
從零開始山寨Caffe·拾貳:IO系統(四)
消費者
回憶:生產者提供產品的介面
在第捌章,IO系統(二)中,生產者DataReader提供了外部消費介面:
class DataReader { public: ......... BlockingQueue<Datum*>& free() const { return ptr_pair->free; } BlockingQueue<Datum*>& full() const { return ptr_pair->full; } ......... };
生產者DataReader本身繼承了執行緒DragonThread,在其非同步的執行緒工作函式中interfaceKernel()中,
不斷地從pair的Free阻塞佇列取出空Datum,在read_one()用KV資料庫內容填充,再塞到Full佇列中,如圖:
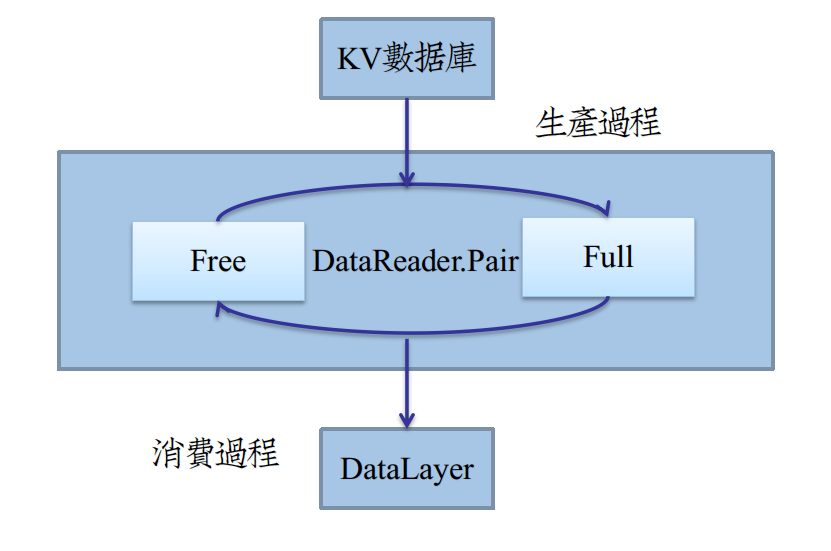
作為消費者(DataLayer),在從Datum獲得資料後,立即做一份Copy,再把Datum塞回到Free佇列中,繼續生產。
整個過程就好像是一個工廠生產的迴圈鏈,Datum就好比一個包裝盒。
生產者將產品放置其中,傳遞包裝盒給消費者。消費者從中取出產品,讓生產者回收包裝盒。
回憶: 變形者加工產品介面
在第拾章,IO系統(三)中,變形者DataTransformer提供了資料變形的基介面:
void DataTransformer<Dtype>::transform(constDatum& datum, Dtype* shadow_data)
仔細觀察一下transform的兩個引數,你會發現整個transform過程,就是將Datum資料Copy到shadow_data的數組裡。
這就是上節提到的“Copy”過程——從包裝盒中取出產品,再變形加工。
加工放置的陣列,之所以叫shadow_data,是因為它對映的是一個Blob的區域性記憶體。
回憶一下Blob的shape,[batch_size,channels,height,width],便可知,一個Datum僅僅是一個Blob的1/batch_size。
讓Transformer對對映的記憶體處理,避免了直接對Datum變形的不便。對映的記憶體空間,就是最終成品的實際空間,如圖:
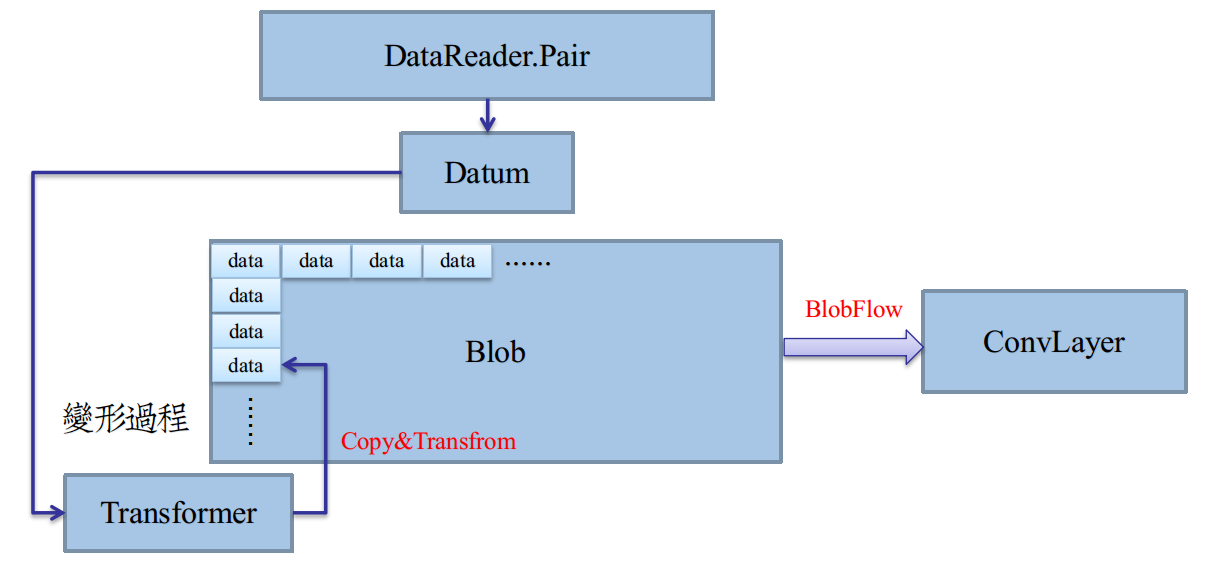
二級封裝:從Datum到Blob
在上圖中,Transformer提供了一個由Datum堆砌成Blob的途徑。
我們只需要給Transformer提供Datum元素,以及一段記憶體空間(陣列首指標)即可。
為了保證記憶體空間提供的正確性,有兩點需要保障:
①每個Datum在Blob的偏移位置必須計算出來,第玖章BlobFlow給了一點偏移的思路,
只要偏移offset=Blob.offset(i)即可,i 為一個Batch內的樣本資料下標。
②記憶體空間,也就是Blob具體的shape必須提前計算出來,而且必須啟動SyncedMemory自動機,分配實際記憶體。
考慮一個Blob的shape,[batch_size,channels,height,width],後三個shape都可以由Datum推斷出來。
至於batch_size,是一個由使用者提供的超參,可以根據網路定義直接獲取。
由Datum推理channe/height/width,由DataTransformer的inferBlobShape完成,在第拾章IO系統(三)已經給出。
二級生產者
第捌章IO系統(二)介紹了LayerParameter中的prefetch概念。
在構造一個DataReader時,指定了預設Pair的緩衝區大小:
