
從零開始山寨Caffe·貳:主存模型
本文轉自:https://www.cnblogs.com/neopenx/p/5190282.html
從硬體說起
物理之觴
大部分Caffe原始碼解讀都喜歡跳過這部分,我不知道他們是什麼心態,因為這恰恰是最重要的一部分。
記憶體的管理不擅,不僅會導致程式的立即崩潰,還會導致記憶體的洩露,當然,這隻針對傳統CPU程式而言。
由於GPU的引入,我們需要同時操縱倆種不同的儲存體:
一個受北橋控制,與CPU之間架起地址匯流排、控制匯流排、資料匯流排。
一個受南橋控制,與CPU之間僅僅是一條可憐的PCI匯流排。
一個傳統的C++程式,在作業系統中,會被裝載至記憶體空間上。
一個有趣的問題,你覺得CPU能夠訪問視訊記憶體空間嘛?你覺得你的預設C++程式碼能訪問視訊記憶體空間嘛?
結果顯然是否定的,問題就在於CPU和GPU之間只存在一條資料匯流排。
沒有地址匯流排和控制匯流排,你除了讓CPU傳送資料拷貝指令外,別無其它用處。
這不是NVIDIA解決不了,AMD就能解決的問題。除非計算機體系結構再一次迎來變革,
AMD和NVIDIA的工程師聯名要求在CPU和GPU之間追加複雜的通訊匯流排用於異構程式設計。
當然,你基本是想多了。
環境之艱
可憐的資料匯流排,加大了異構程式設計的難度。
於是我們看到,GPU的很大一部分時鐘週期,用在了和CPU互相交換資料。
也就是所謂的“記憶體與視訊記憶體之間友好♂關係”。
你不得不接受一個事實:
GPU最慢的儲存體,也就是片外視訊記憶體,得益於鎂光的GDDR技術,目前家用遊戲顯示卡的訪存速度也有150GB/S。
而我們可憐的記憶體呢,你以為配上Skylake後,DDR4已經很了不起了,實際上它只有可憐的48GB/S。
那麼問題來了,記憶體如何去彌補與視訊記憶體的之間頻寬的差距?
答案很簡單:分時、非同步、多執行緒。
換言之,如果GPU需要在接下來1秒內,獲得CPU的150GB資料,那麼CPU顯然不能提前一秒去複製。
它需要提前3秒、甚至4秒。如果它當前還有其它序列任務,你就不得不設個執行緒去完成它。
這就是新版Caffe增加的新功能之一:多重預緩衝。
設置於DataLayer的分支執行緒,在GPU計算,CPU空閒期間,為視訊記憶體預先緩衝3~4個Batch的資料量,
來解決記憶體視訊記憶體頻寬不一致,導致的GPU時鐘週期浪費問題,也增加了CPU的利用率。
最終,你還是需要牢記一點:
不要嘗試以預設的C++程式碼去訪問視訊記憶體空間,除非你把它們複製回記憶體空間上。
否則,就是一個毫無提示的程式崩潰問題(準確來說,是被CPU硬體中斷了【微機原理或是計算機組成原理說法】)
程式設計之繁
在傳統的CUDA程式設計裡,我們往往經歷這樣一個步驟:
->計算前
cudaMalloc(....) 【分配視訊記憶體空間】
cudaMemset(....) 【視訊記憶體空間置0】
cudaMemcpy(....) 【將資料從記憶體複製到視訊記憶體】
->計算後
cudaMemcpy(....) 【將資料從視訊記憶體複製回記憶體】
這些步驟相當得繁瑣,你不僅需要反覆敲打,而且如果忘記其中一步,就是毀滅性的災難。
這還僅僅是GPU程式設計,如果考慮到CPU/GPU異構設計,那麼就更麻煩了。
於是,聰明的人類就發明了主存管理自動機,按照按照一定邏輯設計狀態轉移程式碼。
這是Caffe非常重要的部分,稱之為SyncedMemory(同步儲存體)。
主存模型
狀態轉移自動機
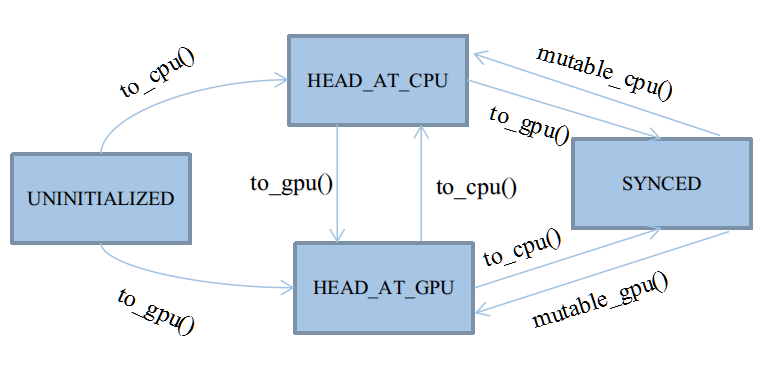
自動機共有四種狀態,以列舉型別定義於類SyncedMemory中:
