
論文筆記 Visual Question Answering with Memory-Augmented Networks(CVPR2018)
阿新 • • 發佈:2018-12-11
這是沈春華老師小組的一篇文章。
這篇文章的出發點是:目前的VQA問題,由於answer數量的有限性,因此轉化為一種分類問題,但由於部分answer出現
的頻次較低(比如上圖中的黃瓜),為了提高整體的分類準確率,往往進行分類的時候,將頻次低的answer進行捨棄,
如取answer出現頻次高的top1000,。基於這種現象,本文提出Memory-Augmented Network來處理這樣一種長尾效應。

方法簡介
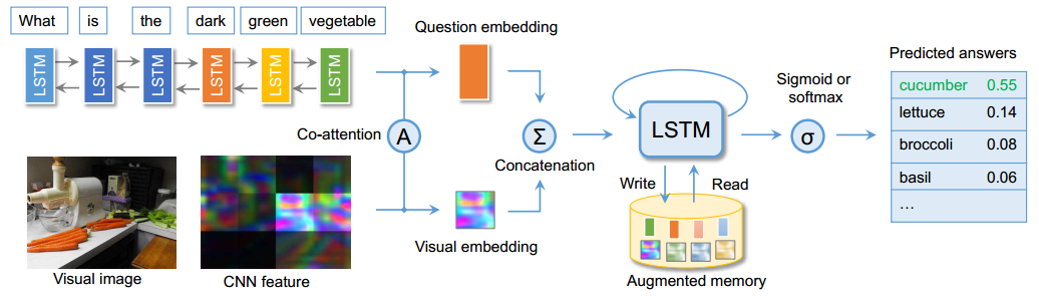
(1)對於影象與question的分別特徵提取,並沒有太多的新意,對於兩種特徵也採用了sequential co-attention機制,但
這種attention機制也是借鑑的NIPS2016中一篇VQA的方法。
(2)文章主打的Memory-Augmented network是在原來的memory network上進行改進,主要有兩點別:其利用LSTM自
身特性,形成一種天然的internal memory其也設計了一種external memory,使得LSTM成為一種外部記憶機制的控制器
文章由於處理的問題是出現頻次少的answer帶來的長尾效應,因此主要落點放在了memory寫機制的創新上,文中的寫機
制能夠在memory中極少用到的位置與經常用到的位置中達到一種平衡,來緩解長尾效應。具體實現細節,不再贅述,但
是這種memory的讀寫,既借鑑了作業系統記憶體的讀寫,又可與推理引擎中的working memory聯絡,又很好地利用深度
學習的記憶機制來實現,很有參考借鑑意義。
參考原文:Visual Question Answering with Memory-Augmented Networks