DataReader::DataReader(const LayerParameter& param){ ptr_pair.reset(new QueuePair( param.data_param().prefech()*param.data_param().batch_size())); ........ }
total_size=prefetch*batch_size
這個大小表明了DataReader需要預緩衝prefetch個Batch,每個Batch有batch_size個Datum單元。
在 單生產者單緩衝區 一節的最後,討論了多GPU下,如何使用單Pair的補救措施:
這可能是Caffe原始碼的本意。在這種方案中,DataReader和DataLayer是無須改動程式碼的。
只要我們加大DataParameter裡的prefech數值,讓CPU多緩衝幾個Batch,為多個GPU準備就好了。
prefetch的數量由使用者指定,而且也是一個上界,而且顯然不能全部將整個KV資料庫prefetch完。
於是,以Batch為單位的二級封裝,需要一個二級生產者和消費者,而且同樣是非同步的,如IO系統(二)的圖:
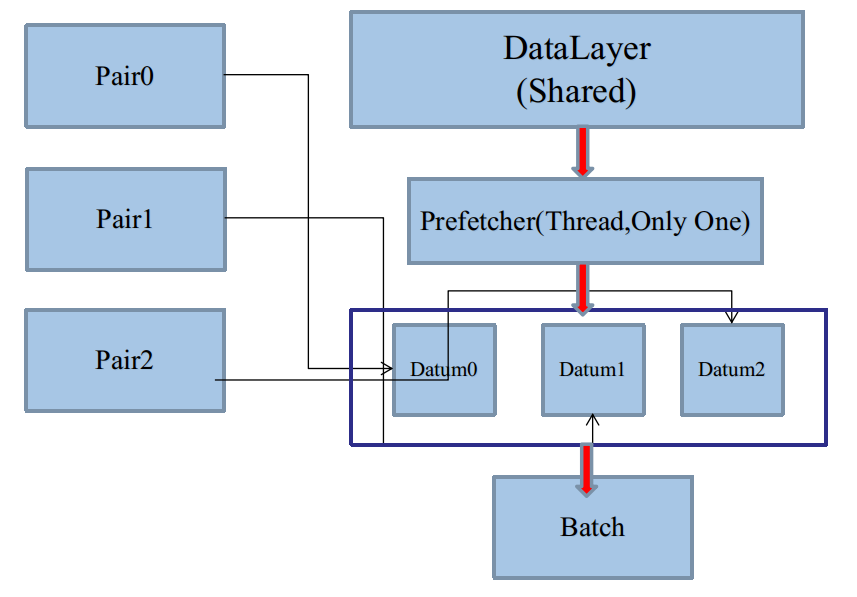
二級生產者,在Caffe裡就是DataLayer衍生的執行緒。二級消費者,恰恰就是DataLayer本身。
DataLayer集二級生產者與消費者於一體,這歸功於面向物件技術的多重繼承。
類繼承體系
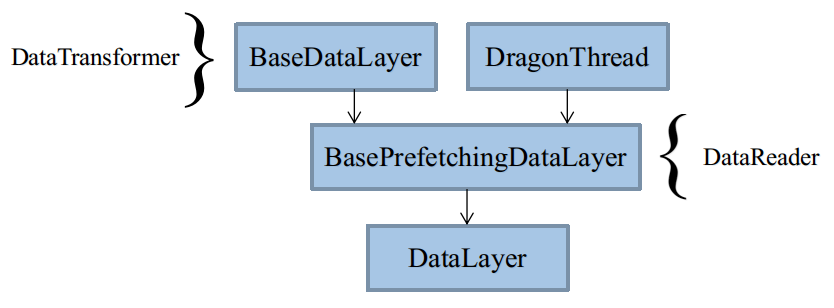
最終使用的是DataLayer,被拆解成3個類BaseDataLayer、BasePrefetchingDataLayer、DataLayer。
三個類負責不同的任務,你也可以整合在一起寫。
建構函式執行順序與二級生產者預緩衝流程
二級C++最喜歡考繼承類的執行順序,當然,這裡搞清楚這點至關重要。
除了基本的類建構函式外,我們還需要考慮Layer類setup的具體函式layerSetup。

幾個DataLayer的layerSetup相當混亂,幾乎每個都各司其職,①②③④順序不能顛倒。
完成全部setup之後,才能讓二級生產者工作。
生產單位以一個Batch為單元,每個Batch包含DataBlob和LabelBlob(可選)。
二級生產緩衝區
二級緩衝區構建於BasePrefetchingDataLayer類中。
template<typename Dtype> class BasePrefetchingDataLayer :public BaseDataLayer<Dtype>,public DragonThread { public: ....... const int PREFETCH_COUNT; protected: ....... Batch<Dtype>* prefetch; BlockingQueue<Batch<Dtype>*> free; BlockingQueue<Batch<Dtype>*> full; };
產能上界由常數PREFETCH_COUNT指定,來源於proto引數DataParamter裡prefetch大小。
在BasePrefetchingDataLayer建構函式中,用new申請等量的堆記憶體prefetch。
注意這裡不要使用shared_ptr,比較麻煩,而且Batch有可能會被智慧指標提前釋放,應當手動析構。
可以看到,預設提供了和DataReader類似的消費者介面free/full,不過這消費的是Batch,而不是Datum。
沒有用函式封裝,是因為DataLayer自己生產,自己消費。
二級生產
同DataReader的一級生產類似,二級生產需要從free佇列pop,填充,再塞入full。
