
從零開始山寨Caffe·捌:IO系統(二)
生產者
雙緩衝組與訊號量機制
在第陸章中提到了,如何模擬,以及取代根本不存的Q.full()函式。
其本質是:除了為生產者提供一個成品緩衝佇列,還提供一個零件緩衝佇列。
當我們從外部給定了固定容量的零件之後,生產者的產能就受到了限制。
由兩個阻塞佇列組成的QueuePair,並不是Caffe的獨創,它實際上是生產者與消費者的程式設計方式之一。
在大部分作業系統教材中,雙緩衝區free、full通常由兩個訊號量empty、full實現。
訊號量(Semaphore)由作業系統底層實現,並且幾乎沒有人會直接使用訊號量去程式設計。
因為在邏輯上,可以由訊號量可由mutex+計數器模擬得到。
訊號量的名字很有趣,它實際上由兩部分組成,訊號(啟用訊號)、量(計數器)。
漢語的博大精深恰當地詮釋的訊號量的語義精神,而從Semaphore中,你讀不出任何精華。
啟用訊號掩蓋了mutex的功與名,訊號量的第一大功能,就是mutex鎖。
量,顯然表明訊號量可以計數,實際上,訊號量經常會被拿來為臨界資源計數。
下面的虛擬碼摘自我的作業系統課本,《計算機作業系統 <第四版> 湯小丹等 著》:
int in=0,out=0; item buffer[n]; semaphore mutex=1,empty=n,full=0; void wait(S){ while(S<=0); S--; } void signal(S) {S++;} void producer{ while(1){ produce an item in nexp; ... wait(empty); wait(mutex); buffer[in]=nexp; in=(in+1)%n; signal(mutex); signal(full); } }
可以看到,除了mutex履行其互斥鎖的職責之外,empty和full用來計數。
作為生產者,每次生產時,都要讓empty減1,讓full加1。
當empty小於等於零時,形成第二把鎖,當然,這把鎖不是為了互斥,只是為了阻塞。
為了增加效率,這第二把鎖可以修改成條件阻塞,讓生產者交出CPU控制權,當然這需要作業系統的支援。
訊號量在現代程式設計中是多餘的,事實上,也沒有哪個執行緒庫會提供。
當"量"為1時,訊號量通常是去實現互斥鎖功能。
當"量"為臨界資源數量時,訊號量通常是去實現資源計數、並且條件阻塞的功能。
這兩部分的精神內涵都在Blocking Queue中實現了,So,忘記訊號量吧。
多生產者單緩衝區
作為一般的機器學習玩家,你是用不著考慮多生產者的。
如果你比較有錢,經常喜歡擺弄4-way泰坦交火,那麼就需要考慮一下多生產者的模型了。
在第肆章中,介紹了多GPU的基本執行原理,給出瞭如下這張圖:

對於每個GPU而言,它至少需要一個對它負責的DataReader,每個DataRedaer應當有不同的資料來源。
Caffe中,將控制一個數據來源的類物件稱為Body,預設有一個類靜態成員的Body關聯容器:
class DataReader { public: ..... private: static map<string, boost::weak_ptr<Body> > global_bodies; };
