
face recognition[Euclidean-distance-based loss][FaceNet]
本文來自《FaceNet: A Unified Embedding for Face Recognition and Clustering》。時間線為2015年6月。是谷歌的作品。
0 引言
雖然最近人臉識別領域取得了重大進展,但大規模有效地進行人臉驗證和識別還是有著不小的挑戰。Florian Schroff等人因此提出了FaceNet模型,該模型可以直接將人臉圖片對映到歐式空間中。在該空間中,歐式embedding可以用平方的L2距離直接表示人臉的相似度:
- 相同ID的人臉距離較小;
- 不同ID的人臉距離較大。
也就是一旦如果是能直接對映到歐式空間中,那麼如人臉識別,驗證和人臉聚類都可以基於現有的標準方法直接用FaceNet生成的特徵向量進行計算。
之前的人臉識別方法是在一個已知人臉ID資料集下,基於一個分類層訓練深度網路,然後將中間的bottleneck層作為表徵去做人臉識別的泛化(即基於訓練集訓練一個特徵提取模型,然後將該模型,如sift一樣在未知人臉甚至未知ID的人臉上提取特徵)。此類方法缺點是間接性和低效性:
- 做預測的時候,期望bottleneck表徵能夠很好的對新人臉進行泛化;
- 通過使用該bottleneck層,每個人臉得到的特徵向量維度是很大的(比如1k維)。雖然有工作基於PCA做特徵約間,但是PCA是一個線性模型。
FaceNet使用訓練後的深度卷積網路直接對嵌入向量進行優化,而不是如之前的DL方法一樣去優化所謂的bottleneck層。FaceNet基於《Distance metric learning for large margin nearest neighbor classification》採用triplet loss進行訓練,並輸出只有128維的embedding向量。這裡的triplet包含人臉三元組(即三張人臉圖片\(a,b,c\)
當然選擇哪種triplet也是很重要的,受到《Curriculum learning》的啟發,作者提出一個線上負樣本挖掘策略,以此保證持續性增加網路訓練過程中的困難程度(分類越是錯誤的,包含的修正資訊越多)。為了提升聚類準確度,同時提出了硬正樣本挖掘策略,以提升單人的embedding特徵球形聚類效果(一個聚類簇就是一個人的多張人臉圖片)。

正如圖1所示,其中的陰影遮擋等對於之前的人臉驗證系統簡直是噩夢。
1 FaceNet
相似於其他採用深度網路的方法,FaceNet也是一個完全資料驅動的方法,直接從人臉畫素級別的原始影象開始訓練,得到整個人臉的表徵。不使用工程化後的特徵,作者暴力的通過一大堆標記人臉資料集去解決姿態,光照和其他不變性(資料為王)。本文中採用了2個深度卷積網路:
- 基於《Visualizing and understanding convolutional networks》的深度網路(包含多個交錯的卷積層,非線性啟用,區域性響應歸一化(local response normalizations)和最大池化層),增加了幾個額外的1x1xd卷積層;
- 基於Inception模型。
作者實驗發現這些模型可以減少20倍以上的引數,並且因為減少了FLOPS的數量,所以計算量也下降了。
FaceNet採用了一個深度卷積網路,這部分有2種選擇(上述兩種),整體結構如下圖
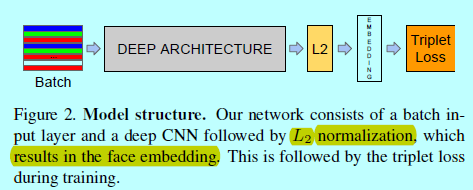
