應用於語義分割問題的深度學習技術綜述
|
摘要 計算機視覺與機器學習研究者對影象語義分割問題越來越感興趣。越來越多的應用場景需要精確且高效的分割技術,如自動駕駛、室內導航、甚至虛擬現實與增強現實等。這個需求與視覺相關的各個領域及應用場景下的深度學習技術的發展相符合,包括語義分割及場景理解等。這篇論文回顧了各種應用場景下利用深度學習技術解決語義分割問題的情況:首先,我們引入了領域相關的術語及必要的背景知識;然後,我們介紹了主要的資料集以及對應的挑戰,幫助研究者選取真正適合他們問題需要及目標的資料集;接下來,我們介紹了現有的方法,突出了各自的貢獻以及對本領域的積極影響;最後,我們展示了大量的針對所述方法及資料集的實驗結果,同時對其進行了分析;我們還指出了一系列的未來工作的發展方向,並給出了我們對於目前最優的應用深度學習技術解決語義分割問題的研究結論。 |
||||||
|
1 導言 如今,語義分割(應用於靜態2D影象、視訊甚至3D資料、體資料)是計算機視覺的關鍵問題之一。在巨集觀意義上來說,語義分割是為場景理解鋪平了道路的一種高層任務。作為計算機視覺的核心問題,場景理解的重要性越來越突出,因為現實中越來越多的應用場景需要從影像中推理出相關的知識或語義(即由具體到抽象的過程)。這些應用包括自動駕駛[1,2,3],人機互動[4],計算攝影學[5],影象搜尋引擎[6],增強現實等。應用各種傳統的計算機視覺和機器學習技術,這些問題已經得到了解決。雖然這些方法很流行,但深度學習革命讓相關領域發生了翻天覆地的變化,因此,包括語義分割在內的許多計算機視覺問題都開始使用深度架構來解決,通常是卷積神經網路CNN[7-11],而CNN在準確率甚至效率上都遠遠超過了傳統方法。然而,相比於固有的計算機視覺及機器學習分支,深度學習還遠不成熟。也因此,還沒有一個統一的工作及對於目前最優方法的綜述。該領域的飛速發展使得對初學者的啟蒙教育比較困難,而且,由於大量的工作相繼被提出,要跟上發展的步伐也非常耗時。於是,追隨語義分割相關工作、合理地解釋它們的論點、過濾掉低水平的工作以及驗證相關實驗結果等是非常困難的。 就我所知,本文是第一篇致力於綜述用於語義分割的深度模型技術的文章。已經有較多的關於語義分割的綜述調查,比如[12,13]等,這些工作在總結、分類現有方法、討論資料集及評價指標以及為未來研究者提供設計思路等方面做了很好的工作。但是,這些文章缺少對某些最新資料集的介紹,他們不去分析框架的情況,而且沒有提供深度學習技術的細節。因此,我們認為本文是全新的工作,而且這對於深度學習相關的語義分割社群有著重要意義。
|
||||||
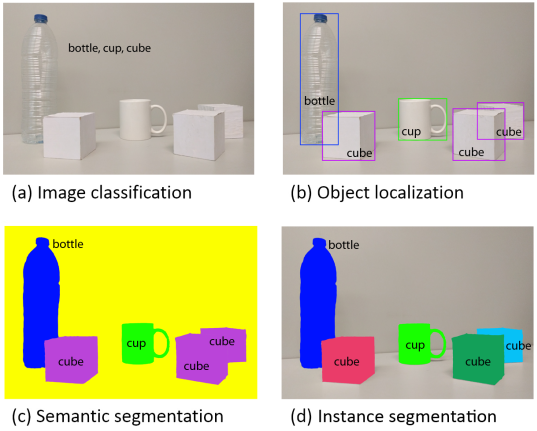
圖1: 物體識別或場景理解相關技術從粗粒度推理到細粒度推理的演變:四幅圖片分別代表分類、識別與定位、語義分割、例項分割。
本文核心貢獻如下: 1)我們對於現有的資料集給出了一個全面的調查,這些資料集將會對深度學習技術推動的分割專案發揮作用; 2)我們對於多數重要的深度學習語義分割方法進行了深度有條理的綜述,包括他們的起源、貢獻等; 3)我們進行了徹底的效能評估,使用了多種評價指標如準確率、執行時間、記憶體佔用等; 4)我們對以上結果進行了討論,並給出了未來工作的一系列可能的發展方向,這些方向可能在未來的發展程序中取得優勢。我們還給出了該領域目前最好方法的總結。
本文剩餘部分安排: 第二章介紹了語義分割問題,同時引入了相關工作中常用的符號、慣例等。其他的背景概念如通用的深度神經網路也在這章中回顧; 第三章介紹了現有的資料集、挑戰及實驗基準; 第四章回顧了現有方法,基於其貢獻自下而上排序。本章重點關注這些方法的理論及閃光點,而不是給出一個定量的評估; 第五章給出了一個簡短的對於現有方法在給定資料集上定量表現的討論,另外還有未來相關工作的發展方向; 第六章則總結全文並對相關工作及該領域目前最優方法進行了總結。
圖2: 文獻[14]中給出的AlexNet卷積神經網路架構。
2.1.2 VGG
VGG是由牛津大學Visual Geometry Group提出的卷積神經網路模型(以課題組的名字命名)。他們提出了深度卷積神經網路的多種模型及配置[15],其中一種提交到了2013年ILSVRC(ImageNet大規模影象識別)競賽上。這個模型由於由16個權重層組成,因此也被稱為VGG-16,其在該競賽中取得了top-5上92.7%的準確率。圖3展示了VGG-16的模型配置。VGG-16與之前的模型的主要的不同之處在於,其在第一層使用了一堆小感受野的卷積層,而不是少數的大感受野的卷積層。這使得模型的引數更少,非線性性更強,也因此使得決策函式更具區分度,模型更好訓練。

圖 3 VGG-16卷積神經網路模型架構,本圖經許可取自Matthieu Cord的演講。
2.1.3 GoogLeNet
GoogLeNet是由Szegedy等人[16]提出的在ILSVRC-2014競賽上取得top-5上93.3%準確率的模型。這個CNN模型以其複雜程度著稱,事實上,其具有22個層以及新引入的inception模組(如圖4所示)。這種新的方法證實了CNN層可以有更多的堆疊方式,而不僅僅是標準的序列方式。實際上,這些模組由一個網路內部的網路層(NiN)、一個池化操作、一個大卷積核的卷積層及一個小核的卷積層組成。所有操作均平行計算出來,而後進行1×1卷積操作來進行降維。由於這些模組的作用,引數及操作的數量大大減少,網路在儲存空間佔用及耗時等方面均取得了進步。
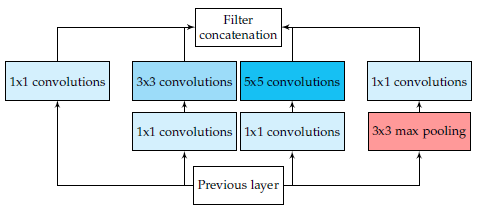
圖 4 GoogLeNet框架中帶有降維的Inception模組。