值得注意的是,此處應該使用weak_ptr,而不是shared_ptr,因為Body本身將由一個shared_ptr控制。
將Body的shared_ptr存入map容器,將會導致指標計數器永遠為1。
這樣,當我們準備將Body從map容器中清除時,無法獲知它是否已經被釋放。
而weak_ptr指向shared_ptr時,不會增加指標計數器計數,當計數為0時,即可將其從map裡清除。
每一個DataReader只能擁有一個Body,而每個Body可以有多個成品儲存緩衝區(非用於零件緩衝,下節講)。
每個Body控制一個數據來源,不同的資料來源可以用關鍵字來hash,預設Caffe提供的關鍵字是:
static string source_key(const LayerParameter& param){ return param.name() + ":" + param.data_param().source(); }
即Layer名,加上資料庫路徑。
多生產者主要用於多資料庫同時並行訓練,這是一種非常經典的模型。
一部分程式碼涉及到上層的DataLayer,將後續詳解。
另外一種模型是單生產者,以單資料庫,不同資料區域同時並行訓練,該方法也可以採用。(下節講)
Caffe的預設原始碼中,既沒有完整實現多生產者並行模型,也沒有完整實現單生產者並行模型,這點令人遺憾。
不過,從原始碼中仍然可以看出一點端倪,本教程只介紹大體思路,同樣並不提供具體程式碼。
單生產者多緩衝區
在這種模型下,將只有一個DataReader,一個Body,但是有多個Pair,如圖:
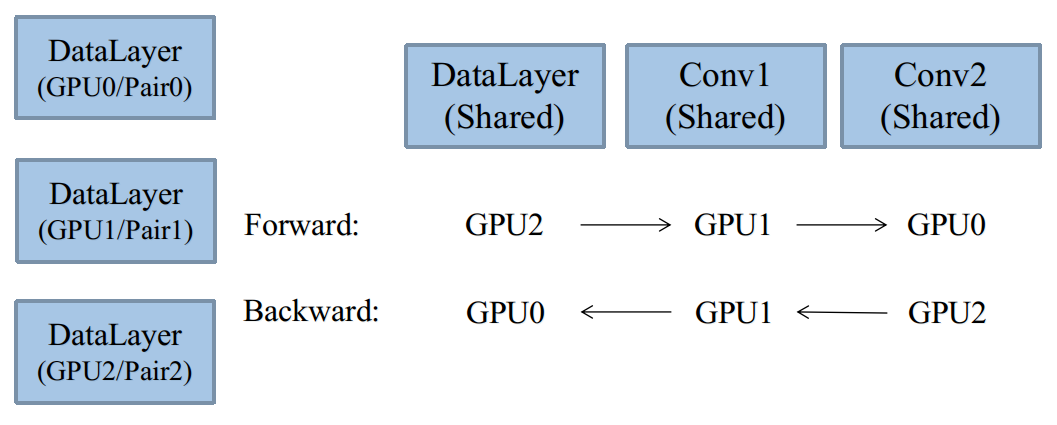
有趣的是,Body結構體中,提供了QueuePair陣列容器:
class Body :public DragonThread{ public: ....... BlockingQueue<boost::shared_ptr<QueuePair> > new_pairs; };
但是,Caffe原始碼中的DataReader,預設只會使用該容器陣列的第一個QueuePair,並沒有完整實現多緩衝區:
class DataReader { public: DataReader(const LayerParameter& param){ ........ ptr_body->new_pairs.push(ptr_pair); } BlockingQueue<Datum*>& free() const { return ptr_pair->free; } BlockingQueue<Datum*>& full() const { return ptr_pair->full; } private: boost::shared_ptr<QueuePair> ptr_pair; boost::shared_ptr<Body> ptr_body; };
可以看到,儘管我們設定了Body,儲存多個QueuePair,但是提供的外部訪問介面,居然直接使用了ptr_pair。
當然,如果你要程式設計使用多緩衝區,一定要修改DataReader的訪問介面。
對於單個數據庫的順序資料讀取,如何將順序資源,平攤到多個緩衝區?
