
resnet,Resnet,殘差網路
Resnet
這篇部落格主要介紹了提出Resnet的兩篇論文,我分析了兩篇論文的核心內容,歡迎大家閱讀!
相關論文
2016CVPR Deep Residual Learning for Image Recognition
2016ECCV Identity Mapping in Deep Residual Networks
論文簡介
CVPR論文
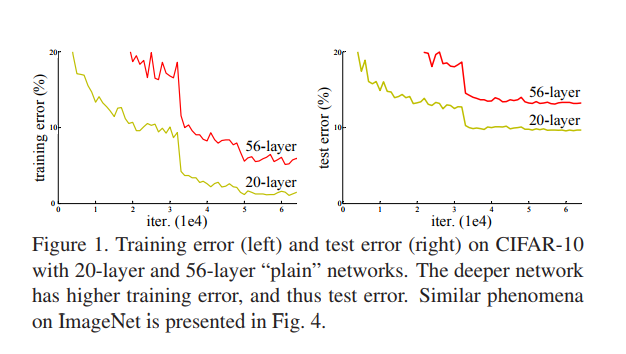
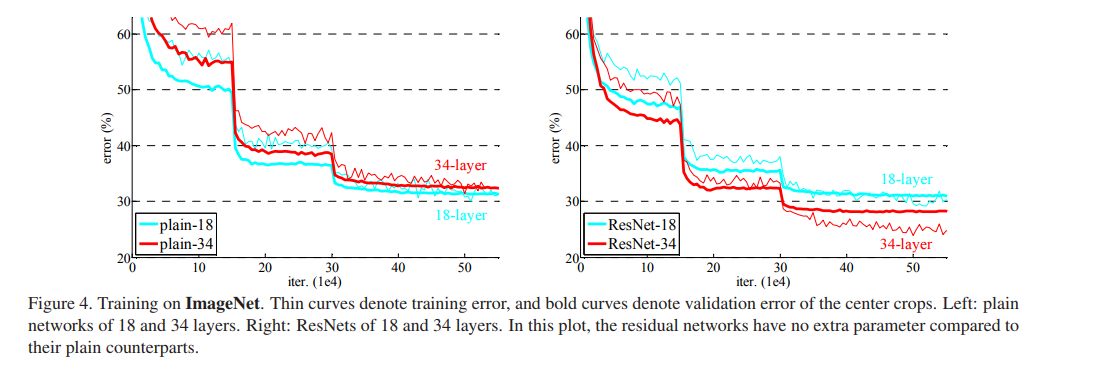
1.極深的深度網路會導致train error 和test error都增加, 這並不是由於overfitting導致的,因為訓練集的error也增加。說明不是所有的系統都可以被同樣簡單地優化。作者全文以一種簡單的堆疊(plain)神經網路來於深度殘差網路作對比,下圖所示即為剛剛所說的簡單堆疊引起的誤差增加。
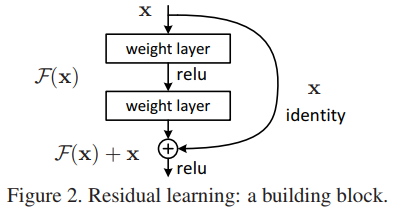
2. 在CVPR這篇論文中最重要的一幅圖就是下圖,一個更深的殘差網路可以由下面的殘差單元所組成。在以前的深度學習中我們通常擬合的是 中的 函式,其中 是網路的輸入, 是網路的輸出,一大串的網路可以抽象為一個非線性 函式(因為使用了非線性啟用函式…)。我們現在將原先的函式重新記為 ,我們這篇論文網路學習的函式為 ,它是原來網路輸出和網路輸入的差,即為殘差。當我們將一大串網路的學習目標改為殘差後,那麼網路的輸出即為 。為了實現和原有輸入的相加,我們需要將正常的前向網路新增一個”shortcut connections”。這個”shortcut connections”在這篇論文中就是一個”Identity mapping”(恆等對映),顯而易見,恆等對映在原有網路基礎上,並不需要參加額外的引數,它仍然可以使用現有神經網路框架的SGD(隨機梯度下降)等求解器求解訓練。
