
隱語義模型LFM
1、概述
該演算法的理論基礎是運用矩陣分解,把使用者評分矩陣R分解為兩個低維矩陣,然後用這兩個低維矩陣去估計目標使用者對專案的評分。
傳統的協同過濾演算法是利用使用者的歷史行為,來預測使用者對目標使用者的評分。需要在整個使用者空間上去尋找最近鄰居。隨著電子商務的不斷髮展,使用者數量和物品的數量都呈指數型增長,這樣傳統的演算法就不能夠滿足推薦的實時需求。同時,傳統的協同過濾演算法只是考慮了使用者的歷史行為,而沒有考慮物品之間的關係。針對這些問題,本文提出了一種融合隱語義模型的聚類協同過濾演算法,區別於傳統的基於專案聚類的協同過濾[5],本文演算法沒有直接在使用者評分矩陣上進行聚類,而是先將評分矩陣進行分解,將得到的矩陣再進行聚類,這樣聚類的維度降低,同時還考慮了物品類別資訊,提高了推薦系統實時響應速度。
CF簡單直接可解釋性強,但隱語義模型能更好地挖掘使用者和item關聯中的隱藏因子。
2、SVD
隱語義模型涉及矩陣分解, 但是SVD的時間複雜度是O(m 3 ), 並且實際情況下,原矩陣大多數是缺失的,而我們對這些確實值預設給為0,SVD不太適合做推薦。
SVD是如何做推薦的呢?
A=UΣVT
U是“使用者-主題”相似矩陣;奇異值矩陣的對角元素是每一個主題的強度;V是“電影-主題”相似矩陣
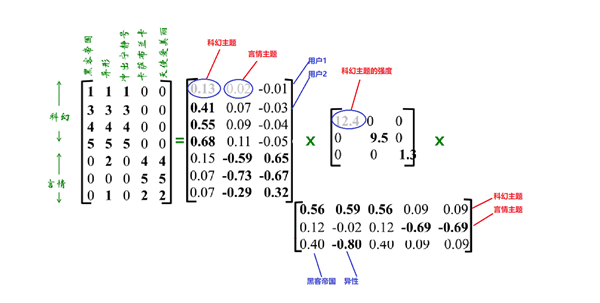
降維:
奇異值矩陣中,奇異值很小的值,說明主題的強度很小,可以忽略

如何衡量降維後的精確度?

保留多少奇異值?
奇異值的平方和一般在80%-90%
給使用者推薦電影:
d,q是使用者給電影的打分,V是“電影-主題”近似矩陣。
相乘得到的1×2維的矩陣的值代表使用者對每個主題的喜歡程度。
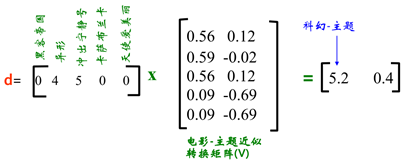

我們可以發現使用者d, q都對相同主題的電影感興趣,因此我們就可以互相推薦各自喜歡的電影。
3、矩陣分解
直接對原矩陣進行分解
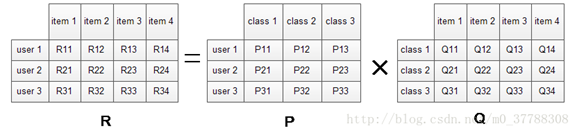
其中P矩陣是user-class矩陣,矩陣值Pij表示的是user i對class j的興趣度;Q矩陣式class-item矩陣,矩陣值Qij表示的是item j在class i中的權重,權重越高越能作為該類的代表
如何計算矩陣P和矩陣Q中的引數值。一般做法就是使用梯度下降法優化損失函式來求引數。
損失函式如下所示:
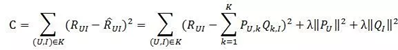
上式中的
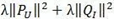
是用來防止過擬合的正則化項,λ需要根據具體應用場景反覆實驗得到。
損失函式的優化使用隨機梯度下降演算法:
1)對兩組未知數求偏導數
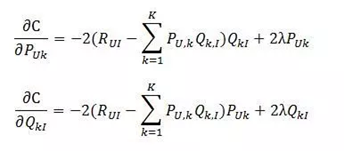
2)根據隨機梯度下降法得到遞推公式
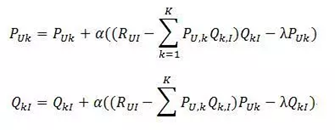
隱語義模型在實際使用中有一個困難,那就是它很難實現實時推薦。經典的隱語義模型每次訓練時都需要掃描所有的使用者行為記錄,這樣才能計算出使用者對於 每個隱分類的喜愛程度矩陣P和每個物品與每個隱分類的匹配程度矩陣Q。而且隱語義模型的訓練需要在使用者行為記錄上反覆迭代才能獲得比較好的效能,因此 LFM的每次訓練都很耗時,一般在實際應用中只能每天訓練一次,並且計算出所有使用者的推薦結果。從而隱語義模型不能因為使用者行為的變化實時地調整推薦結果 來滿足使用者最近的行為。
4、加bias的隱語義模型
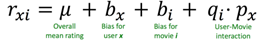
需要最小化
