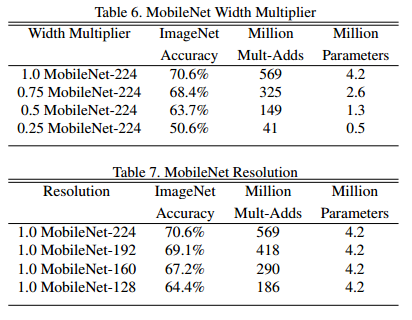
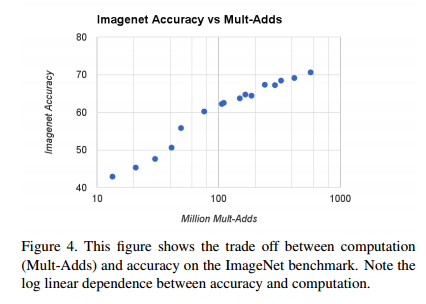

表5展示了 16 個不同模型在 ImageNet中準確率和引數量之間的權衡。這 16個模型由4個不同的寬度乘法器 { 1.0, 0.75, 0.5, 0.25} 以及不同解析度 {112, 192, 160, 128}組成。
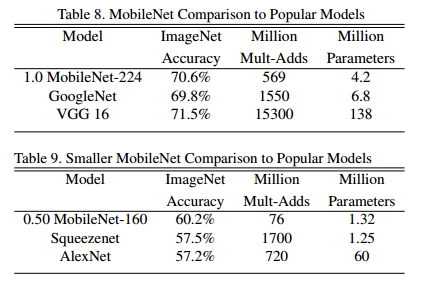
表8比較了最基本的 MobileNet 與原始 GoogLeNet 和 VGG16。MobileNet和VGG16準確率幾乎一樣,但是引數量少了 32 倍,計算量少了 27 倍。相較於 GoogLeNet而言,準確率更高,並且引數量和計算量都少了 2.5 倍。
表9比較了約化後的 MobileNet(α = 0.5,並且解析度為 160*160,原本為 224*224)與 AlexNet 以及 SqueezeNet,約化後的 MobileNet 相較於這兩個模型,準確率都高,並且計算量相較於 AlexNet 少了 9.4 倍,比 SqueezeNet 少了 22倍。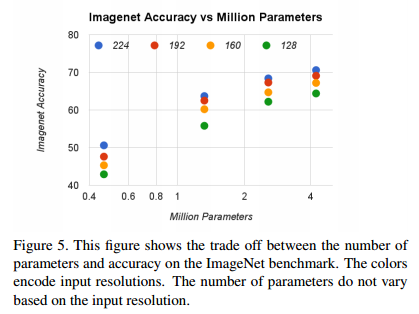

4.3 細粒度識別
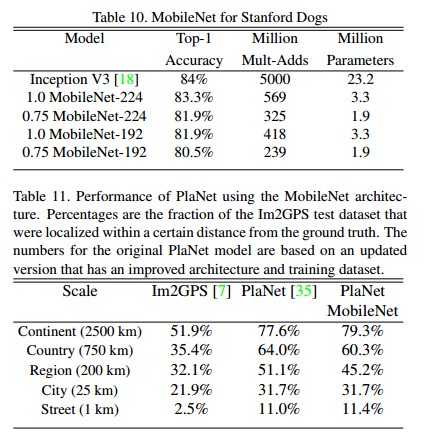
在斯坦福狗資料集在訓練 MobileNet 來進行細粒度識別。我們擴充套件了【18】中的方法,並且從網上收集了一個相對其更大,噪聲更多的訓練集,我們使用網上的噪聲資料集先預訓練一個細粒度識別狗的模型,然後在斯坦福狗資料集上進行精調。結果顯示在表 10 中。MobileNet 幾乎可以實現最好的結果,並且大大減少了計算量和尺寸。


4.4 大規模地理資訊
(PlaNet - Photo Geolocation with Convolutional Neural Networks)描述了在哪裡拍照是一個分類問題。這個方法將地球分割為地理網格作為目標類來利用數以百萬的地理標記圖片訓練一個卷積神經網路。PlaNet已經成功定位了大量照片,相對( IM2GPS: estimating geographic in- formation from a single image)(Large-Scale Image Geolocalization.)針對相同的任務,效果更好。
我們在相同資料集上利用MobileNet結構重新訓練PlaNet,因為PlaNet基於inceptionV3結構,其有5200萬引數以及5.74億的乘加計算量。而MobileNet只有1300萬引數量以及幾百萬的乘加計算量。在表11中,MobileNet相較於PlaNet只有少數準確率的下降,然而大幅度的優於Im2GPS。