生產過程於BasePrefetchingDataLayer的interfaceKernel函式中。
由於多重繼承的關係,interfaceKernel函式來自父類DragonThread
template<typename Dtype> void BasePrefetchingDataLayer<Dtype>::interfaceKernel(){ try{ while (!must_stop()){ Batch<Dtype> *batch = free.pop(); //batch has already reshape in dataLayerSetup loadBatch(batch); // pure abstract function full.push(batch); //product } } catch (boost::thread_interrupted&) {} }
loadBatch函式與DataReader的read_one函式效果類似,負責填充batch。
二級生產與非同步流同步
第貳章主存模型末尾介紹了SyncedMemory非同步提交視訊記憶體Memcpy的方法。
第玖章BlobFlow中,且已知SyncedMemory隸屬於Blob的成員變數。
當資料緩衝至Blob級別時,就需要考慮提前向視訊記憶體複製資料了。
第陸章IO系統(一)開頭給了這張圖:

可以看到,DataLayer處於CPU與GPU的分界點,DataLayer源輸入由CPU主控,存於記憶體。
而DataLayer的下一層是計算層,源輸入必須存於視訊記憶體。
於是,儘管DataLayer的前向傳播函式forward(bottom,top)只是複製資料,但是更重要的是轉換資料。
在上一節的CPU非同步執行緒工作函式interfaceKernel中,我們可以看到,Batch(Blob)級別已經構成,
而此時整個神經網路Net可能正在初始化,距離Net正式啟動前向傳播函式Net.forward(),需要視訊記憶體資料,還有一段時間。
利用這段時間,可以利用CUDA的非同步流預先由記憶體向視訊記憶體轉換資料,據此,完善interfaceKernel函式:
template<typename Dtype> void BasePrefetchingDataLayer<Dtype>::interfaceKernel(){ // create GPU async stream // speed up memcpy between CPU and GPU // because cudaMemcpy will be called frequently // rather than malloc gpu memory firstly(just call cudaMemcpy) #ifndef CPU_ONLY cudaStream_t stream; if (Dragon::get_mode() == Dragon::GPU) CUDA_CHECK(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking)); #endif try{ while (!must_stop()){ Batch<Dtype> *batch = free.pop(); //batch has already reshape in dataLayerSetup loadBatch(batch); // pure abstract function #ifndef CPU_ONLY if (Dragon::get_mode() == Dragon::GPU){ batch->data.data()->async_gpu_data(stream); // blocking