2.1.4 ResNet
微軟提出的ResNet[17]由於在ILSVRC-2016中取得的96.4%的準確率而廣受關注。除了準確率較高之外,ResNet網路還以其高達152層的深度以及對殘差模組的引入而聞名。殘差模組解決了訓練真正深層網路時存在的問題,通過引入identity skip connections網路各層可以把其輸入複製到後面的層上。本方法的關鍵想法便是,保證下一層可以從輸入中學到與已經學到的資訊不同的新東西(因為下一層同時得到了前一層的輸出以及原始的輸入)。另外,這種連線也協助解決了梯度消失的問題。
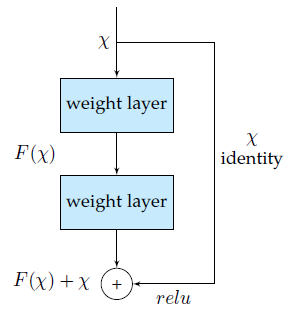
圖 5 ResNet中的殘差模組。
2.1.5 ReNet
為了將迴圈神經網路RNN模型擴充套件到多維度的任務上,Graves等人[18]提出了一種多維度迴圈神經網路(MDRNN)模型,將每個單一的迴圈連線替換為帶有d個連線的標準RNN,其中d是資料的spatio-temporal維度。基於這篇工作,Visin等人[19]提出了ReNet模型,其不使用多維RNN模型,而是使用常見的序列RNN模型。這樣,RNN模型的數量在每一層關於d(輸入影象的維數2d)線性增長。在ReNet中,每個卷積層(卷積+池化)被4個同時在水平方向與豎直方向切分影象的RNN模型所替代,如圖6所示:
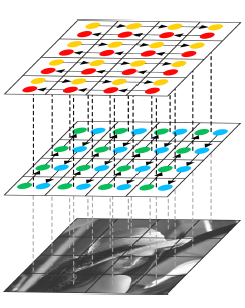
圖 6 ReNet架構中的一層,對豎直與水平方向的空間依賴性建模。 表 1 常見的大規模分割資料集 圖 7 [65]中的全卷積神經網路示意圖。將全連線層替換為卷積層,便可將用於分類的CNN網路轉化為生成空間熱區的網路。加入反捲積層來實現上取樣,使得網路可以進行密集推理並學到每個畫素點的標籤。
最近,最成功用於語義分割的深度學習技術均來自同一個工作,即全卷積網路FCN [65],該方法的出色之處在於,其利用了現存的CNN網路作為其模組之一來產生層次化的特徵。作者將現存的知名的分類模型包括AlexNet、VGG-16、GoogLeNet和ResNet等轉化為全卷積模型:將其全連線層均替換為卷積層,輸出空間對映而不是分類分數。這些對映由小步幅卷積上取樣(又稱反捲積)得到,來產生密集的畫素級別的標籤。該工作被視為里程碑式的進步,因為它闡釋了CNN如何可以在語義分割問題上被端對端的訓練,而且高效的學習瞭如何基於任意大小的輸入來為語義分割問題產生畫素級別的標籤預測。本方法在標準資料集如PASCAL VOC分割準確率上相對於傳統方法取得了極大的進步,且同樣高效。由於上述及更多顯著的貢獻,FCN成為了深度學習技術應用於語義分割問題的基石,其處理過程如圖7所示。
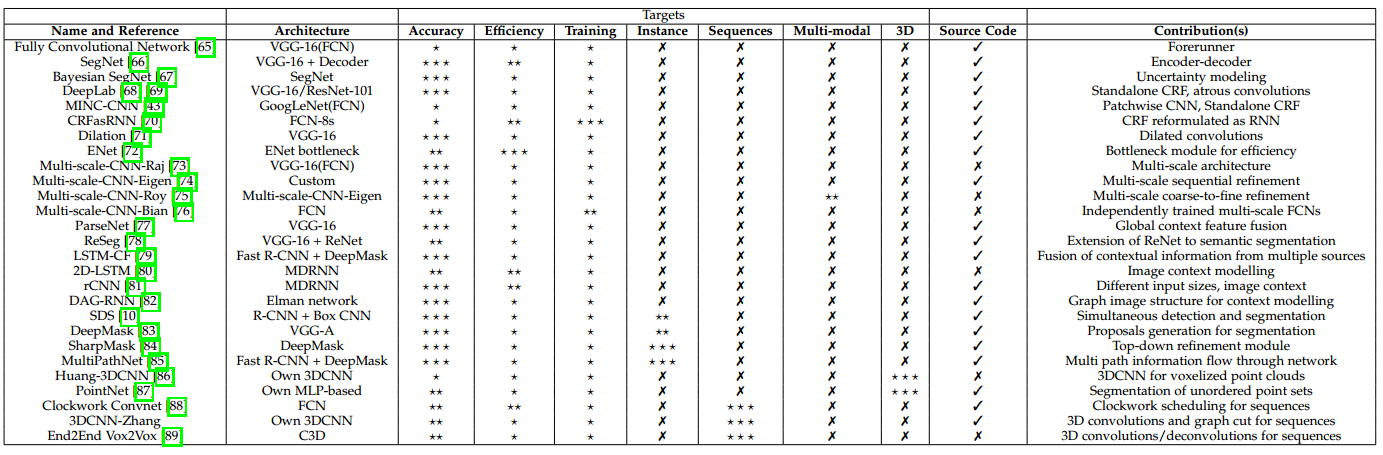
表 2 基於深度學習的語義分割方法總結
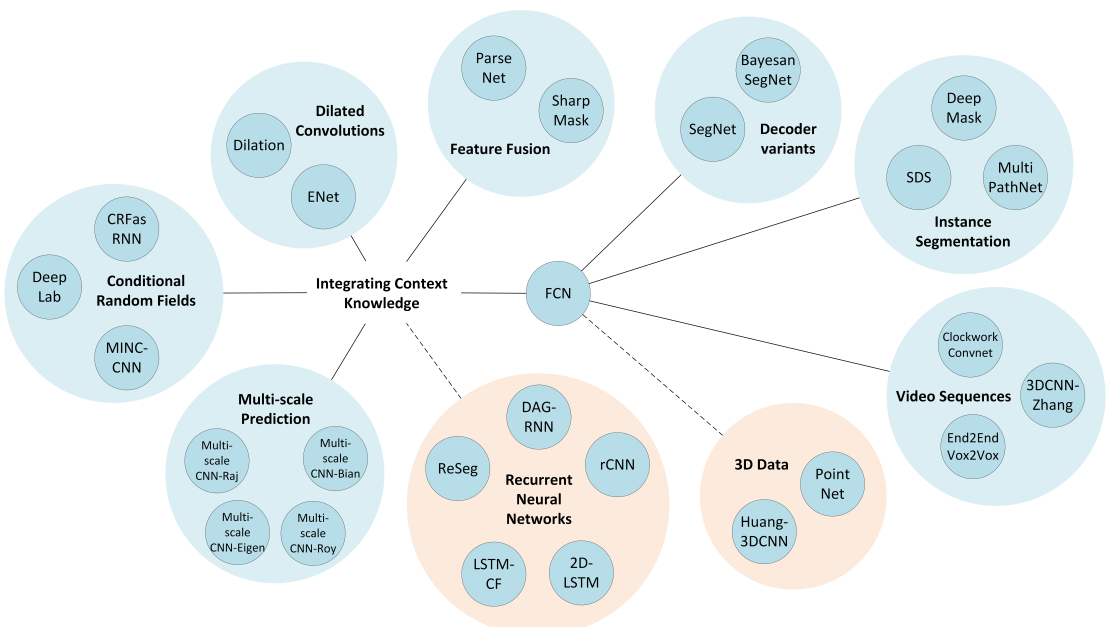
圖 8 所提及方法的形象化展示
儘管FCN模型強大而普適,它任然有著多個缺點從而限制其對於某些問題的應用:其固有的空間不變性導致其沒有考慮到有用的全域性上下文資訊,其並沒有預設考慮對例項的辨識,其效率在高解析度場景下還遠達不到實時操作的能力,並且其不完全適合非結構性資料如3D點雲,或者非結構化模型。這些問題我們將在本節進行綜述,同時給出目前最優的解決這些問題的辦法。表2給出了這個綜述的總結,展示了所有的提及的方法(按照本節中出現的先後排序)、他們所基於的架構、主要的貢獻、以及基於其任務目標的分級:準確率、效率、訓練難度、序列資料處理、多模式輸入以及3D資料處理能力等。每個目標分為3個等級,依賴於對應工作對該目標的專注程度,叉號則代表該目標問題並沒有被該工作考慮進來。另外,圖8對提及方法的關係進行了形象化的描述。
圖 9 SegNet架構示意圖。一個編碼器加一個解碼器,然後是一個softmax分類器用於畫素級別的分類,圖來自[66]。
SegNet [66] 是理解這種區別的很明顯的例子(見圖9)。解碼器部分由一系列的上取樣及卷積層組成,最終接上一個softmax分類器來預測畫素級別的標籤,以此作為輸出,可以達到與輸入影象相同的解析度。解碼器部分的每個上取樣層對應於編碼器中的一個最大池化層,解碼器中的這些層用索引自編碼器階段的對應的特徵對映來進行最大池化,從而對目前的特徵對映進行上取樣。這些上取樣得來的對映接下來將由一系列的可訓練的濾波器集合來進行卷積,從而產生密集的特徵對映。當特徵對映被修復為與原輸入相同解析度的時候,其將被輸入softmax分類器中得到最終的分割結果。
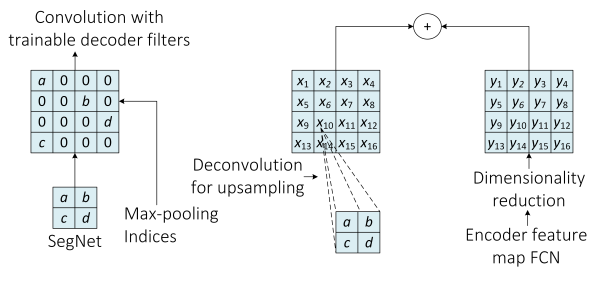
圖 10 SegNet(左)與FCN(右)解碼器的對比。SegNets用對應的編碼器部分最大池化來進行上取樣,而FCN學習出反捲積濾波器來進行上取樣(其中加入編碼器中對應的特徵對映)。圖取自[66]。
而另一方面,基於FCN的架構利用了可學習的反捲積濾波器來對特徵對映進行上取樣,然後,上取樣得到的特徵對映將按照元素優先的方式加入到編碼器部分卷積層得到的對應的特徵對映中。圖10展示了兩種方法的對比。
圖 11 DeepLab中展示的CRF調優每次迭代帶來的影響。第一行是得分對映(softmax之前的層的輸出),第二行是信念對映(softmax的輸出)。
Wild網路[43]中的材質識別使用了多種CNN模型用來識別MINC資料集中的塊。這些CNN模型被以滑動視窗的方式使用,用來分類這些塊,他們的權重值被轉移到FCN的組成網路中,而FCN通過新增對應的上取樣層來整合這些網路。多個輸出取平均便得到了一個平均的對映。最後,與DeepLab中相同的CRF(只不過是離散化優化的)被用來預測與調優每個畫素點處的材質。