Caffe使用了迴圈讀取法:
void Body::interfaceKernel(){ boost::shared_ptr<DB> db(GetDB(param.data_param().backend())); db->Open(param.data_param().source(), DB::READ); boost::shared_ptr<Cursor> cursor(db->NewCursor()); vector<boost::shared_ptr<QueuePair> > container; try{ ............... while (!must_stop()){ for (int i = 0; i < solver_count; i++) read_one(cursor.get(), container[i].get()); } } catch (boost::thread_interrupted&) {} }
可以看到,在Body的執行緒函式中,利用全域性管理器提供的solver_count,迴圈均攤資料到多個QueuePair中。
當你將solver_count設定成大於1時,將可以使用Body中的多個緩衝區QueuePair,這點需要注意。
單生產者單緩衝區(預設程式碼)
仔細思考一下,就會發現,單生產者多緩衝區方案是毫無意義的,看起來我們似乎模擬了多緩衝區。
但是實質只是一個執行緒,把資源分了一下組,多個組在DataLayer進行消費的時候,又會被合併成一個Batch:
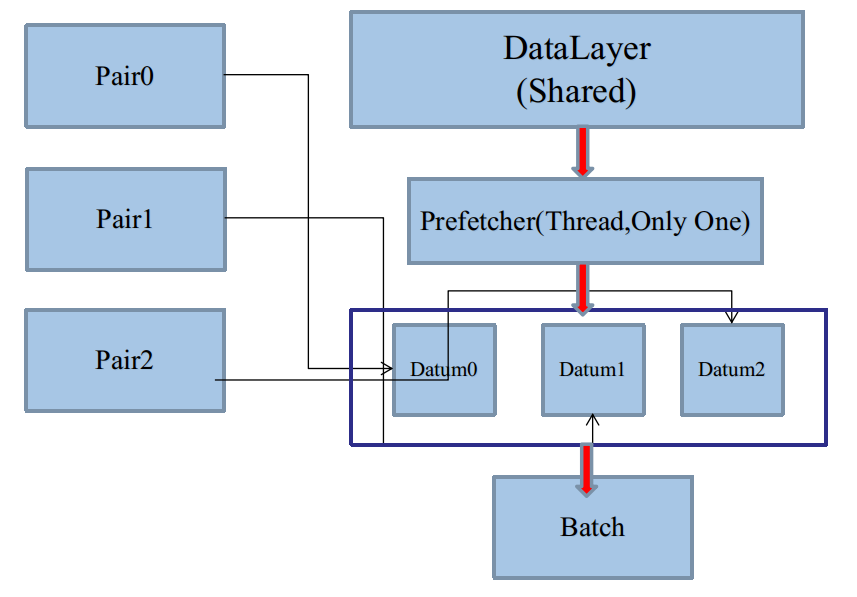
如圖,因為一個DataLayer只能有一個Prefetching Thread,所以必然是每次從各個Pair裡取一次。
如果我們先把Pair0取完,再取Pair1,再取Pair2,這樣也是可以的,是一種不錯的shuffle,但是需要追加程式碼。
從計算角度分析,多緩衝區不會加速,反而會減速,如果是為了做上述的shuffle,是情有可原的。
如果不是,只是單純地為了負載均衡,輪流從各個Pair裡取,那麼本質上,就會退化成單生產者單緩衝區。
————————————————————————————————————————————————————
這可能是Caffe原始碼的本意。在這種方案中,DataReader和DataLayer是無須改動程式碼的。
只要我們加大DataParameter裡的prefech數值,讓CPU多緩衝幾個Batch,為多個GPU準備就好了。
三種速度方案排名:
多生產者單緩衝區>單生產者單緩衝區>單生產者多緩衝區
執行緒巢狀執行緒與Socket
Caffe的原始碼真的很有啟發性,在DataReader的構造和解構函式中,可以發現貢獻者悄悄加了mutex:
DataReader::DataReader(const LayerParameter& param){ ...... boost::mutex::scoped_lock lock(bodies_mutex); ...... } DataReader::~DataReader(){ ...... boost::mutex::scoped_lock lock(bodies_mutex); ...... }
熟悉C++的人應該知道,在常規情況下,構造和解構函式是不會並行執行的,也就是不會被執行緒執行。
執行緒並行的僅僅是工作函式,工作之前主程序構造,工作之後,主程序析構。
如果偏要認為構造和析構可能並行的話,那麼將出現一種好玩的情況:
由於DataReader本身是執行緒,執行緒並行執行緒,將導致執行緒巢狀執行緒。
在我的作業系統課上,我的老師這麼說:
執行緒僅僅擁有程序的少部分資源,許可權很小。
那麼執行緒能夠巢狀執行緒麼?經過百度之後,我發現真還可以。
當今的作業系統,無論是Linux,還是Windows,執行緒的資源許可權都是非常大的。
————————————————————————————————————————————————————
執行緒巢狀執行緒,會不會和多GPU有關?我認為無關。
每個GPU的監督執行緒,這裡我們假設使用DragonThread,在需要工作時,
只需要傳入:Solver::solve函式就可以了,Solver、Net、Layer的構造和析構,顯然是在主程序裡執行的。
那麼,執行緒巢狀執行緒,有什麼意義,有什麼情況是必須線上程裡觸發建構函式?