3. 作者接下來簡單介紹了深度殘差網路和簡單堆疊神經網路在ImageNet和CIFAR-10兩個資料集對比結果,發現深度殘差網路不僅非常容易優化,而且隨著深度的增加殘差網路的分類準確率也增加。同時殘差網路在其他資料集和其他影象分割檢測等任務中表現也十分優秀。擁有極好的擴充套件性。
4. 作者下一部分Related Work中對殘差表示和shortcut connections的相關工作進行了介紹。
5. 作者之後介紹了使用殘差這種形式的靈感來源,degradation這個問題暗示了原來的優化網路損失的演算法在經過傳統很多層非線性網路層後無法近似模擬恆等對映,而通過殘差單元中的shortcut connections將x直接送過去,會解決這個問題。
6. 作者下面用這個公式來說明恆等變換的細節。 , 在相加時我們需要保證經過若干神經網路層後即 處理後與 維度相同,所以公式變為 , 僅僅用於匹配維度。作者推薦在殘差單元中新增兩層或者三層卷積神經網路, 當然更多層也可以嘗試,但是一層作者沒有觀察到殘差單元的優勢。
7. 作者之後用三種網路結構處理Imagenet, 並進行對比,三種網路結構如下圖所示。
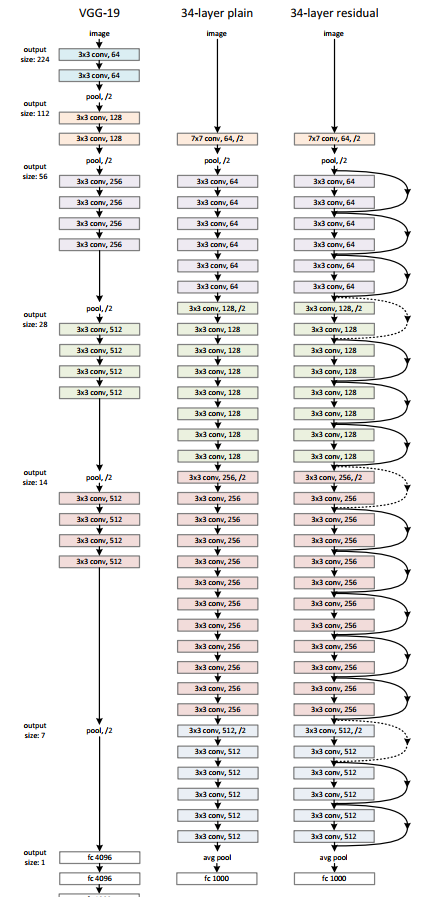
8. 注意到在殘差網路虛線處feature map的維度增加了,作者提出了兩種選擇:
- shortcut仍然是恆等對映,但是額外的0元素進行填充來實現維度增加,這種方法不會增加額外的引數。
- 第二種方法是使用剛剛的有 這個引數的公式來進行一個1*1的卷積操作實現。