應用CRF來調優FCN網路的分割結果的另一個顯著的工作便是Zheng等人提出的CRFasRNN模型[70]。該工作主要的貢獻便是將密集CRF重寫為帶有成對勢能的形式,作為網路的組成部分之一。通過展開均值場推理的各個步驟,並將其視為RNN結構,該工作成功地將CRF與RNN整合在一起成為一個完整的端對端的網路。這篇文章的工作說明了將CRF重寫為RNN模型來構造出深度網路的一部分,與Pinheiro等人[81]的工作行成了對比,而該工作使用RNN來對大規模的空間依賴性進行建模。
4.2.2 擴張的(dilated)卷積
擴張卷積,又稱`a-trous卷積,是對考慮Kronecker的卷積核[96]的擴充套件,而這種卷積核可以指數級地擴大感受野而不丟失解析度。換句話說,擴張卷積是常規的利用上取樣濾波器的方法。擴張率 控制著上取樣因子,如圖12所示,堆疊的以l為擴張率的擴張卷積使得感受野呈現指數級的增長,而濾波器的引數保持線性增長。這意味著擴張卷積可以在任意解析度圖片上高效地提取密集特徵。另外,值得注意的是一般的卷積只是擴張率為1時的特殊情況。

圖 12 [71]所展示的不同擴張率的擴張卷積濾波器。(a)中擴張率為1,每個單元有3*3的感受野;(b)中擴張率為2,每個單元有7*7的感受野;(c)中擴張率為3,每個單元有15*15的感受野。
實際上,這與做正常的卷積之前擴張卷積核是等同的,這意味著根據擴張率擴充其尺寸,為空元素位置補零,換句話說,當擴張率大於1時,濾波器引數將與非近鄰元素相配對。圖13展示了這種擴張的濾波器。
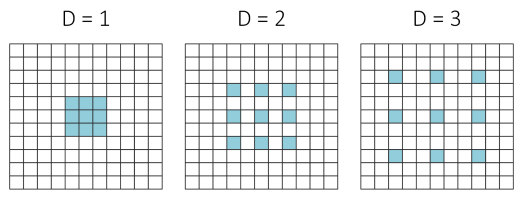
圖 13 濾波器元素根據擴張率與輸入元素進行配對。
使用擴張卷積的最重要的工作便是Yu等人[71]提出的多尺度上下文聚合模型、上文提及的DeepLab模型(其升級版本)[69]、以及實時處理網路ENet[72]。所有這些將越來越大的各種擴張率結合,使得模型具有更大的感受野,同時不增添額外的消耗,也不會過度地對特徵對映進行下采樣。這些工作同時具有相同的趨勢:擴張卷積與緊密多尺度上下文聚合緊密耦合,這我們將在後面章節中解釋。
4.2.3 多尺度預測
整合上下文知識的另一種可能的做法便是使用多尺度預測。CNN中幾乎每個單獨的引數都會影響到得到的特徵對映的大小,換句話說,非常相似的架構也會對輸入影象的畫素數量產生較大的影響,而這關係到每個特徵對映。這意味著濾波器將會潛在地檢測特定尺度的特徵(大致上有著特定的程度)。另外,網路的引數一般都與要解決的問題息息相關,也使得模型向不同尺度的擴充套件變得更難。一種可能的解決方案便是使用多尺度的網路,這種網路一般都是選用多個處理不同尺度的網路,最後將他們的預測結果結合,產生一個單一的輸出。
Raj等人[73] 提出了全卷積VGG-16的一種多尺度版本,有著兩個路徑,一個是在原始解析度上處理輸入,使用的是一個淺層的卷積網路,再一個就是在兩倍解析度上處理,使用全卷積VGG-16和一個額外的卷積層。第二個路徑的結果經過上取樣後與第一個路徑的結果相結合,這個串聯起來的結果再經過一系列的卷積層,得到最終的輸出。這樣,這個網路便對尺度變換更加魯棒了。
Roy等人[75] 採取了另外的方法解決這個問題,他們選用了包含4個多尺度CNN的網路,而這4個網路有著相同的架構,取自Eigen等人[74]。其中之一致力於為當前場景找出語義標籤。這個網路(整體上)以一個從粗糙到精細的尺度序列來逐步的提取特徵(如圖14)。
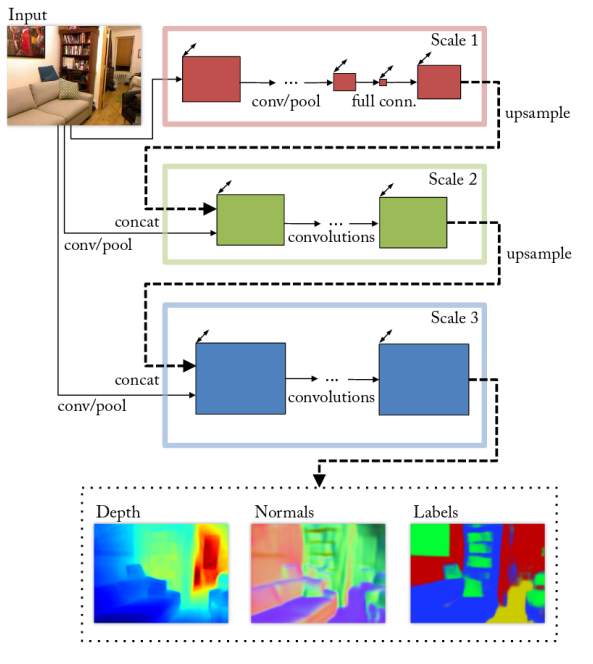
圖 14 [74]中提出的多尺度CNN架構,利用一個尺度序列預測深度、法向來逐步將輸出調優,並且對一個RGB的輸入執行語義分割。
另一個重要的工作是Bian等人[76]提出的網路,這個網路包含n個FCN,可以處理不同尺度的問題。該網路提取的特徵將融合在一起(先使用合適的填充方法進行必要的上取樣),然後通過一個額外的卷積層之後得到最終的分割結果。這個工作的主要貢獻便是這個兩步的學習過程,首先,獨立的訓練每個網路,然後,這些網路將結合,最後一層將被微調。這種多尺度的模型可以高效地新增任意數量的訓練好的網路進來。
4.2.4 特徵融合
在分割問題中,向全卷積神經網路架構中加入上下文資訊的另一種方式便是進行特徵融合。特種融合技術將一個全域性特徵(由某網路中較前面的層提取得到)與一個相對區域性的特徵對映(後邊的層提取得)相結合。常見的架構如原始FCN網路利用跳躍連線的方式進行延遲特徵融合,也是通過將不用層產生的特徵對映相結合(圖15)。

圖 15 類似跳躍連線的架構,對特徵對映進行延遲融合,其類似於在每個層上做出獨立的預測後再對結果進行融合。圖來自[84]。(注:每個層均有“分割結果”,最後融合之)
另一種方法便是提前融合,這一方法來自ParseNet[77]中的上下文模組。全域性特徵被反池化為與區域性特徵相同的尺寸,然後,將這兩種特徵進行串聯後得到一個合併的特徵,輸入到下一層或者直接用於分類器的學習。如圖16所示。
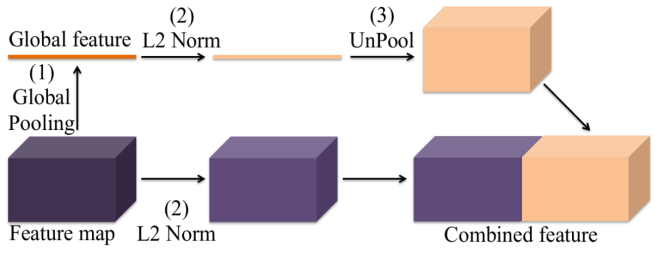
圖 16 ParseNet中的上下文模組示意圖。較前面的層產生的全域性特徵與其下一層產生的特徵相結合,以此來新增上下文的資訊。圖來自[77]。
SharpMask[84] 這個工作繼續發展了這種特徵融合的想法,其引入了一種先進的調優模組來將前面層產生的特徵合併到後面的層,這個模組使用的是一種自上而下的架構。由於其重點關注例項分割方面,所以這個工作我們將在後面章節介紹。
4.2.5 迴圈神經網路RNN