很有趣,一般來講,只有Socket執行緒是這樣的。
Socket執行緒無須使用DragonThread,實際上,Boost的Socket也是由boost::asio而不是boost::thread實現的。
不像多GPU,我們無法預估,在某一時刻,實際有多少個Socket在執行,有多少個使用者發出了訪問請求。
因此,不能直接把Solver、Net、Layer的構造,放在主程序當中。不然你知道你要構造多少份嘛?顯然你不知道。
所以,從直覺上,將這些的構造,放在每一個啟動的Socket執行緒裡,用多少,構造多少,看起來不錯,如圖:
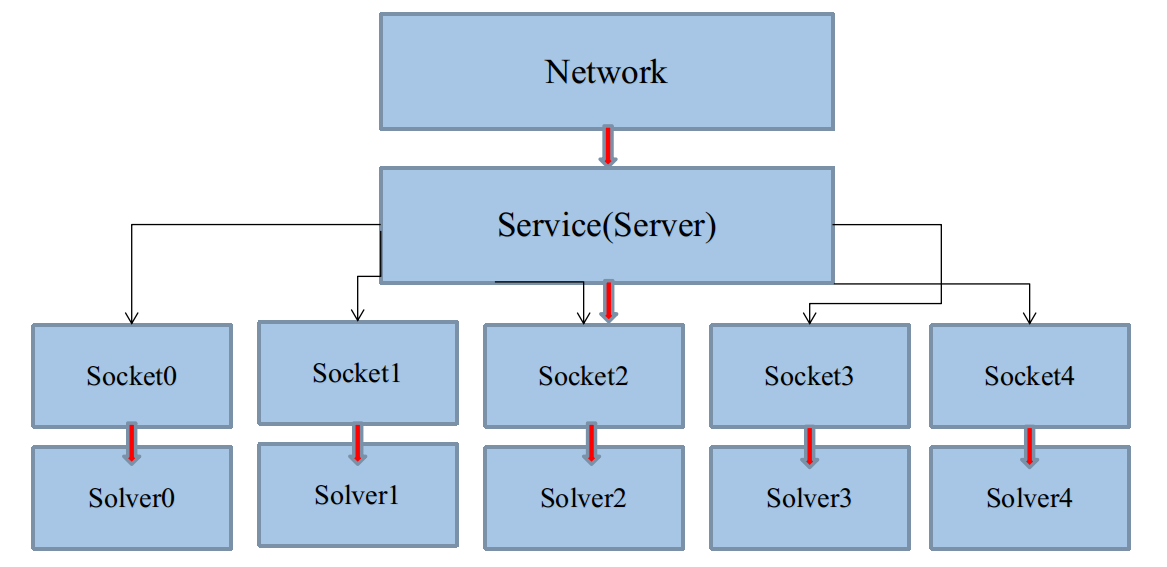
這樣,假如這幾個Solver使用了不同資料來源,那麼global_bodies就有被幾個Solver同時修改的可能。
這是構造和解構函式裡,需要加mutex的直接原因。
————————————————————————————————————————————————————
Socket的意義何在?
