
論文筆記 Memory Fusion Network for Multi-view Sequential Learning (AAAI2018)
這是卡內基梅隆大學與新加坡南洋理工大學在AAAI上發表的一篇利用memory network來處理序列建模的文章。
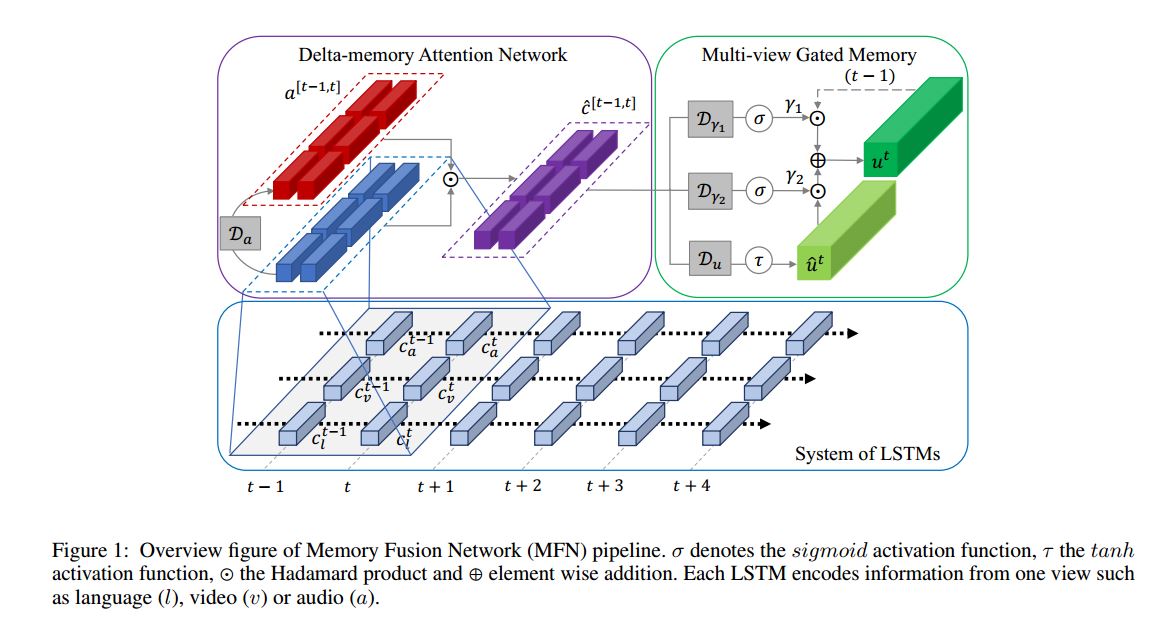
文章中的multi view其實指代可以很廣泛,許多地方也叫做multi modal,對於多模態序列學習而言,模態往往存在兩種形式的互動(1)模態內關聯(view-specific interactions),(2)模態間關聯(cross-view interactions),這篇文章提出了Memory Fusion Network(MFN)方法來處理這種多模態序列建模,處於對模態內與模態間的不同處理,本文可將方法劃分為三個部分(1)LSTM對各自模態單獨建模(2)Delta-memory Attention Network(DMAN)(3)Multi-view Gated Memory,後兩者致力於處理模態間的互動。
Input:
比如對語言,視訊,音訊序列進行建模, ,the input data of the th view is denoted as: ,where is the input dimensionality of th view input .
System of LSTMs:
使用常規的LSTM, 對於每個輸入 ,每一個step的memory表示為 ,每個step的output表示為 ,where denotes the dimensionality of th LSTM memory .
Delta-memory Attention Network
Delta顧名思義,考慮了LSTM前後兩個step,輸入到DMAN的是 與 的memory拼接,其中 , 通過上式來獲得attention係數, 是對於時刻 與 的softmax score。
DMAN的輸出定義如下
是分配權重之後的memories, 是element product.