我們注意到,CNN網路在非一維資料如影象等的處理上取得了成功,但是,這些網路依賴於手工設計的核,將網路限制於區域性上下文中。而得益於其拓撲結構,迴圈神經網路成功地應用到了對長期或短期序列的建模上。這樣,通過將畫素級別的以及區域性的資訊聯絡起來,RNN可以成功地建模全域性上下文資訊並改善語義分割結果。但是,一個重要的問題便是,圖片中缺乏自然的序列結構,而標準的RNN架構關注的恰恰是一維的輸入。
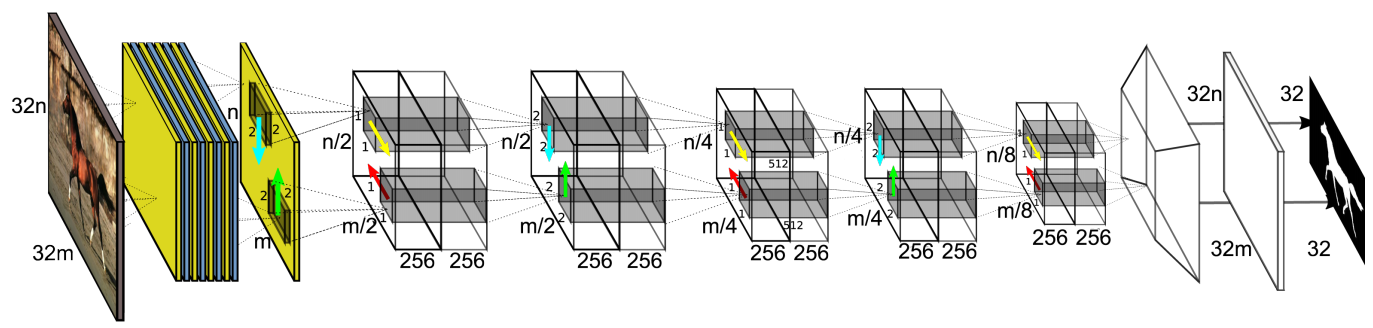
圖 17 ReSeg網路示意圖。VGG-16的卷積層以第一層中的藍色和黃色層展示,餘下的架構基於微調目的的ReNet,圖取自[78]。
基於面向分類的ReNet模型,Visin等人[19]提出了ReSeg模型[78]用於語義分割,如圖17所示。在本方法中,輸入影象在第一層VGG-16層中被處理,特徵對映結果送入一個或更多的ReNet層中來進行微調。最終,特徵對映的尺寸被調整,使用的是基於反捲積的上取樣層。在本方法中,門迴圈單元(GRU)被用來平衡佔用空間與計算複雜度。一般的RNN在建模長期依賴關係時表現不好,主要是因為梯度消失問題的存在。由此產生的長短期記憶網路(LSTM)[97] 和GRU [98]是該領域目前最好的兩種方法,可以避免以上問題。
受ReNet架構的啟發,有人為場景標註問題提出了一種新型的長短期記憶上下文融合模型(LSTM-CF)[99]。該方法使用了兩種不同的資料來源:RGB資訊和深度資訊。基於RGB的部分依賴於DeepLab架構[29]的變體,串聯了三種不同尺度的特徵來豐富特徵表達(由[100]處獲得啟發)。全域性資訊在兩個部分(深度資訊部分與光學資訊部分)都是豎直的,最終這兩種豎直的上下文資訊在水平方向上被融合。
我們注意到,對影象全域性上下文資訊的建模與二維迴圈方法很有關係,只需在輸入影象上按照水平和豎直方向分別將網路展開。基於相同的想法,Byeon等人[80]提出了簡單的二維的基於LSTM的架構,其中的輸入影象被分割為無重疊的視窗,然後將其送入四個獨立的LSTM記憶單元。該工作突出貢獻是其計算複雜度較低、執行與單個CPU以及其模型的簡單性。
另一種捕獲全域性資訊的方法依賴於更大的輸入視窗的使用,這樣就可以建模更大範圍內的上下文資訊。但是,這也降低了影象的解析度,而且引入了其他類似於視窗重疊等的問題。然而,Pinheiro等人[81] 引入了迴圈卷積神經網路(rCNN)來使用不同的視窗大小迴圈地訓練,這相當於考慮了之前層中的預測資訊。通過這種方法,預測出的標籤將自動地平滑,從而使網路表現更好。
無向迴圈圖(UCG)同樣被用來建模影象上下文資訊從而用於語義分割[82]。但是,RNN並不直接適用於UCG,為了解決這個問題,無向迴圈圖被分解為了多個有向圖(DAG)。在本方法中,影象在三個不同的層中被處理,分別是:CNN處理得到影象的特徵對映,DAG-RNN對影象的上下文依賴資訊進行建模,反捲積層將特徵對映上取樣。這個工作說明了RNN如何可以與圖相結合,被用來建模長期範圍內的上下文依賴,並超過已有的最優方法。
圖 18 SharpMask中的自上而下逐步調優的結構,這種調優是通過將底層特徵與上層中編碼的高層特徵想融合,來實現空間上豐富資訊融合的目的。圖來自[83]。
另一種方法由Zagoruyko等人[85]提出,使用快速R-CNN作為起點,使用DeepMask的物體提議而不是選擇性搜尋。這種結合多種方法的系統成為多路分類器,提高了COCO資料集上的表現,對於快速R-CNN做出了三處修改:使用整合的損失項改善了定位能力,使用中心區域提供上下文資訊,以及最終跳過連線來為網路給出多尺度的特徵。該系統相對於快速R-CNN取得了66%的提升。
可以看出,多數提到的方法依賴於現有的物體檢測方法,這限制了模型的表現。即使這樣,例項分割過程依然有很多問題未被解決,上述方法僅僅是這個有挑戰性的方向的一小部分。
圖 19 Huang等人[86]提出的基於3DCNN的點雲語義標註系統。點雲經過一個密集的體元化處理過程,CNN將處理得到的每一個體元,然後將結果映射回原來的點雲。圖片來自[86]。
PointNet[87]是一個先驅性的工作,提出了一種深度神經網路來將原始的點雲作為輸入,給出了一個同時進行分類和分割的聯合的架構。圖20展示了這種可以處理無序三維點集的雙模組的網路。
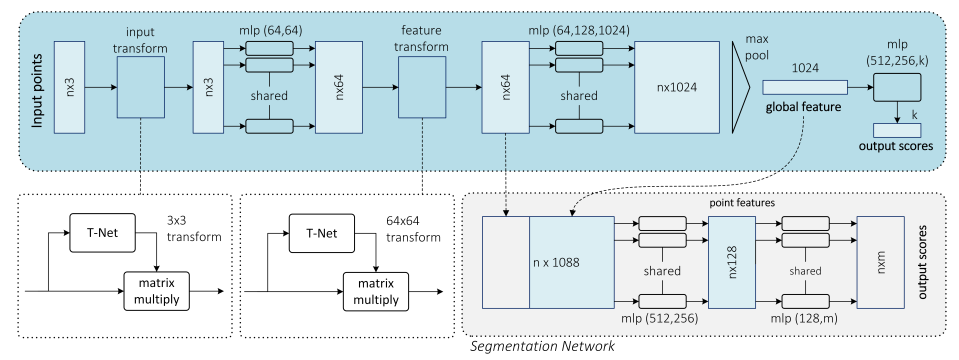
圖 20 PointNet聯合結構,用於分類和分割,圖來自[87]。
我們可以看出,PointNet是一種與眾不同的深度網路架構,因為其基於全連線層而不是卷積層。該模型分為兩部分,分別負責分類和分割。分類子網路以點云為輸入,採用一系列變換以及多層感知機(MLP)來生成特徵,然後使用最大池化來生成全域性特徵以描述原輸入的點雲。另外的MLP將對這些全域性特徵進行分類,然後為每一個類得出分數。分割子網路將全域性特徵與分類網路生成的每個點的特徵串聯起來,然後應用另外的兩個MLP來生成特徵,並計算出每個點屬於每一類的得分。
圖 21 三階段的時鐘FCN模型,以及其對應的時鐘速率。圖來自[88]。
值得注意的是,作者提出了兩種更新速率的策略:固定的和自適應的。固定的策略直接為每個階段設定一個常數時間來重新計算特徵。自適應策略則使用資料驅動的方法來設定時鐘,例如,時鐘依賴於運動或語義改變的數量。圖22展示了這種自適應策略的例子。
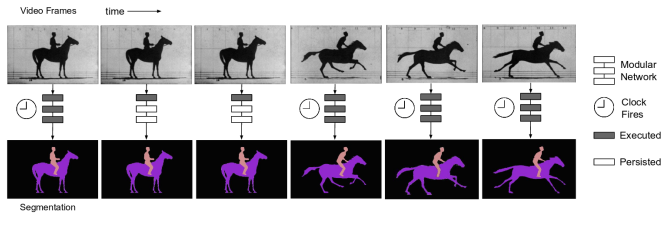
圖 22 Shelhamer等人[88]提出的自適應的時鐘方法。提取出的特徵在靜止的幀將會被保留,而在動態的幀時將會被重新計算。圖來自[88]。