①從訓練角度,多個使用者可以遠端操控一臺主機,訓練不同的Net。
這點與多GPU訓練一個模型是不一樣的。一般而言,我們不會認為,多個使用者通過Socket,居然想要訓練同一個模型。
當然,這也是可以的。
②從測試角度,多個使用者,可以利用同一個Net的引數,並行得到自己提供的資料的測試結果。
注意,這樣就不要share整個Net,每個使用者的solver使用獨立的Net,獨立讀取訓練好的引數。
否則,多個使用者會在一個Net上卡半天。
程式碼實戰
建立data_reader.hpp、data_reader.cpp。
QueuePair
class QueuePair{ public: QueuePair(const int size); ~QueuePair(); BlockingQueue<Datum*> free; // as producter queue BlockingQueue<Datum*> full; // as consumer queue };
QueuePair的結構在上一章已經介紹過,每一個QueuePair將作為一個緩衝區。
QueuePair只需要實現建構函式和解構函式:
QueuePair::QueuePair(const int size){ // set the upbound for a producter for (int i = 0; i < size; i++) free.push(new Datum()); } QueuePair::~QueuePair(){ // release and clear Datum *datum; while (free.try_pop(&datum)) delete datum; while (full.try_pop(&datum)) delete datum; }
在建構函式中,我們進行"零件"的填充,注意裡面的Datum全是空元素,且存入佇列的應該是指標。
切記勿存入實體物件Datum,這在應用程式開發中是大忌,因為C++並非Python,預設執行的深拷貝。
深拷貝大記憶體資料結構體,會嚴重拖慢程式執行,而且還是沒有意義的,傳遞指標更恰當。
在解構函式中,實際上這是唯一一處對Protocol Buffer物件的主動析構,因為Datum沒有用shared_ptr。
主動析構主要利用Blocking Queue提供的try,來控制迴圈進度。
此處切記不要把pop寫成peek,否則會造成對空指標的delete,導致程式崩潰。
LayerParameter
DataReader的上層是DataLayer,它是DataLayer的成員變數之一,需要DataLayer提供proto引數。
在你的proto指令碼中,追加如下項:
message DataParameter{ enum DB{ LEVELDB=0; LMDB=1; } optional string source=1; optional uint32 batch_size=2; optional DB backend=3 [default=LMDB]; //4-way pre-buffering is enough for normal machines optional uint32 prefech=4 [default=4]; } message LayerParameter{ optional string name=1; optional string type=2; optional DataParameter data_param=8; }
重新編譯後,覆蓋你的舊標頭檔案和原始檔。
DataParameter中,包含:資料庫源路徑、batch大小、資料庫型別,以及預緩衝區大小。
比較特別的是預緩衝大小,預設是開4個Batch的預緩衝。如果你的GPU計算速度過快,明顯大於
CPU供給資料的速度,消費者(DataLayer)經常提示缺資料,你得考慮加大預緩衝區數量。
將DataParameter嵌入到LayerParameter中去。
LayerParameter是一個巨型的資料結構,將包含所有型別Layer的超引數,你可以將其視為基類。
Body
class Body :public DragonThread{ public: Body(const LayerParameter& param); virtual ~Body(); vector<boost::shared_ptr<QueuePair>> new_pairs; protected: void interfaceKernel(); void read_one(Cursor *cursor, QueuePair *pair); LayerParameter param; };
Body實際上是一個執行緒,而DataReader卻不是,儘管Body是DataReader成員變數。