this thread until host->device memcpy finished CUDA_CHECK(cudaStreamSynchronize(stream)); } #endif full.push(batch); //product } } catch (boost::thread_interrupted&) {} // destroy async stream #ifndef CPU_ONLY if (Dragon::get_mode() == Dragon::GPU) CUDA_CHECK(cudaStreamDestroy(stream)); #endif }
使用非同步流,需要用cudaStreamCreateWithFlags申請Flag為cudaStreamNonBlocking的流。
cudaStreamNonBlocking的值為0x1,代表此流非預設Memcpy流(預設流)
與之相對的是Flag為cudaStreamDefault的流,值為0x0,這是主複製流,cudaMemcpy的任務全部提交於此。
使用Blob內提交非同步流的函式async_gpu_data(stream)[稍後給出]後,需要立即阻塞(同步)該CPU執行緒。
使用cudaStreamSynchronize(stream),直到GPU返回複製完畢訊號之前,CPU一直同步在本行程式碼。
最後,需要釋放非同步流。
二級消費者
即DataLayer的forward函式。
由於大量工作已經在父類中做完,DataLayer的消費函式相對簡單。
template <typename Dtype> void DataLayer<Dtype>::forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ // consume Batch<Dtype> *batch = full.pop("DataLayer prefectching queue is now empty"); dragon_copy<Dtype>(batch->data.count(), top[0]->mutable_cpu_data(), batch->data.cpu_data()); if (has_labels) dragon_copy(batch->label.count(), top[1]->mutable_cpu_data(), batch->label.cpu_data()); free.push(batch); }
直接訪問full佇列獲取一個可用的Batch,完成消費。
將batch資料(data/label)分別複製到top裡,完成Blob的Flow,提供給下一層計算。
template <typename Dtype> void DataLayer<Dtype>::forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ Batch<Dtype> *batch = full.pop("DataLayer prefectching queue is now empty"); dragon_gpu_copy(batch->data.count(), top[0]->mutable_gpu_data(), batch->data.gpu_data()); if (has_labels) dragon_gpu_copy(batch->label.count(), top[1]->mutable_gpu_data(), batch->label.gpu_data()); free.push(batch); }
GPU版本,直接替換copy函式為GPU版本即可。
