
深度學習:人臉識別Facenet_cvpr2015
一、主要思想:
embedding對映關係:將特徵從原來的特徵空間對映到一個新的特徵空間上,新的特徵就稱原來的特徵嵌入,卷積末端全連線層輸出為的特徵對映到一個超球面上,使其特徵二範數歸一化。
通過 CNN人臉影象特徵對映到歐式空間的特徵向量上,計算不同圖片人臉特徵的距離,通過相同個體的人臉的距離,總是小於不同個體的人臉這一先驗知識訓練網路。測試時只需要計算人臉特徵,然後計算距離使用閾值即可判定兩張人臉照片是否屬於相同的個體。識別:如每個人抽取512或者256維度,將維度上的值進行歐式距離計算,小於一個閾值則判定是同一個人,否者不是同一人。
二、網路結構:
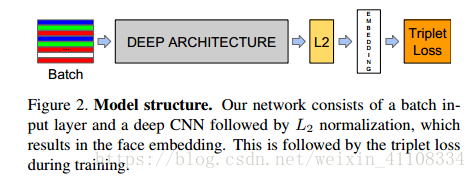
網路結構:傳統的卷積神經網路,然後在求L2範數之前進行歸一化,就建立了這個嵌入空間(512/256/128維),最後損失函式。
三、triplet loss
1、三元組概念
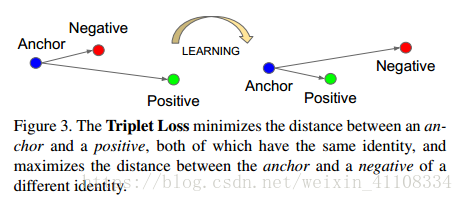
triplet loss 損失函式,用於訓練差異性較小的樣本
在有監督的機器學習領域,通常有固定的類別,這時就可以使用基於softmax的交叉熵損失函式進行訓練。但有時,類別是一個變數,此時使用triplet loss就能解決問題。在人臉識別,Quora question pair任務中,triplet loss的優勢在於細節區分,即當兩個輸入相似時,triplet loss能夠更好地對細節進行建模,相當於加入了兩個輸入差異性差異的度量,學習到輸入的更好表示,從而在上述兩個任務中有出色的表現。當然,triplet loss的缺點在於其收斂速度慢,有時不收斂。
Triplet loss的motivation是要讓屬於同一個人的人臉儘可能地“近”(在embedding空間裡),而與其他人臉儘可能地“遠”。
anchor 為錨點 negative positive,經過learning使得離positive正 距離變小,negative負 距離變大,用於訓練差異性較小的樣本,
2、三元組定義
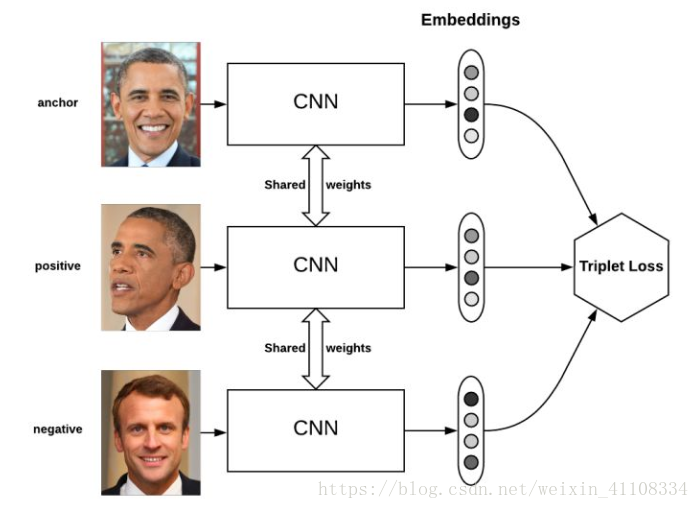
triplet loss的目標是:
兩個具有同樣標籤的樣本,他們在新的編碼空間裡距離很近。
兩個具有不同標籤的樣本,他們在新的編碼空間裡距離很遠。
進一步,我們希望兩個positive examples和一個negative example中,negative example與positive example的距離,大於positive examples之間的距離,或者大於某一個閾值:margin。
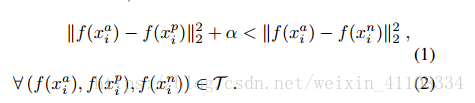
3、LOSS function