9.接下來作者介紹了自己在處理ImageNet資料集使用的一些trick:- 首先將圖片resize到[256, 480],之後從中隨機裁剪224*224大小,並進行水平翻轉,然後進行影象標準化。作者在每次卷積操作後啟用前使用BN(Batch Normalization批標準化)操作。使用隨機梯度下降的batch_size為256, 學習率初始設定為0.1之後不斷的除以10。模型總共訓練了 輪, 同時權重衰減為0.0001,動量為0.9,沒有使用dropout。
10.下面是具體不同層數的Resnet網路的結構
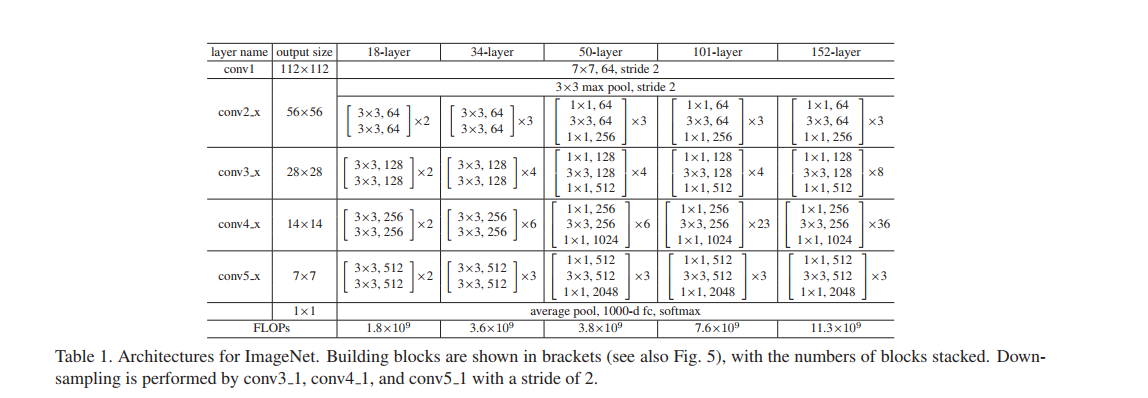
11.下面作者通過圖表來比較簡單堆疊的神經網路和Resnet的訓練誤差,進一步看出Resnet層數增加訓練誤差減小。
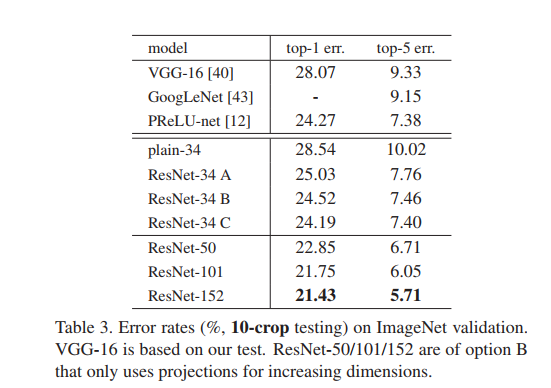
12.之後作者對比了一系列以往模型在ImageNet資料集下的錯誤率,分為單一模型和整合模型進行比較,可以看出只是單一模型的Resnet就超過了以往所有模型整合的效果,體現出了殘差網路的強大。

13.作者之後探討了3種不同的shortcut方法:- A.當需要增加維度時,使用0來增加維度,其他時候直接傳入x,這樣便不用增加額外的引數
- B.在增加時使用投影即上面所說的 來增加維度,其他時候直接傳入x
- C.在所有shortcut使用投影。
經過對比可以看出其區別並不是很大,而且它對前面提到的最重要的Degradation問題沒有重要的影響,所以接下來都採取最簡單的A或者B來減小模型的複雜度、記憶體消耗等。
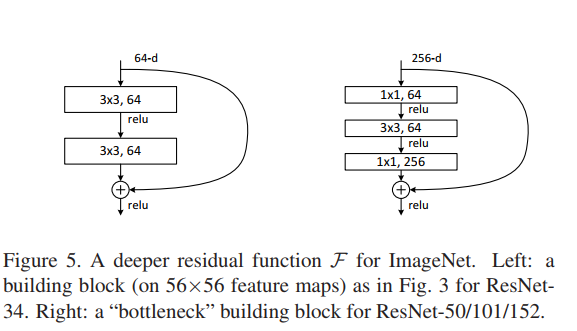
14.之後作者對之前的殘差單元(building block)進行了修改,原來的是兩個3x3的卷積層,修改後是兩個1x1一個3x3的卷積層,這個設計稱為bottleneck。1x1的層用來減小然後增加維度,使得3x3的卷積層有著更小的輸入和輸出維度。這種實現減少了模型的大小。同時作者強調了這樣的設計最好使用零填充,不然模型的大小會翻倍。