Zhang等人[106]採用了一種不同的方式,使用了3DCNN這種原本被設計來學習三維體資料特徵的方法,以此來從多通道輸入如視訊片段中學出層次化的時空聯合特徵。與此同時,該工作將輸入片段過分割為超體元,然後利用這些超體元圖並將學得的特徵嵌入其中,最終將在超體元圖上應用graph-cut[107]來得到分割結果。
另一個重要的方法採用了三維卷積的思想,是由Tran等人[89]提出的一種深度的端對端的、體元對體元的預測系統。該方法將自己提出的三維卷積(C3D)網路應用於先前的工作[108]中,在最後添加了反捲積層以將其擴充套件為面向語義分割的演算法。該系統將輸入的視訊片段分為包含16個幀的小片段,對每個片段單獨進行預測。其主要的貢獻在於其使用的三維卷積技術。這種卷積技術使用了三維的濾波器,適應了從多通道資料中學出的時空聯合特徵,圖23展示了應用到多通道輸入資料上的二維和三維卷積的不同之處,證明了視訊分割情況下三維卷積核的有用性。
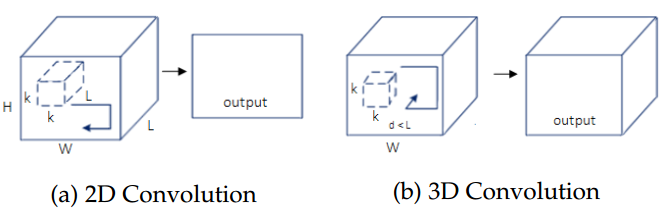
圖 23 應用於一系列的幀的時候,二維和三維卷積的不同。(a)中,二維卷積在各個幀(多通道)的各個深度使用的是相同的權重,產生的是一個單一的影象。(b)三維卷積使用的是三維的濾波器,卷積後產生的是三維體元,因此保留了幀序列的時間資訊。 表 3 PASCAL VOC 2012 上的表現結果
除了最常見的VOC資料集,我們還收集了在上下文資料集上各方法的準確率,表4給出了結果統計,DeepLab依然是最高(IoU為45.70)。
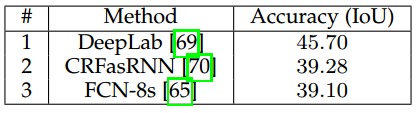
表 4 PASCAL上下文資料集上的表現結果
另外,我們考慮了PASCAL人物部分,結果見表5。在本資料集上僅有DeepLab進行了實驗,結果IoU是64.94。

表 5 PASCAL人物部分資料集的表現結果
上面考慮了通用目標的資料集如PASCAL VOC,接下來我們收集了兩種最重要的城市駕駛資料集上的結果。表6給出了CamVid資料集上的方法的結果,一種基於RNN的方法即DAG-RNN取得了最優的IoU為91.60。
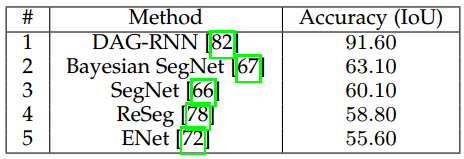
表 6 CamVid資料集上的表現結果
表7給出了更具挑戰性且目前更常用的資料集及CityScape資料集上的結果。其表現出的趨勢與PASCAL VOC上的相似,DeepLab以IoU70.40領跑。

表 7 CityScape資料集上的結果
表8給出了多種迴圈網路在斯坦福背景資料集上的結果,rCNN取得了最好的結果,其最大IoU為80.20。

表 8 斯坦福背景資料集上的結果
最後,其它常見資料集如SiftFlow等的結果在表9中展示。這個資料集同樣被迴圈方法所霸佔,尤其是DAG-RNN取得了最好的IoU85.30。
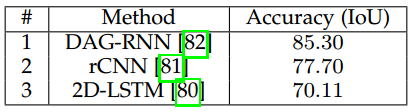
表 9 SiftFlow上的結果
5.2.2 2.5維資料
對於2.5為資料這一分類,也就是資料中不僅包含RGB三個通道,還包含深度資訊,我們選擇了三個資料集進行分析,分別是SUN-RGB-D、NYUDv2、SUN3D。表10、11、12分別給出了這三個資料集上的結果。

表 10 SUN-RGB-D上的結果

表 11 NYUDv2上的結果

表 12 SUN3D上的結果
5.2.3 三維資料
選用了兩個三維資料集:ShapeNet Part和Stanford-2D-3D-S。表13和表14分別展示了其結果。

表 13 ShapeNet Part資料集上的結果

表 14 Stanford-2D-3D-S資料集上的結果
5.2.4 序列資料
最後一個分類便是視訊或序列資料資料集。我們選取了兩個適合於序列分割的資料集:CityScapes和YouTube-Objects。表15和表16分別展示了結果。

表 15 CityScapes資料集上的結果

表 16 Youtube-Objects資料集上的結果
|
摘要 計算機視覺與機器學習研究者對影象語義分割問題越來越感興趣。越來越多的應用場景需要精確且高效的分割技術,如自動駕駛、室內導航、甚至虛擬現實與增強現實等。這個需求與視覺相關的各個領域及應用場景下的深度學習技術的發展相符合,包括語義分割及場景理解等。這篇論文回顧了各種應用場景下利用深度學習技術解決語義分割問題的情況:首先,我們引入了領域相關的術語及必要的背景知識;然後,我們介紹了主要的資料集以及對應的挑戰,幫助研究者選取真正適合他們問題需要及目標的資料集;接下來,我們介紹了現有的方法,突出了各自的貢獻以及對本領域的積極影響;最後,我們展示了大量的針對所述方法及資料集的實驗結果,同時對其進行了分析;我們還指出了一系列的未來工作的發展方向,並給出了我們對於目前最優的應用深度學習技術解決語義分割問題的研究結論。 |
||||||
|