通過將深度卷積網路視為一個黑盒子,來進行介紹會更方便一些。整個FaceNet結構是end-to-end的,在結構的最後採用的itriplet loss,直接反映了人臉驗證,識別和聚類所獲取的本質。即獲取一個embedding \(f(x)\),將一個影象 \(x\)對映到特徵空間 \(R_d\)中,這樣來自同一個ID的不同影象樣本之間距離較小,反之較大。
這裡採用Triplet loss是來自《Deep learning face representation by joint identification-verification》的靈感,相比而言,triplet loss更適合作為人臉驗證,雖然前面《·》的loss更偏向一個ID的所有人臉都對映到embedding空間中一個點。不過triplet loss會增大不同ID之間的人臉邊際,同時讓一個ID的人臉都落在一個流行上。
1.1 triplet loss
embedding表示為\(f(x)\in R^d\)。通過將一個圖片\(x\)嵌入到d維歐式空間中。另外,限制這個embedding,使其處在d維超球面上,即\(||f(x)||_2=1\)。這裡要確保一個特定人的圖片\(x_i^a\)(錨)和該人的其他圖片\(x_i^p\)(正樣本)相接近且距離大於錨與其他人的圖片\(x_i^n\)(負樣本)。如下圖所示
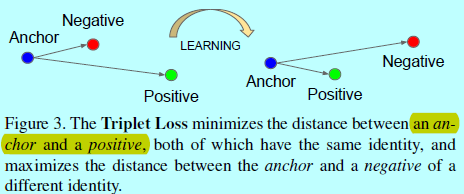
因此,符合如下形式:
\[||f(x_i^a)-f(x_i^p)||_2^2+\alpha < ||f(x_i^a)-f(x_i^n)||_2^2,\, \, \forall (f(x_i^a),f(x_i^p),f(x_i^n))\in T \]
這裡 \(\alpha\)是邊際用於隔開正對和負對。 \(T\)是訓練集中所有可能的triplets,且其有 \(N\)個候選三元組
這裡loss可以寫成如下形式:
\[\sum_i^N\left [ ||f(x_i^a)-f(x_i^p)||_2^2-||f(x_i^a)-f(x_i^n)||_2^2+\alpha\right ]_+\]
基於所有可能的triplets組合,可以生成許多的triplet。這些triplet中有許多對網路訓練沒有什麼幫助,會減慢網路的收斂所需時間,所以需要挑出那些資訊量大的triplet組合。
1.2 triplet 選擇
為了保證快速收斂,需要找到那些反模式的triplet,即給定\(x_i^a\),需要選擇的\(x_i^p\)(硬正樣本)能夠滿足\(\underset{x_i^p}{\arg max}||f(x_i^a)-f(x_i^p)||_2^2\),相似的,\(x_i^n\)(硬負樣本)能夠滿足\(\underset{x_i^n}{\arg min}||f(x_i^a)-f(x_i^n)||_2^2\)。顯然沒法基於整個訓練集計算\(\arg min\)和\(\arg max\)。而且,如一些誤標記和質量不高的人臉影象也滿足此類需求,而這些樣本會導致訓練引入更多噪音。這可以通過兩個明顯的選擇避免此類問題:
- 每隔\(n\)步離線的生成triplets,使用最近的網路checkpoint,用其基於訓練集的子集計算\(\arg min\),\(\arg max\);
- 線上生成triplet,這通過一個mini-batch內部選擇硬正/負樣本對來實現。