Body的建構函式和解構函式就是啟動執行緒和停止執行緒:
Body::Body(const LayerParameter& param) :param(param) { startThread();} Body::~Body() { stopThread();}
執行緒工作函式比較複雜:
void Body::interfaceKernel(){ boost::shared_ptr<DB> db(GetDB(param.data_param().backend())); db->Open(param.data_param().source(), DB::READ); boost::shared_ptr<Cursor> cursor(db->NewCursor()); try{ // default solver_count=1 int solver_count = param.phase() == TRAIN ? Dragon::get_solver_count() : 1; // working period while (!must_stop()){ for (int i = 0; i < solver_count; i++) read_one(cursor.get(), new_pairs[i].get()); } // complex condition } catch (boost::thread_interrupted&) {} }
該函式將會一直卡在迴圈裡,直到訓練結束,Body執行解構函式,將執行緒執行停止。
Body-DataReader構成了Caffe資料緩衝的第一級別:資料庫->Datum 。
在DataLayer中,還會進行第二級別的緩衝:Datum->Blob->Batch,將在後續分析。
最後,還剩下一個read_one函式:
void Body::read_one(Cursor *cursor, QueuePair *pair){ Datum *datum = pair->free.pop(); datum->ParseFromString(cursor->value()); pair->full.push(datum); cursor->Next(); if (!cursor->valid()){ DLOG(INFO) << "Restarting data prefeching from start.\n"; cursor->SeekToFirst(); } }
read_one每次從一個雙緩衝組的free佇列中取出空Datum指標。
利用Protocol Buffer的反序列化函式ParseFromString,從資料庫中還原Datum,再扔到full佇列裡。
感謝Protocol Buffer,否則這部分的程式碼估計不下200行。
當資料庫跑完之後,需要回到開頭,再次重讀,為迭代過程反覆提供資料。
這一步只適合訓練過程,如果你要一次測試自己的資料,請忘記這個函式,重寫一個不要反覆讀的版本。
DataReader
class DataReader { public: DataReader(const LayerParameter& param); BlockingQueue<Datum*>& free() const { return ptr_pair->free; } BlockingQueue<Datum*>& full() const { return ptr_pair->full; } ~DataReader(); static string source_key(const LayerParameter& param){ return param.name() + ":" + param.data_param().source(); } private: LayerParameter param; boost::shared_ptr<QueuePair> ptr_pair; boost::shared_ptr<Body> ptr_body; static map<string, boost::weak_ptr<Body> > global_bodies; };
該結構上文已經全面解析過。
在cpp的實現中,首先完成類靜態成員變數的外部初始化。
map<string, boost::weak_ptr<Body> > DataReader::global_bodies;
以及一個靜態mutex的定義:
static boost::mutex bodies_mutex;
該mutex是Caffe挖的坑之一,雖然預設不會生效,倒是給出了不錯的指導。
當構建多生產者單緩衝區時,我們將會有多個Body,即多個DataReader,即多個DragonThread。
這意味著,Body的Hash容器將成為一個互斥資源。