4.5 人臉屬性
另一個MobileNet 的使用例項就是利用未知深奧的訓練過程來壓縮大型系統。在人臉屬性分類任務中,我們證明了MobileNet與蒸餾(一種針對深層網路的知識轉換理論)(Distilling the knowledge in a neural network)之間的協同關係。我們利用7500萬引數以及16億乘加運算計算量來約化一個大型人臉屬性分類器。這個分類器在一個類似於YFCC100M資料集(Yfcc100m: The new data in multimedia research.)上的一個多屬性資料集上訓練。
我們使用MobileNet結構提煉一個人臉屬性分類器。通過訓練分類器來蒸餾工作來模擬一個大型模型的輸出,而不是真實的標籤。因此能夠訓練非常大(接近無限)的未標記的資料集。結合蒸餾訓練的可擴充套件性以及MobileNet的簡約引數化,終端系統不僅要求正則化(權重衰減和早停),而且增強了效能。如表12中可以明顯看到基於MobileNet-base分類器針對模型收縮更有彈性變化:它在跨屬性間實現了一個相同的mAP但是隻用了僅1%的乘加運算。 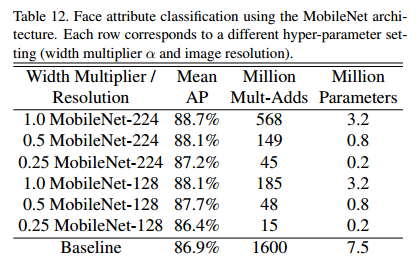


4.6 目標檢測
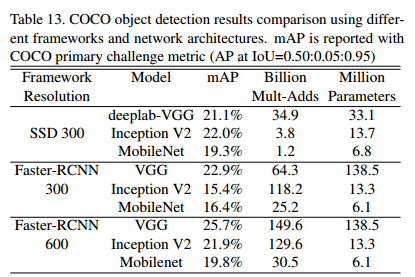
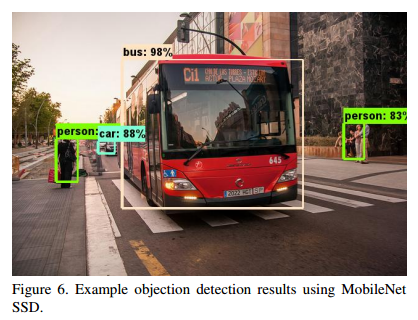
Mobilenet 也可以作為一個基本網路部署在現代目標檢測系統中。我們在COCO資料集上訓練得到結果並贏得 2016 COCO挑戰賽。在表13中,MobileNet與VGG和 InceptionV2在Faster-RCNN以及SSD框架下進行比較。在我們的實驗中,SSD由解析度為 300 的輸入圖片進行檢測,Faster-RCNN有 300 和 600 兩種解析度進行比較。Faster-RCNN模型每張圖片測試了300RPN 候選區域框,模型利用COCO的訓練和驗證集進行訓練,包含了 8000 張微縮圖片,並且在微縮圖片中進行測試。對於上述框架,MobileNet與其他網路進行比較,計算複雜度和模型尺寸相當於其他模型的一小部分。


4.7 人臉嵌入
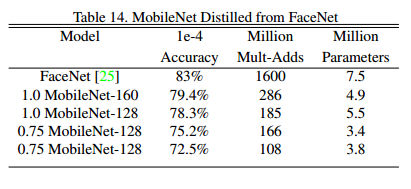
FaceNet 是藝術人臉識別模型中最好的。它構建了基於三次損失的人臉嵌入。為了構建移動端 Facenet 模型,我們在訓練集上通過最小化 FaceNet 和 MobileNet 之間的平方差來蒸餾訓練,結果展示在表14中。

5,總結
我們提出了一個新的模型基於深度可分離卷積網路結構 MobileNet。我們調研了一些重要的設計決策來引領一個有效的模型。然後我們描述瞭如何使用寬度乘法器和解析度乘法器通過權衡準確率來減少尺寸和延遲來構建更小更快的 MobileNet。然後將 MobileNet 與著名的模型在尺寸,速度和準確率上進行比較。我們總結了當 MobileNet 應用在各種任務中的有效性。下一步為了幫助探索 MobileNet 的更多改進和應用,我們計算在 TensorFlow 中加入 MobileNe