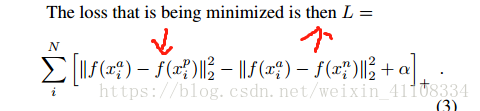
4、三元組分類 :
為了保證訓練的收斂速度,選擇距離最遠的相同人像hard-positive,和最近的不同人像訓練hard negative,在mini-batch中進行選擇.

- easy triplets(簡單三元組): triplet對應的損失為0的三元組,形式化定義為d(a,n)>d(a,p)+margin。
- hard triplets(困難三元組): negative example 與anchor距離小於anchor與positive example的距離,形式化定義為 d(a,n)<d(a,p)。
- semi-hard triplets(一般三元組): negative example 與anchor距離大於anchor與positive example的距離,但還不至於使得loss為0,即d(a,p)<d(a,n)<d(a,p)+margin。
上述三種概念都是基於negative example與anchor和positive距離定義的。類似的,可以根據上述定義將negative examples分為3類:hard negatives, easy negatives, semi-hard negatives。如下圖所示,這個圖構建了編碼空間中三種negative examples與anchor和positive example之間的距離關係。

如何選擇triplet或者negative examples,對模型的效率有很大影響。在上述Facenet論文中,採用了隨機的semi-hard negative構建triplet進行訓練,取得了不錯的效果。
5、offline /online triplet mining
通過上面的分析,可以看到,easy negative example比較容易識別,沒必要構建太多由easy negative example組成的triplet,否則會嚴重降低訓練效率。若都採用hard negative example,又可能會影響訓練效果。這時,就需要一定的方法進行triplet的挑選,也就是“mine the triplets”。
5.1 Offline triplet mining
離線方式的triplet mining將所有的訓練資料餵給神經網路,得到每一個訓練樣本的編碼,根據編碼計算得到negative example與anchor和positive example之間的距離,根據這個距離判斷semi-hard triplets,hard triplets還是easy triplets。offline triplet mining 僅僅選擇select hard or semi-hard triplets,因為easy triplet太容易了,沒有必要訓練。
總得來說,這個方法不夠高效,因為最初要把所有的訓練資料餵給神經網路,而且每過1個或幾個epoch,可能還要重新對negative examples進行分類。
5.2 Online triplet mining
Google的研究人員為解決上述問題,提出了online triplet mining的方法。該方法的motivation比較簡單,將B張圖片(一個batch)餵給神經網路,得到B張圖片的embedding,將triplet的組合一共最多$B^3$個triplets,其中包含很多沒用的triplet(比如,三個negative examples和三個positive examples,這種稱作invalid triplets)。哪些是valid triplets呢?假設一個triplet$(B_i,B_j,B_k)$,如果樣本i和j有相同的label且不是同一個樣本,而樣本k具有不同的label,則稱其為valid triplet。
假設一個batch的資料包含P*K張人臉,P個人,每人K張圖片。
- batch all: 計算所有的valid triplet,對6hard 和 semi-hard triplets上的loss進行平均。
- 不考慮easy triplets,因為easy triplets的損失為0,平均會把整體損失縮小
- 將會產生PK(K-1)(PK-K)個triplet,即PK個anchor,對於每個anchor有k-1個可能的positive example,PK-K個可能的negative examples
- batch hard: 對於每一個anchor,選擇hardest positive example(距離anchor最大的positive example)和hardest negative(距離anchor最小的negative example),
- 由此產生PK個triplet
- 這些triplet是最難分的