(注:Caffe在forward_gpu()最後,對預設流的強制同步是沒有必要的。
Memcpy也本身不是非同步執行,不需要額外同步。對預設流同步,也不會影響非同步流)
相關推薦
從零開始山寨Caffe·拾貳:IO系統(四)
消費者 回憶:生產者提供產品的介面 在第捌章,IO系統(二)中,生產者DataReader提供了外部消費介面: class DataReader { public: ......... BlockingQueue<Datum*>& free() const
從零開始山寨Caffe·拾:IO系統(三)
資料變形 IO(二)中,我們已經將原始資料緩衝至Datum,Datum又存入了生產者緩衝區,不過,這離消費,還早得很呢。 在消費(使用)之前,最重要的一步,就是資料變形。 ImageNet ImageNet提供的資料相當Raw,不僅影象尺寸不一,ROI焦點內容比例也不一,如圖: [Krizhev
從零開始山寨Caffe·貳:主存模型
本文轉自:https://www.cnblogs.com/neopenx/p/5190282.html 從硬體說起 物理之觴 大部分Caffe原始碼解讀都喜歡跳過這部分,我不知道他們是什麼心態,因為這恰恰是最重要的一部分。 記憶體的管理不擅,不僅會導致程式的立即崩潰,還會導致記憶體的
從零開始山寨Caffe·柒:KV資料庫
你說你會關係資料庫?你說你會Hadoop? 忘掉它們吧,我們既不需要網路支援,也不需要複雜關係模式,只要讀寫夠快就行。 ——論資料儲存的本質 淺析資料庫技術 記憶體資料庫——STL的map容器 關係資料庫橫行已久,似乎大
從零開始山寨Caffe·玖:BlobFlow
聽說Google出了TensorFlow,那麼Caffe應該叫什麼? ——BlobFlow 神經網路時代的傳播資料結構 我的程式碼 我最早手寫神經網路的時候,Flow結構是這樣的: struct Data { vector<d
從零開始山寨Caffe·陸:IO系統(一)
你說你學過作業系統這門課?寫個無Bug的生產者和消費者模型試試! ——你真的學好了作業系統這門課嘛? 在第壹章,展示過這樣圖: 其中,左半部分構成了新版Caffe最惱人、最龐大的IO系統。 也是歷來最不重視的一部分。 第伍章又對左半
從零開始山寨Caffe·捌:IO系統(二)
生產者 雙緩衝組與訊號量機制 在第陸章中提到了,如何模擬,以及取代根本不存的Q.full()函式。 其本質是:除了為生產者提供一個成品緩衝佇列,還提供一個零件緩衝佇列。 當我們從外部給定了固定容量的零件之後,生產者的產能就受到了限制。 由兩個阻塞佇列組成的QueuePair,並不是Caffe的獨創,
從零開始山寨Caffe·伍:Protocol Buffer簡易指南
你為Class外訪問private物件而苦惱嘛?你為設計序列化格式而頭疼嘛? ——歡迎體驗Google Protocol Buffer 面向物件之封裝性 歷史遺留問題 面向物件中最矛盾的一個特性,就是“封裝性”。 在上古時期,大牛們無聊地設計了
從零開始學caffe(七):利用GoogleNet實現影象識別
一、準備模型 在這裡,我們利用已經訓練好的Googlenet進行物體影象的識別,進入Googlenet的GitHub地址,進入models資料夾,選擇Googlenet 點選Googlenet的模型下載地址下載該模型到電腦中。 模型結構 在這裡,我們利用之前講
從零開始學caffe(十):caffe中snashop的使用
在caffe的訓練期間,我們有時候會遇到一些不可控的以外導致訓練停止(如停電、裝置故障燈),我們就不得不重新開始訓練,這對於一些大型專案而言是非常致命的。在這裡,我們介紹一些caffe中的snashop。利用snashop我們就可以實現訓練的繼續進行。 在之前我們訓練得到的檔案中,我們發現