Multi-view Gated Memory
(1)首先以上面的
為輸入,生成update proposal
。
相關推薦
論文筆記 Memory Fusion Network for Multi-view Sequential Learning (AAAI2018)
這是卡內基梅隆大學與新加坡南洋理工大學在AAAI上發表的一篇利用memory network來處理序列建模的文章。 文章中的multi view其實指代可以很廣泛,許多地方也叫做multi modal,對於多模態序列學習而言,模態往往存在兩種形式的互動(1)模態內關聯(view-sp
論文筆記-Deep Interest Network for Click-Through Rate Prediction
圖片 res 興趣 log through deep pre 出發 amp 重點:認為不同的廣告會觸發用戶的興趣點不同導致user embedding隨之改變。 DIN網絡結構如下圖右邊 DIN的出發點:認為不同的廣告會觸發用戶的興趣點不同導致user embedd
論文筆記-Deep Affinity Network for Multiple Object Tracking
空間 text nco 符號 實現 項目 第一個 box using 作者: ShijieSun, Naveed Akhtar, HuanShengSong, Ajmal Mian, Mubarak Shah 來源: arXiv:1810.11780v1 項目:https
論文筆記(CPN):Cascaded Pyramid Network for Multi-Person Pose Estimation
該論文發表在2018年CVPR上,用於多人姿態估計的級聯金字塔網路 arxiv論文地址:https://arxiv.org/abs/1711.07319 github程式碼:https://github.com/GengDavid/pytorch-cpn,https://g
論文筆記-Temporal segment network:towards good practices for deep action recognition
1-摘要 卷積神經網路在圖片的視覺識別方面已經取得了巨大的成功,然而關於視訊的動作識別,成果還不是那麼明顯。這篇文章意在發現一種能夠針對視訊的行為識別設計有效的卷積神經網路結構並能夠在有限
『 論文閱讀』A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
AbstractMULTI-VIEW-DNN聯合了多個域做的豐富特徵,使用multi-view DNN模型構建推薦,包括app、新聞、電影和TV,相比於最好的演算法,老使用者提升49%,新使用者提升110%。並且可以輕鬆的涵蓋大量使用者,解決冷啟動問題。主要做user embedding的過程,通多使用者在多
《Cascaded Pyramid Network for Multi-Person Pose Estimation》--曠世2017COCO keypoints冠軍論文解讀
簡介 《Cascaded Pyramid Network for Multi-Person Pose Estimation》,這是Face++曠世科技2017年取得COCO Keypoints Challenge冠軍的文章,主要目的是解決 in the wil
論文筆記 Stacked Hourglass Networks for Human Pose Estimation
Stacked Hourglass Networks for Human Pose Estimation key words:人體姿態估計 Human Pose Estimation 給定單張RGB影象,輸出人體某些關鍵點的精確畫素位置.堆疊式沙漏網路 Stacked Hourglass Net
論文筆記(2)--(Re-ID) Learning Discriminative Features with Multiple Granularities for Person Re-Id
https://github.com/lwplw/re-id_mgn 本文的主要思想就是通過區域分割,來獲得不同粒度的特徵,比如全域性和區域性特徵以及更細粒度的區域性特徵,通過一個網路的不同分支得到這些特徵,每個分支都對不同的分割塊進行特徵提取。 論文提出通過融合行人的全域性資
論文筆記:Spectral Normalization for Generative Adversarial Networks [ICLR2018 oral]
Spectral Normalization for Generative Adversarial Networks 原文連結:傳送門 一篇純數學類文章,有興趣的時候再看! Emma CUH
【論文筆記】Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification
摘要 Person re-identification (ReID) is an important task in computer vision. Recently, deep learning with a metric learning loss has becom
『演算法學習』CPN:Cascaded Pyramid Network for Multi-Person Pose Estimation
原文L:https://www.cnblogs.com/hellcat/p/10138036.html 論文連線 CVPR2018的文章,用於關鍵點檢測(原話叫“多人姿態估計”)。本算髮聚焦點在於處理多人姿態估計所面臨的挑戰:關鍵點遮擋,關鍵點不可見,複雜背景等——就是優化對於難以檢測的點的
論文筆記:Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks
Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks ========簡陋的記錄=========== 背景知識:Distant Sup
論文筆記《Selective Search for object recognition》
影象包含的資訊非常的豐富,其中的物體(Object)有不同的形狀(shape)、尺寸(scale)、顏色(color)、紋理 (texture),要想從影象中識別出一個物體非常的難,還要找到物體在影象中的位置,這樣就更難了。圖中給出四個例子,來說明物體識別 (Object Recognition)的複雜性以
ECCV2016論文 Peak-piloted deep network for facial expression Recognition 解析
1、主要貢獻 提出了一種基於peak-piloted的表情識別新方案(PPDN:peak-piloted deep network),通過建立non-peak影象和peak影象的對映關係,提高了non-peak 影象表情識別的準確率,解決了中間表情(non-p
論文筆記:Perceptual Losses for Real-Time Style Transfer and Super-Resolution[doing]
1.transformation: image to image 2.perceptual losses: psnr是per-pixel的loss,值高未必代表圖片質量好,廣泛應用只是因為
【論文閱讀】Feedback Network for Image Super-Resolution
開發十年,就只剩下這套架構體系了! >>>
論文筆記5:How to Discount Deep Reinforcement Learning:Towards New Dynamic Strategies
參考資料:How to Discount Deep Reinforcement Learning: ... 為幫助跟我一樣的小白,如果有大神看到錯誤,還請您指出,謝謝~ 知乎同名:uuummmmiiii 創新點:相比於原始DQN不固定折扣因子(discount factor,γ),學習率(
論文筆記 Co-Attending Free-Form Regions and Detections (AAAI2018)
Co-Attending Free-Form Regions and Detections with Multi-Modal Multiplicative Feature Embedding for Visual Question Answering 現在做VQA的,很多方法都是基
2017-06-Deep Network Flow for Multi-Object Tracking-論文閱讀筆記
摘要: 資料關聯是很多計算機視覺應用的重要組成部分,多目標跟蹤就是其中的一個例子。典型的資料跟蹤方法是找到一個圖匹配方式或者一個網路流使得配對連線的代價最小,然而經常使用的是手工設計特徵或者固定特徵的線性函式。本文指出通過將優化問題表示為可微的函式反向傳播學習資料關聯的特徵是必要。本文用上述