本文主要關注線上生成方式。通過使用一個包含上千個樣本的大mini-batch去計算所需要的\(\arg min\),\(\arg max\)。而為了確保能計算到triplet,那麼就需要訓練使用的mini-batch中一定要包含(錨,正類,負類)樣本。FaceNet的實驗中,對訓練資料集進行取樣,如每個mini-batch中每個ID選擇大概40個圖片。另外在對每個mini-batch隨機取樣需要的負樣本。
不直接挑選最硬的正樣本,在mini-batch中會使用所有的(錨,正)樣本對,同時也會進行負樣本的選擇。FaceNet中,並沒有將所有的硬(錨,正)樣本對進行比較,不過發現在實驗中所有的(錨,正)樣本對在訓練的開始會收斂的更穩定,更快。作者同時也採用了離線生成triplet的方法和線上方法相結合,這可以讓batch size變得更小,不過實驗沒做完。
在實際操作中,選擇最硬的負樣本會導致訓練之初有較壞的區域性最小,特別會導致形成一個摺疊模型(collapsed model),即\(f(x)=0\)。為了減緩這個問題,即可以選擇的負樣本滿足:
\[||f(x_i^a)-f(x_i^p)||_2^2<||f(x_i^a)-f(x_i^n)||_2^2\]
這些負樣本稱為”半硬(semi-hard)“,即雖然他們比正樣本要遠離錨,不過平方的距離是很接近(錨,正)樣本對的距離的,這些樣本處在邊際\(\alpha\)內部。
如上所述,正確的triplets樣本對的選擇對於快速收斂至關重要。一方面,作者使用小的mini-batch以提升SGD的收斂速度;另一方面,仔細的實現步驟讓batch是包含10或者百的樣本對卻更有效。所以主要的限制引數就是batch size。本實驗中,batch size是包含1800個樣本。
1.3 深度卷積網路
本實驗中,採用SGD方式和AdaGrad方式訓練CNN,在實驗中,學習率開始設定為0.05,然後慢慢變小。模型如《Going deeper with convolutions》一樣隨機初始化,在一個CPU叢集上訓練了1k到2k個小時。在訓練開始500h之後,loss的下降開始變緩,不過接著訓練也明顯提升了準確度,邊際\(\alpha\)為0.2。如最開始介紹的,這裡有2個深度模型的選擇,他們主要是引數和FLOPS的不同。需要按照不同的應用去決定不同的深度網路。如資料中心跑的模型可以有許多模型,和較多的FLOPS,而執行在手機端的模型,就需要更少的引數,且要能放得下記憶體。所有的啟用函式都是ReLU。
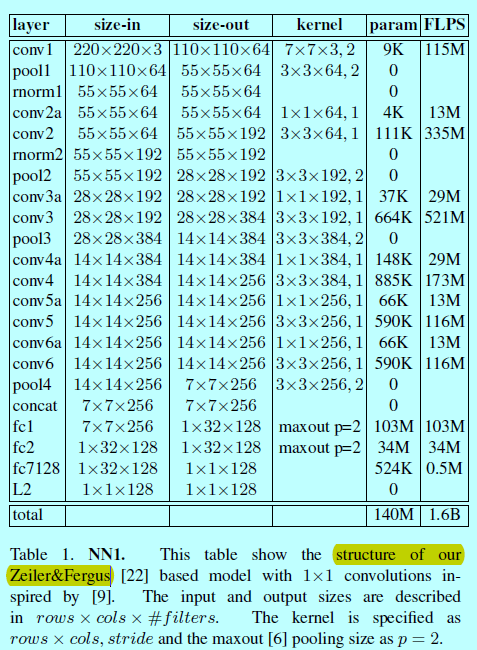
如表1中採用的是第一種方法,在標準的卷積層之間增加1x1xd的卷積層,得到一個22層的模型,其一共140百萬個引數,每個圖片需要1.6十億個FlOPS的計算。
第二個策略就是GoogleNet,其相比少了20多倍的引數(大概6.6百萬-7.5百萬),且少了5倍的FLOPS(基於500M-1.6B)。所以這裡的模型可以執行在手機端。如:
- NNS1只有26M引數量,需要220M FLOPS的計算;
- NNS2有4.3M引數量,且只需要20M FLOPS計算量。
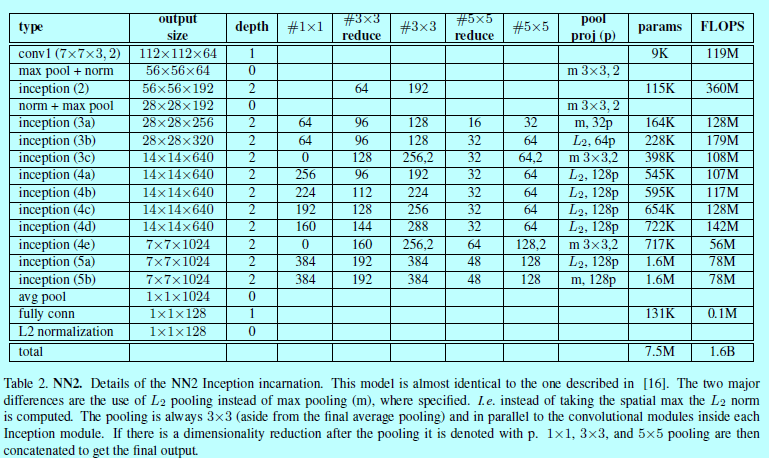
表2描述了NN2網路結構,NN3架構是一樣的,只是輸入層變成了160x160。NN4輸入層只有96x96,因此需要更少的CPU計算量(285M的FLOPS,而NN2有1.6B)。另外,為了減少輸入尺度,在高層網路層,也不使用5x5的卷積。而且實驗發現移除了5x5的卷積,對最後結果沒什麼影響。如圖4
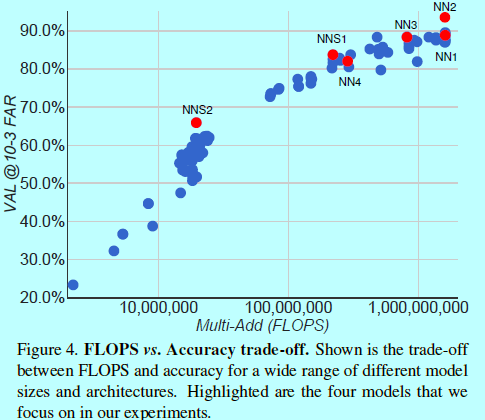
2 實驗及分析
......