1 導言 如今,語義分割(應用於靜態2D影象、視訊甚至3D資料、體資料)是計算機視覺的關鍵問題之一。在巨集觀意義上來說,語義分割是為場景理解鋪平了道路的一種高層任務。作為計算機視覺的核心問題,場景理解的重要性越來越突出,因為現實中越來越多的應用場景需要從影像中推理出相關的知識或語義(即由具體到抽象的過程)。這些應用包括自動駕駛[1,2,3],人機互動[4],計算攝影學[5],影象搜尋引擎[6],增強現實等。應用各種傳統的計算機視覺和機器學習技術,這些問題已經得到了解決。雖然這些方法很流行,但深度學習革命讓相關領域發生了翻天覆地的變化,因此,包括語義分割在內的許多計算機視覺問題都開始使用深度架構來解決,通常是卷積神經網路CNN[7-11],而CNN在準確率甚至效率上都遠遠超過了傳統方法。然而,相比於固有的計算機視覺及機器學習分支,深度學習還遠不成熟。也因此,還沒有一個統一的工作及對於目前最優方法的綜述。該領域的飛速發展使得對初學者的啟蒙教育比較困難,而且,由於大量的工作相繼被提出,要跟上發展的步伐也非常耗時。於是,追隨語義分割相關工作、合理地解釋它們的論點、過濾掉低水平的工作以及驗證相關實驗結果等是非常困難的。 就我所知,本文是第一篇致力於綜述用於語義分割的深度模型技術的文章。已經有較多的關於語義分割的綜述調查,比如[12,13]等,這些工作在總結、分類現有方法、討論資料集及評價指標以及為未來研究者提供設計思路等方面做了很好的工作。但是,這些文章缺少對某些最新資料集的介紹,他們不去分析框架的情況,而且沒有提供深度學習技術的細節。因此,我們認為本文是全新的工作,而且這對於深度學習相關的語義分割社群有著重要意義。
|
||||||
|
2 術語及背景概念 為了更好地理解語義分割問題是如何用深度學習框架解決的,有必要了解到其實基於深度學習的語義分割並不是一個孤立的領域,而是在從粗糙推理到精細化推理過程中很自然的一步。這可以追溯到分類問題,包括對整個輸入做出預測,即預測哪個物體是屬於這幅影象的,或者給出多個物體可能性的排序。對於細粒度推理來說,將接下來進行物體的定位與檢測,這將不止提供物體的類別,而且提供關於各類別空間位置的額外資訊,比如中心點或者邊框。這樣很顯然,語義分割是實現細粒度推理的很自然的一步,它的目標是:對每個畫素點進行密集的預測,這樣每個畫素點均被標註上期對應物體或區域的類別。這還可以進一步改進,比如例項分割(即對同一類的不同例項標以不同的標籤),甚至是基於部分的分割(即對已經分出不同類別的影象進行底層分解,找到每個類對應的組成成分)。圖1展示了以上提到的演變過程。在本文中,我們主要關注一般的場景標註,也就是畫素級別的分割,但是我們也會回顧例項分割及基於部分的分割的較重要的方法。 最後,畫素級別的標註問題可以鬆弛為以下公式:對於隨機變數集合 中的每個隨機變數,找到一種方法為其指派一個來自標籤空間 中的一個狀態。每個標籤 表示唯一的一個類或者物體,比如飛機、汽車、交通標誌或背景等。這個標籤空間有 個可能的狀態,通常會被擴充套件為 +1個,即視 為背景或者空的類。通常, 是一個二維的影象,包含W*H=N的畫素點x。但是,這個隨機變數的集合可以被擴充套件到任意維度,比如體資料或者超譜影象。 除了問題的定義,回顧一些可能幫助讀者理解的背景概念也是必要的。首先是一些常見的被用作深度語義分割系統的網路、方法以及設計決策;另外還有用於訓練的一些常見的技術比如遷移學習等。最後是資料的預處理以及增強式的方法等。 |
||||||
|
2.1 常見的深度網路架構 正如之前所講,某些深度網路已經對該領域產生了巨大的貢獻,並已成為眾所周知的領域標準。這些方法包括AlexNet,VGG-16,GoogLeNet,以及ResNet。還有一些是由於其被用作許多分割架構的一部分而顯得重要。因此,本文將在本章致力於對其進行回顧。 2.1.1 AlexNet AlexNet(以作者名字Alex命名)首創了深度卷積神經網路模型,在2012年ILSVRC(ImageNet大規模影象識別)競賽上以top-5準確率84.6%的成績獲勝,而與之最接近的競爭者使用了傳統的而非深度的模型技術,在相同的問題下僅取得了73.8%的準確率。由Krizhecsky等人[14]給出的架構相對簡單,包括卷積層、max-pooling層及ReLU層各五層作為非線性層,全連線層三層以及dropout層。圖2給出了這個架構的示意。
|
||||||
|
2.2 遷移學習 從頭訓練一個深度神經網路通常是不可行的,有這樣兩個原因:訓練需要足量的資料集,而這一般是很難得到的;網路達到收斂需要很長的時間。即便得到了足夠大的資料集並且網路可以在短時間內達到收斂,從之前的訓練結果中的權重開始訓練也總比從隨機初始化的權重開始訓練要好[20,21]。遷移學習的一種重要的做法便是從之前訓練好的網路開始繼續訓練過程來微調模型的權重值。 Yosinski等人[22]證明了即便是從較不相關的任務中遷移學習來的特徵也要比直接從隨機初始化學習的特徵要好,這個結論也考慮到了隨著提前訓練的任務與目標任務之間差異的增大,可遷移性將減小的情況。 然而,遷移學習技術的應用並沒有如此的直接。一方面,使用提前訓練的網路必須滿足網路架構等的約束,不過,因為一般不會新提出一個全新的網路結構來使用,所以使用現有的網路架構或網路元件進行遷移學習是常見的;另一方面,遷移學習中的訓練過程本身相對於從頭開始的訓練過程來說區別非常小。合理選擇進行微調的層是很重要的,一般選網路中較高的層因為底層一般傾向於保留更加通用的特徵;同時,合理地確定學習率也是重要的,一般選取較小的值,因為一般認為提前訓練的權重相對比較好,無需過度修改。 由於收集和建立畫素級別的分割標註資料集的內在的困難性,這些資料集的規模一般不如分類資料集如ImageNet[23,24]等的大。分割研究中資料集的規模問題在處理RGB-D或3D資料集時更加嚴重,因為這些資料集規模更小。也因此,遷移學習,尤其是從提前訓練好的分類網路中微調而來的方式,將會成為分割領域的大勢所趨,並且已經有方法成功地進行了應用,我們將在後面幾章進行回顧。 |
||||||
|