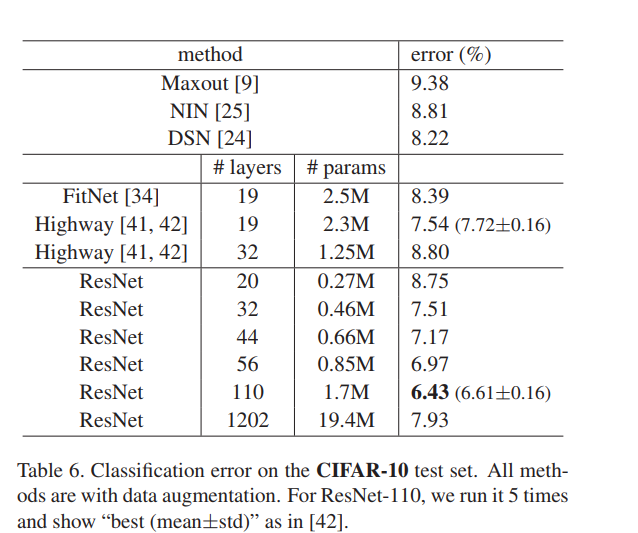
15.然後作者又在CIFAR-10資料集下對比了不同模型的實驗結果,同時介紹了一些網路細節。這裡有一個十分需要注意的地方就是在1202層的設計中Resnet的錯誤率並沒有下降,因此作者在ECCV發表了第二篇來解決這個問題。
16.最後作者說他們並沒有使用maxout、dropout等trick,這些值得研究。同時介紹了殘差網路在其他任務的優良表現。
ECCV論文
1.深度殘差網路由很多的堆疊的殘差單元(Residual Units)組成,每個殘差單元都可以用下面的公式表示:
其中
分別為第l個單元的輸入和輸出,
是殘差函式,在之前的論文中
,
是一個ReLU函式。這篇論文主要結論是當
時,訊號可以直接從一個單元傳入另外一個單元,無論是在前向傳播過程中還是後向傳播過程中。
2.作者首先為了瞭解skip connections, 對比了不同型別的
,發現當
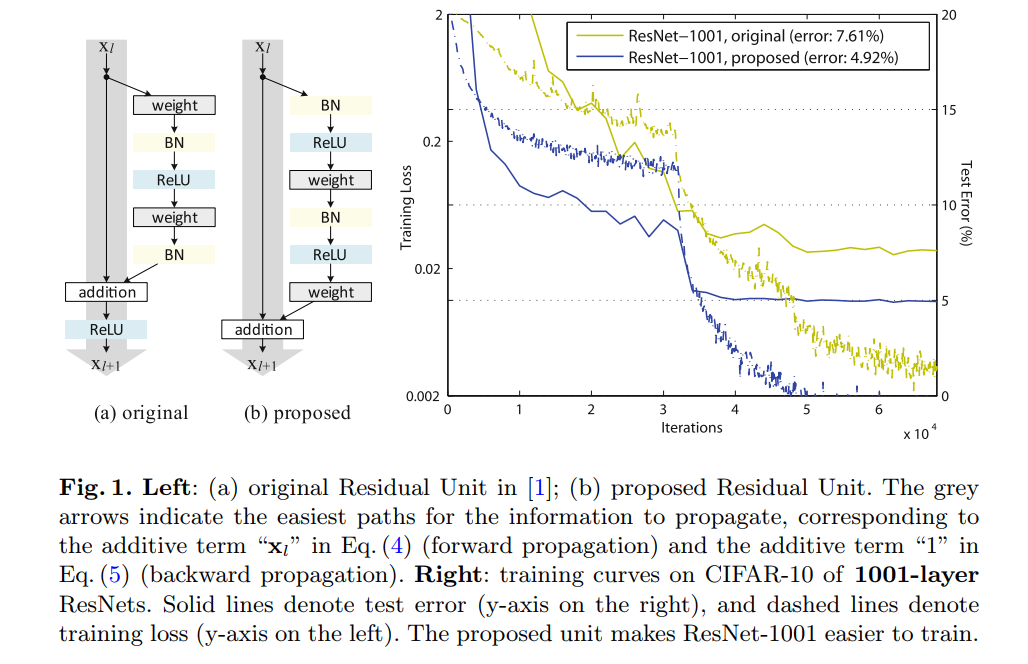
時,擁有最快的錯誤下降率同時有著最小的訓練誤差。其他方法如scaling、gating以及1x1convolutions都會導致高的錯誤率和高的訓練誤差。下面是作者提供的便於對比的圖:作者告訴我們傳播原始輸入的這一條路越“乾淨”越好。同時注意到右側proposed作者將BN、ReLU兩個操作提前到卷積操作前(稱為預啟用),預啟用相比original的post-activation效果更好,這個解決了上篇論文中在網路更深到1000多層出現的訓練誤差增大的問題。
3.作者接下來用公式分析了殘差網路,在上面的公式中如果
,那麼
當我們對每一個殘差單元進行遞迴計算後可以得到: