
Scrapy爬蟲實戰------360攝影美圖
阿新 • • 發佈:2018-11-30
網站:
切換到攝影介面。
開啟開發者工具:

我們在下拉的時候可以看到這是一個ajax請求,資料結構是json。
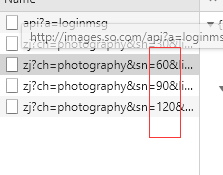
sn=30返回的是前30張圖片,sn=60返回的是30到60的圖片。
建立專案:

構造請求:
url為:http://images.so.com/zj?ch=photography&listtype=new&sn=30&listtype=new
def start_requests(self):
data = {'ch': 'photography', 'listtype': 'new'}
base_url = 'http://images.so.com/zj?'
for page in range(1,self.settings.get('MAX_PAGE')+1):
data['sn'] = page*30
data['temp'] = 1
params = urlencode(data)
url = base_url+params
yield Request(url, self.parse)提取資訊:
首先要定義一個Item:
from scrapy import Item,Field
class Images360Item(Item):
#MongoDb儲存的collection名稱和mysql的表名稱
collection = table = 'images'
id = Field()
url = Field()
title = Field()
thumb = Field()
提取Spider的資訊:
from ..items import Images360Item import json
def parse(self, response):
# print(response)
result = json.loads(response.text)
for image in result.get('list'):
item = Images360Item()
item['id'] = image.get('imageid')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('group_title')
item['thumb'] = image.get('qhimg_thumb_url')
yield item儲存資訊
pipelines.py檔案中
Mongo儲存
class MongoPipeline(object):
#初始化資料庫
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri =mongo_uri
self.mongo_db =mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
"""初始化資料庫"""
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
"""存入資料"""
self.db[item.collection].insert(dict(item))
return item
def close(self,item,spider):
"""關閉資料庫"""
self.client.close()Mysql儲存:
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8',
port=self.port)
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
然後下載圖片,程式碼如下:
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
# 獲取下載路徑
url = request.url
print('******************')
print(url)
# 命名
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
# results對應下載結果,是一個列表形式
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
#將url欄位拿出來,執行下載。
yield Request(item['url'])
然後在settings.py檔案中新增下載路徑:
IMAGES_STORE = './images'
啟用管道檔案:
ITEM_PIPELINES = {
'images360.pipelines.ImagePipeline': 300,
'images360.pipelines.MongoPipeline': 301,
'images360.pipelines.MysqlPipeline': 302,
}
資料庫配置的設定:
MONGO_URI = 'localhost' MONGO_DB = 'images360' MYSQL_HOST = 'localhost' MYSQL_DATABASE = 'images360' MYSQL_PORT = 3306 MYSQL_USER = 'root' MYSQL_PASSWORD = '123456'
最後儲存的結果如下:
Mongo:

Mysql:

注意:最後幾項的配置一定不能出錯,不然或是產生儲存不了的結果,或是圖片無法下載的結果。