該Hash容器的存在不是沒有必要的,由於:
每個資料來源只能用一次,為了避免重複路徑,顯然需要Hash。
DataReader::DataReader(const LayerParameter& param){ ptr_pair.reset(new QueuePair( param.data_param().prefech()*param.data_param().batch_size())); boost::mutex::scoped_lock lock(bodies_mutex); string hash_key = source_key(param); boost::weak_ptr<Body> weak = global_bodies[hash_key]; ptr_body = weak.lock(); if (!ptr_body){ ptr_body.reset(new Body(param)); global_bodies[hash_key] = boost::weak_ptr<Body>(ptr_body); } ptr_body->new_pairs.push(ptr_pair); }
DataReader的建構函式首先根據使用者指定的預緩衝區大小,初始化預設的雙緩衝佇列組。
接下來,要在Body的Hash容器中登記,mutex鎖住,修改之後解鎖。
登記所使用的是weak_ptr,weak_ptr可看作shared_ptr的助手,通常視為觀察者(Viewer)。
不可使用->,只能呼叫lock函式獲得shared_ptr。
DataReader的析構,主要任務是析構Body,以及從Hash容器中反登記。
DataReader::~DataReader(){ string hash_key = source_key(param); ptr_body.reset(); boost::mutex::scoped_lock lock(bodies_mutex); if (global_bodies[hash_key].expired()) global_bodies.erase(hash_key); }
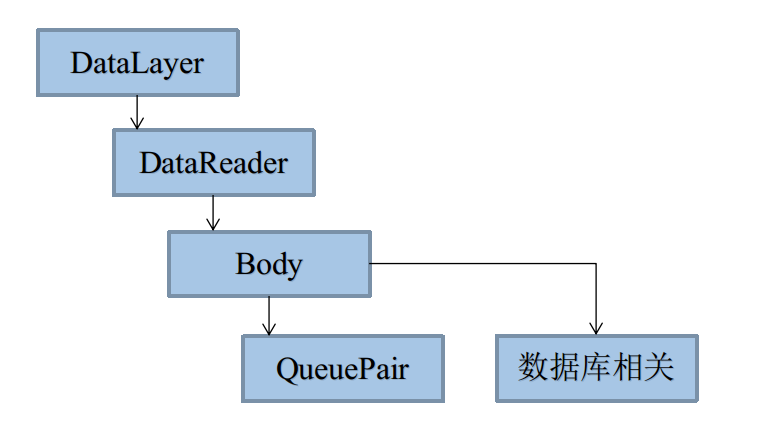
析構體系
DataReader中涉及幾個比較重要的析構,這裡以圖描述下:
完整程式碼
data_reader.hpp
data_reader.cpp
相關推薦
從零開始山寨Caffe·捌:IO系統(二)
生產者 雙緩衝組與訊號量機制 在第陸章中提到了,如何模擬,以及取代根本不存的Q.full()函式。 其本質是:除了為生產者提供一個成品緩衝佇列,還提供一個零件緩衝佇列。 當我們從外部給定了固定容量的零件之後,生產者的產能就受到了限制。 由兩個阻塞佇列組成的QueuePair,並不是Caffe的獨創,
從零開始山寨Caffe·陸:IO系統(一)
你說你學過作業系統這門課?寫個無Bug的生產者和消費者模型試試! ——你真的學好了作業系統這門課嘛? 在第壹章,展示過這樣圖: 其中,左半部分構成了新版Caffe最惱人、最龐大的IO系統。 也是歷來最不重視的一部分。 第伍章又對左半
從零開始山寨Caffe·拾:IO系統(三)
資料變形 IO(二)中,我們已經將原始資料緩衝至Datum,Datum又存入了生產者緩衝區,不過,這離消費,還早得很呢。 在消費(使用)之前,最重要的一步,就是資料變形。 ImageNet ImageNet提供的資料相當Raw,不僅影象尺寸不一,ROI焦點內容比例也不一,如圖: [Krizhev
從零開始山寨Caffe·貳:主存模型
本文轉自:https://www.cnblogs.com/neopenx/p/5190282.html 從硬體說起 物理之觴 大部分Caffe原始碼解讀都喜歡跳過這部分,我不知道他們是什麼心態,因為這恰恰是最重要的一部分。 記憶體的管理不擅,不僅會導致程式的立即崩潰,還會導致記憶體的
從零開始山寨Caffe·柒:KV資料庫
你說你會關係資料庫?你說你會Hadoop? 忘掉它們吧,我們既不需要網路支援,也不需要複雜關係模式,只要讀寫夠快就行。 ——論資料儲存的本質 淺析資料庫技術 記憶體資料庫——STL的map容器 關係資料庫橫行已久,似乎大
從零開始山寨Caffe·玖:BlobFlow
聽說Google出了TensorFlow,那麼Caffe應該叫什麼? ——BlobFlow 神經網路時代的傳播資料結構 我的程式碼 我最早手寫神經網路的時候,Flow結構是這樣的: struct Data { vector<d
從零開始山寨Caffe·伍:Protocol Buffer簡易指南
你為Class外訪問private物件而苦惱嘛?你為設計序列化格式而頭疼嘛? ——歡迎體驗Google Protocol Buffer 面向物件之封裝性 歷史遺留問題 面向物件中最矛盾的一個特性,就是“封裝性”。 在上古時期,大牛們無聊地設計了
