
scrapy爬蟲實戰:偽裝headers構造假IP騙過ip138.com
阿新 • • 發佈:2018-12-11
scrapy爬蟲實戰:偽裝headers構造假IP騙過ip138.com
我們在爬蟲的過程中,經常遇到IP被封的情況,那麼有沒有偽裝IP的方案呢,對於一些簡單的網站我們只要偽造一下headers就可以了。
我們一般來說想知道自己的IP,只需要訪問一下 http://www.ip138.com/ 就可以知道自己的IP了
使用瀏覽器檢查工具,具體檢視一下
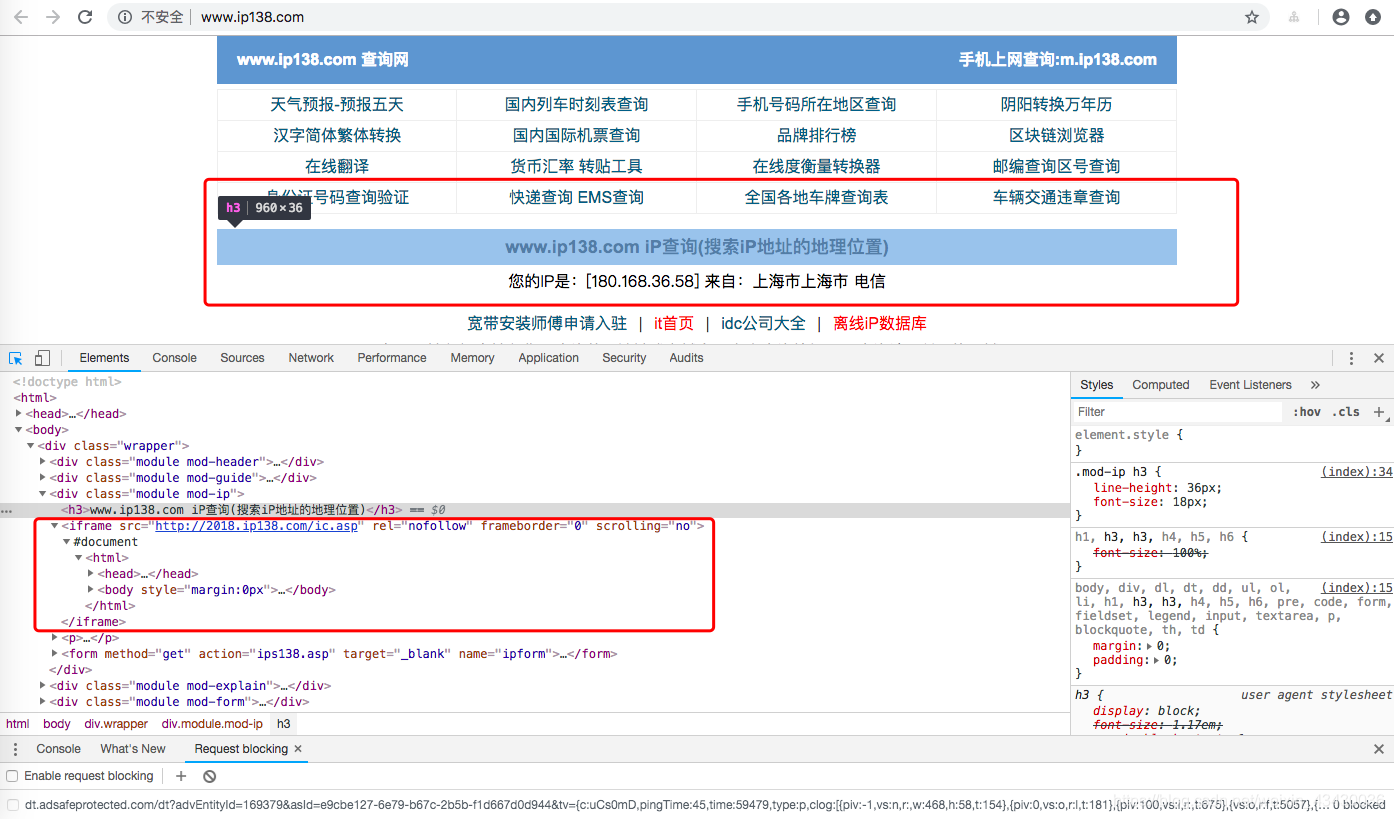
就可以發現,實際上,IP資訊來源於 http://2018.ip138.com/ic.asp
即

最終來說就是,我們只需要訪問 http://2018.ip138.com/ic.asp 就可以知道自己的IP了。那麼我們今天的目標就是偽造一下headers騙過 ip138.com
Middleware 中介軟體偽造Header
Util.py
編寫一個可以動態偽造ip和agent的工具類
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
import random
from tutorial.settings import USER_AGENT_LIST
class Util(object middlewares.py
middlewares.py 設定動態headers
from scrapy import signals
from backend.libs.Util import Util
from scrapy.http.headers import Headers
class TutorialDownloaderMiddleware(object):
def process_request(self, request, spider):
request.headers = Headers(Util.get_header('2018.ip138.com'))
settings.py
settings.py 配置動態Agent 啟用middlewares
USER_AGENT_LIST=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.TutorialDownloaderMiddleware': 1,
}
ip138.py
# -*- coding: utf-8 -*-
import scrapy
class Ip138Spider(scrapy.Spider):
name = 'ip138'
allowed_domains = ['www.ip138.com','2018.ip138.com']
start_urls = ['http://2018.ip138.com/ic.asp']
def parse(self, response):
print("*" * 40)
print("response text: %s" % response.text)
print("response headers: %s" % response.headers)
print("response meta: %s" % response.meta)
print("request headers: %s" % response.request.headers)
print("request cookies: %s" % response.request.cookies)
print("request meta: %s" % response.request.meta)
執行檢視效果
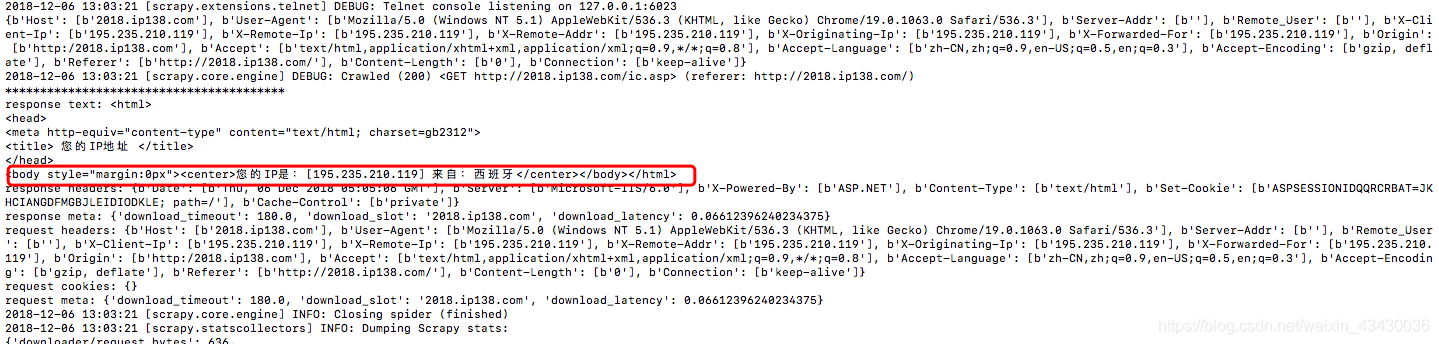
偽造成功。