從零開始學caffe(九):在Windows下實現影象識別
本系列文章主要介紹了在win10系統下caffe的安裝編譯,運用CPU和GPU完成簡單的小專案,文章之間具有一定延續性。 step1:準備資料集 資料集是進行深度學習的第一步,在這裡我們從以下五個連結中下載所需要的資料集: animal flower plane hou
從零開始學caffe(八):Caffe在Windows環境下GPU版本的安裝
之前我們已經安裝過caffe的CPU版本,但是在MNIST手寫數字識別中,我們發現caffe的CPU版本執行速度較慢,訓練效率不高。因此,在這裡我們安裝了caffe的GPU版本,並使用GPU版本的caffe同樣對手寫MNIST數字集進行訓練。 step1: 安裝CUDA
從零開始學caffe(四):mnist手寫數字識別網路結構模型和超引數檔案的原始碼閱讀
下面為網路結構模型 %網路結構模型 name: "LeNet" #網路的名字"LeNet" layer { #定義一個層 name: "mnist" #層的名字"mnist" type:
從零開始學caffe(二):caffe在win10下的安裝編譯
環境要求 作業系統:64位windows10 編譯環境:Visual Studio 2013 Ultimate版本 安裝流程 step1:檔案的下載 從GitHub新增連結描述中下載Windows版本的caffe,並進行解壓到電腦中。 step2:檔案修改 將壓縮包
從零開始學習iOS開發1:認識xcode
連接 啟動圖標 主動 認識 tor 音樂 滴滴打車 啟動 and 在開始之前還是不得不提一下iPhone應用開發的工具,我當然之前是沒接觸過iPhone開發,也沒使用過apple的不論什麽一種設備。所以我的概念中僅僅知道xcode是最專業的iOS開發工具。如今它是免費
從零開始系列-Caffe從入門到精通之一 環境搭建
python 資源暫時不可用 強制 rec htm color 查看 cpu blog 先介紹下電腦軟硬件情況吧: 處理器:Intel? Core? i5-2450M CPU @ 2.50GHz × 4 內存:4G 操作系統:Ubuntu Kylin(優麒麟) 16.04
從零開始的無人駕駛 02:Vehicle Detection
在 CNN (Convolutional Neural Networks 卷積神經網路) 普遍運用之前,車輛檢測是通過使用條件隨機場或者SVM(支援向量機)來實現的。操作上分為兩步,先是從影象上提取特徵,然後基於特徵建立模型,判斷車輛位置。 template matching 模板匹配 對於影象上的每一塊
從零開始學產品第一篇:概述
如何從零基礎成長為一個獨立完成專案的產品經理呢? 我們認為一個系統化、規範化、可執行的循序漸進的學習框架 比一開始就談痛點、談風口、談突破的理論性文章 要更加適合培養零基礎的人成長為一名初級產品經理 經過修真院三年多時間的
從零開始學深度學習二:神經網路
本課程筆記來源於深享網課程《深度學習理論與實戰TensorFlow》 2.1學習的種類 學習的種類主要分成以下三類:監督學習、非監督學習和強化學習三種。接下來,將分別對這三種學習進行介紹。 監督學習: 對已經標記的訓練樣本進行學習,然後對樣本外的資料進行標記
從零開始學深度學習三:logistic迴歸模型
本筆記來源於深享網課程《深度學習理論與實戰TensorFlow》 Logistic迴歸模型是一種廣義的迴歸模型,其與多元線性迴歸有很多相似之處,模型的基本形式相同,雖然也被稱為迴歸模型,但是需要注意的是,Logistic更多應用在分類問題中,但是又以二分類最