2.3 資料預處理與資料增強 資料增強技術被證明了有利於通用的尤其是深度的機器學習架構的訓練,無論是加速收斂過程還是作為一個正則項,這也避免了過擬合併增強了模型泛化能力[15]。 資料增強一般包括在資料空間或特徵空間(或二者均有)上應用一系列的遷移技術。在資料空間上應用增強技術最常見,這種增強技術應用遷移方法從已有資料中得到新的樣本。有很多的可用的遷移方法:平移、旋轉、扭曲、縮放、顏色空間轉換、裁剪等。這些方法的目標均是通過生成更多的樣本來構建更大的資料集,防止過擬合以及對模型進行正則化,還可以對該資料集的各個類的大小進行平衡,甚至手工地產生對當前任務或應用場景更加具有代表性的新樣本。 資料增強對小資料集尤其有用,而且其效用已經在長期使用過程中被證明。例如,在[26]中,有1500張肖像圖片的資料集通過設計4個新的尺寸(0.6,0.8,1.2,1.5),4個新的旋角(-45,-22,22,45),以及4個新的gamma變化(0.5,0.8,1.2,1.5)被增強為有著19000張訓練影象的資料集。通過這一處理,當使用增強資料集進行微調時,其肖像畫分割系統的交疊準確率(IoU)從73.09%提升到了94.20%。 |
||||||
|
3 資料集及競賽 以下兩種讀者應該閱讀本部分內容:一是剛剛開始研究本領域問題的讀者,再就是已經很有經驗但是想了解最近幾年其他研究者研究成果的可取之處的讀者。雖然第二種讀者一般很明確對於開始語義分割相關的研究來說資料集及競賽是很重要的兩個方面,但是對於初學者來說掌握目前最優的資料集以及(主流的)競賽是很關鍵的。因此,本章的目標便是對研究者進行啟發,提供一個對資料集的簡要總結,這裡面可能有正好他們需求的資料集以及資料增強或預處理等方面的技巧。不過,這也可以幫助到已經有深入研究的工作者,他們可能想要回顧基礎或者挖掘新的資訊。 值得爭辯的是,對於機器學習來說資料是最重要的或者最重要的之一。當處理深度網路時,這種重要性更加明顯。因此,收集正確的資料放入資料集對於任何基於深度學習的分割系統來說都是極為重要的。收集與建立一個足夠大而且能夠正確代表系統應用場景的資料集,需要大量的時間,需要領域專門知識來挑選相關資訊,也需要相關的基礎設施使得系統可以正確的理解與學習(捕捉到的資料)。這個任務的公式化過程雖然相比複雜的神經網路結構的定義要簡單,但是其解決過程卻是相關工作中最難的之一。因此,最明智的做法通常是使用一個現存的足夠可以代表該問題應用場景的標準資料集。使用標準資料集還有一個好處就是可以使系統間的對比更加公平,實際上,許多資料集是為了與其他方法進行對比而不是給研究者測試其演算法的,在對比過程中,會根據方法的實際表現得到一個公平的排序,其中不涉及任何資料隨機選取的過程。 接下來我們將介紹語義分割領域最近最受歡迎的大規模資料集。所有列出的資料集均包含畫素級別或點級別的標籤。這個列表將根據資料內在屬性分為3個部分:2維的或平面的RGB資料集,2.5維或帶有深度資訊的RGB(RGB-D)資料集,以及純體資料或3維資料集。表1給出了這些資料集的概覽,收錄了所有本文涉及的資料集並提供了一些有用資訊如他們的被構建的目的、類數、資料格式以及訓練集、驗證集、測試集劃分情況。
|
||||||
|
3.1 二維資料集 自始至終,語義分割問題最關注的是二維影象。因此,二維資料集在所有型別中是最豐富的。本章我們討論語義分割領域最流行的二維大規模資料集,這考慮到所有的包含二維表示如灰度或RGB影象的資料集。 PASCAL視覺物體分類資料集(PASCAL-VOC)[27] (http://host.robots.ox.ac.uk/pascal/VOC/voc2012/) : 包括一個標註了的影象資料集和五個不同的競賽:分類、檢測、分割、動作分類、人物佈局。分割的競賽很有趣:他的目標是為測試集裡的每幅影象的每個畫素預測其所屬的物體類別。有21個類,包括輪子、房子、動物以及其他的:飛機、自行車、船、公共汽車、轎車、摩托車、火車、瓶子、椅子、餐桌、盆栽、沙發、顯示器(或電視)、鳥、貓、狗、馬、綿羊、人。如果某畫素不屬於任何類,那麼背景也會考慮作為其標籤。該資料集被分為兩個子集:訓練集1464張影象以及驗證集1449張影象。測試集在競賽中是私密的。爭議的說,這個資料集是目前最受歡迎的語義分割資料集,因此很多相關領域卓越的工作將其方法提交到該資料集的評估伺服器上,在其測試集上測試其方法的效能。方法可以只用該資料集訓練,也可以藉助其他的資訊。另外,其方法排行榜是公開的而且可以線上查詢。
PASCAL 上下文資料集(PASCAL Context) [28] (http://www.cs.stanford.edu/∼roozbeh/pascal-context/):對於PASCAL-VOC 2010識別競賽的擴充套件,包含了對所有訓練影象的畫素級別的標註。共有540個類,包括原有的20個類及由PASCAL VOC分割資料集得來的圖片背景,分為三大類,分別是物體、材料以及混合物。雖然種類繁多,但是隻有59個常見類是較有意義的。由於其類別服從一個冪律分佈,其中有很多類對於整個資料集來說是非常稀疏的。就這點而言,包含這59類的子集常被選作真實類別來對該資料集進行研究,其他類別一律重標為背景。
PASCAL 部分資料集(PASCAL Part)[29] (http://www.stat.ucla.edu/∼xianjie.chen/pascal part dataset/pascal part.html):對於PASCAL-VOC 2010識別競賽的擴充套件,超越了這次競賽的任務要求而為影象中的每個物體的部分提供了一個畫素級別的分割標註(或者當物體沒有連續的部分的時候,至少是提供了一個輪廓的標註)。原來的PASCAL-VOC中的類被保留,但被細分了,如自行車被細分為後輪、鏈輪、前輪、手把、前燈、鞍座等。本資料集包含了PASCAL VOC的所有訓練影象、驗證影象以及9637張測試影象的標籤。