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
這四種狀態基本會被四個應用函式觸發:cpu_data()、gpu_data()、mutable_cpu_data()、mutable_gpu_data()
在它們之上,有四個狀態轉移函式:to_cpu()、to_gpu()、mutable_cpu()、mutable_gpu()
前兩個狀態轉移函式用於未進入Synced狀態之前的狀態機維護,後兩個用於從Synced狀態中打破出來。
具體細節見後文,因為Synced狀態會忽略to_cpu和to_gpu的行為,打破Synced狀態只能靠人工賦值,切換狀態頭head。
後兩個mutable函式會被整合在應用函式裡,因為它們只需要簡單地為head賦個值,沒必要大費周章寫個函式封裝。
★UNINITIALIZED:
UNINITIALIZED狀態很有趣,它的生命週期是所有狀態裡最短的,將隨著CPU或GPU其中的任一個申請記憶體而終結。
在整個記憶體週期裡,我們並非一定要遵循著,資料一定要先申請記憶體,然後在申請視訊記憶體,最後拷貝過去。
實際上,在GPU工作的情況下,大部分主儲存體都是直接申請視訊記憶體的,如除去DataLayer的前向/反向傳播階段。
所以,UNINITIALIZED允許直接由to_gpu()申請視訊記憶體。
由此狀態轉移時,除了需要申請記憶體之外,通常還需要將記憶體置0。
★HEAD_AT_CPU:
該狀態表明最近一次資料的修改,是由CPU觸發的。
注意,它只表明最近一次是由誰修改,而不是誰訪問。
在GPU工作時,該狀態將成為所有狀態裡生命週期第二短的,通常自動機都處於SYNCED和HEAD_AT_GPU狀態,
因為大部分資料的修改工作都是GPU觸發的。
該狀態只有三個來源:
I、由UNINITIALIZED轉移到:說白了,就是欽定你作為第一次記憶體的載體。
II、由mutable_cpu_data()強制修改得到:都要準備改資料了,顯然需要重置狀態。
cpu_data()及其子函式to_cpu(),只要不符合I條件,都不可能轉移到改狀態(因為訪問不會引起資料的修改)
★HEAD_AT_GPU:
該狀態表明最近一次資料的修改,是由GPU觸發的。
幾乎是與HEAD_AT_CPU對稱的。
★SYNCED:
最重要的狀態,也是唯一一個非必要的狀態。
單獨設立同步狀態的原因,是為了標記記憶體視訊記憶體的資料一致情況。
由於類SyncedMemory將同時管理兩種主存的指標,
如果遇到HEAD_AT_CPU,卻要訪問視訊記憶體。或是HEAD_AT_GPU,卻要訪問記憶體,那麼理論上,得先進行主存複製。
這個複製操作是可以被優化的,因為如果記憶體和視訊記憶體的資料是一致的,就沒必要來回複製。
所以,使用SYNCED來標記資料一致的情況。
SYNCED只有兩種轉移來源:
I、由HEAD_AT_CPU+to_gpu()轉移到:
含義就是,CPU的資料比GPU新,且需要使用GPU,此時就必須同步主存。
II、由HEAD_AT_GPU+to_cpu()轉移到:
含義就是,GPU的資料比CPU新,且需要使用CPU,此時就必須同步主存。
在轉移至SYNCED期間,還需要做兩件準備工作:
I、檢查當前CPU/GPU態的指標是否分配主存,如果沒有,就重新分配。
II、複製主存至對應態。
處於SYNCED狀態後,to_cpu()和to_gpu()將會得到優化,跳過內部全部程式碼。
自動機將不再運轉,因為,此時僅需要返回需要的主存指標就行了,不需要特別維護。
這種安寧期會被mutable字首的函式打破,因為它們會強制修改至HEAD_AT_XXX,再次啟動自動機。