從零開始山寨Caffe·拾貳:IO系統(四)
消費者 回憶:生產者提供產品的介面 在第捌章,IO系統(二)中,生產者DataReader提供了外部消費介面: class DataReader { public: ......... BlockingQueue<Datum*>& free() const
從零開始學caffe(七):利用GoogleNet實現影象識別
一、準備模型 在這裡,我們利用已經訓練好的Googlenet進行物體影象的識別,進入Googlenet的GitHub地址,進入models資料夾,選擇Googlenet 點選Googlenet的模型下載地址下載該模型到電腦中。 模型結構 在這裡,我們利用之前講
從零開始學caffe(十):caffe中snashop的使用
在caffe的訓練期間,我們有時候會遇到一些不可控的以外導致訓練停止(如停電、裝置故障燈),我們就不得不重新開始訓練,這對於一些大型專案而言是非常致命的。在這裡,我們介紹一些caffe中的snashop。利用snashop我們就可以實現訓練的繼續進行。 在之前我們訓練得到的檔案中,我們發現
從零開始學caffe(九):在Windows下實現影象識別
本系列文章主要介紹了在win10系統下caffe的安裝編譯,運用CPU和GPU完成簡單的小專案,文章之間具有一定延續性。 step1:準備資料集 資料集是進行深度學習的第一步,在這裡我們從以下五個連結中下載所需要的資料集: animal flower plane hou
從零開始學caffe(八):Caffe在Windows環境下GPU版本的安裝
之前我們已經安裝過caffe的CPU版本,但是在MNIST手寫數字識別中,我們發現caffe的CPU版本執行速度較慢,訓練效率不高。因此,在這裡我們安裝了caffe的GPU版本,並使用GPU版本的caffe同樣對手寫MNIST數字集進行訓練。 step1: 安裝CUDA
從零開始學caffe(四):mnist手寫數字識別網路結構模型和超引數檔案的原始碼閱讀
下面為網路結構模型 %網路結構模型 name: "LeNet" #網路的名字"LeNet" layer { #定義一個層 name: "mnist" #層的名字"mnist" type:
從零開始學caffe(二):caffe在win10下的安裝編譯
環境要求 作業系統:64位windows10 編譯環境:Visual Studio 2013 Ultimate版本 安裝流程 step1:檔案的下載 從GitHub新增連結描述中下載Windows版本的caffe,並進行解壓到電腦中。 step2:檔案修改 將壓縮包
從零開始系列-Caffe從入門到精通之一 環境搭建
python 資源暫時不可用 強制 rec htm color 查看 cpu blog 先介紹下電腦軟硬件情況吧: 處理器:Intel? Core? i5-2450M CPU @ 2.50GHz × 4 內存:4G 操作系統:Ubuntu Kylin(優麒麟) 16.04
Redis從零開始學習教程三:key值的有效期
圖片 com edi 數據 key值 一次 時間 inf 系統 Redis 是一種存儲系統,類似數據庫,和緩存的差別是,緩存有有效期,而Redis默認無有效期,或者說,默認有效期為永久 但是Redis可以當做緩存使用。這時候需要針對各個key設置有效期。 有效期單位默認為S
【視訊】Kubernetes1.12從零開始(六):從程式碼編譯到自動部署
作者: 李佶澳 轉載請保留:原文地址 釋出時間:2018/11/10 16:14:00 說明 kubefromscratch-ansible和kubefromscratch介紹 使用前準備
從零開始理解caffe網路的引數
LeNet網路介紹 LeNet網路詳解 網路名稱 name: "LeNet" # 網路(NET)名稱為LeNet mnist層-train layer {
從零開始學習Servlet(1): 作用和生命週期
Servlet 作用 Servlet 是實現了 javax.servlet.Servlet 介面的 Java 類, 負責處理客戶端的 HTTP 請求。是客戶端 與 資料庫或後臺應用程式之間互動的媒介 。功能: 1. 讀取客戶端傳送的資料 2. 處理
ubuntu 14.04 從零開始安裝caffe
一、前言 很多人不太喜歡看官方教程,但其實 caffe 的官方安裝指導做的非常好。我在看到 2) 之前,曾根據官方指導在 OSX 10.9, 10.10, Ubuntu 12.04, 14.04 下安裝過 10 多次不同版本的 caffe,都成功了。 本文有不少內容參考了 1)和 2),但又有一些內容