語義邊界資料集(SBD)[30] (http://home.bharathh.info/home/sbd):是PASCAL資料集的擴充套件,提供VOC中未標註影象的語義分割標註。提供PASCAL VOC 2011 資料集中11355張資料集的標註,這些標註除了有每個物體的邊界資訊外,還有類別級別及例項級別的資訊。由於這些影象是從完整的PASCAL VOC競賽中得到的,而不僅僅是其中的分割資料集,故訓練集與驗證集的劃分是不同的。實際上,SBD有著其獨特的訓練集與驗證集的劃分方式,即訓練集8498張,驗證集2857張。由於其訓練資料的增多,深度學習實踐中常常用SBD資料集來取代PASCAL VOC資料集。
微軟常見物體環境資料集(Microsoft COCO) [31]:(http://mscoco.org/) 是另一個大規模的影象識別、分割、標註資料集。它可以用於多種競賽,與本領域最相關的是檢測部分,因為其一部分是致力於解決分割問題的。該競賽包含了超過80個類別,提供了超過82783張訓練圖片,40504張驗證圖片,以及超過80000張測試圖片。特別地,其測試集分為4個不同的子集各20000張:test-dev是用於額外的驗證及除錯,test-standard是預設的測試資料,用來與其他最優的方法進行對比,test-challenge是競賽專用,提交到評估伺服器上得出評估結果,test-reserve用於避免競賽過程中的過擬合現象(當一個方法有嫌疑提交過多次或者有嫌疑使用測試資料訓練時,其在該部分子集上的測試結果將會被拿來作比較)。由於其規模巨大,目前已非常常用,對領域發展很重要。實際上,該競賽的結果每年都會在ECCV的研討會上與ImageNet資料集的結果一起公佈。
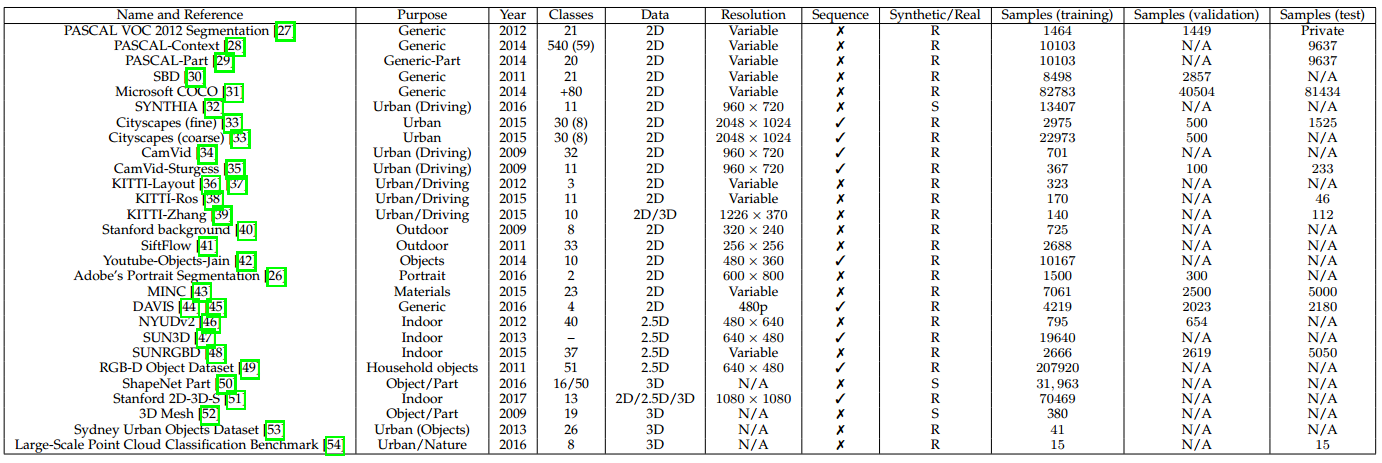
影象與註釋合成數據集(SYNTHIA)[32] (http://synthia-dataset.net/)是一個大規模的虛擬城市的真實感渲染圖資料集,帶有語義分割資訊,是為了在自動駕駛或城市場景規劃等研究領域中的場景理解而提出的。提供了11個類別物體(分別為空、天空、建築、道路、人行道、柵欄、植被、杆、車、訊號標誌、行人、騎自行車的人)細粒度的畫素級別的標註。包含從渲染的視訊流中提取出的13407張訓練影象,該資料集也以其多變性而著稱,包括場景(城鎮、城市、高速公路等)、物體、季節、天氣等。
城市風光資料集 [33] (https://www.cityscapes-dataset.com/)是一個大規模的關注於城市街道場景理解的資料集,提供了8種30個類別的語義級別、例項級別以及密集畫素標註(包括平坦表面、人、車輛、建築、物體、自然、天空、空)。該資料集包括約5000張精細標註的圖片,20000張粗略標註的圖片。資料是從50個城市中持續數月採集而來,涵蓋不同的時間以及好的天氣情況。開始起以視訊形式儲存,因此該資料集按照以下特點手動選出視訊的幀:大量的動態物體,變化的場景佈局以及變化的背景。
CamVid資料集 [55,34] (http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/)是一個道路、駕駛場景理解資料集,開始是五個視訊序列,來自一個安裝在汽車儀表盤上的960x720解析度的攝相機。這些序列中取樣出了701個幀(其中4個序列在1fps處,1個序列在15fps處),這些靜態圖被手工標註上32個類別:空、建築、牆、樹、植被、柵欄、人行道、停車場、柱或杆、錐形交通標誌、橋、標誌、各種文字、訊號燈、天空、……(還有很多)。值得注意的是,Sturgess等人[35]將資料集按照367-100-233的比例分為訓練集、驗證集、測試集,這種分法使用了部分類標籤:建築、樹、天空、車輛、訊號、道路、行人、柵欄、杆、人行道、騎行者。
KITTI [56] 是用於移動機器人及自動駕駛研究的最受歡迎的資料集之一,包含了由多種形式的感測器得出的數小時的交通場景資料,包括高解析度RGB、灰度立體攝像機以及三維鐳射掃描器。儘管很受歡迎,該資料集本身並沒有包含真實語義分割標註,但是,眾多的研究者手工地為該資料集的部分資料新增標註以滿足其問題的需求。Alvarez等人[36,37]為道路檢測競賽中的323張圖片生成了真實標註,包含三個類別:道路、垂直面和天空。Zhang等人[39]標註了252張圖片,其中140張訓練、112張測試,其選自追蹤競賽中的RGB和Velodyne掃描資料,共十個類。Ros等人[38]在視覺測距資料集中標註了170個訓練圖片和46個測試圖片,共11個類。
YouTube物體資料集 [57] 是從YouTube上採集的視訊資料集,包含有PASCAL VOC中的10個類。該資料集不包含畫素級別的標註,但是Jain等人[42]手動的標註了其126個序列的子集。其在這些序列中每10個幀選取一張圖片生成器語義標籤,總共10167張標註的幀,每幀480x360的解析度。
Adobe肖像分割資料集 [26] (http://xiaoyongshen.me/webpage portrait/index.html) 包含從Flickr中收集的800x600的肖像照片,主要是來自手機前置攝像頭。該資料集包含1500張訓練圖片和300張預留的測試圖片,這些圖片均完全被二值化標註為人或背景。圖片被半自動化的標註:首先在每幅圖片上執行一個人臉檢測器,將圖片變為600x800的解析度,然後,使用Photoshop快速選擇工具將人臉手工標註。這個資料集意義重大,因為其專門適用於人臉前景的分割問題。
上下文語料資料集(MINC)[43] 是用於對塊進行分類以及對整個場景進行分割的資料集。該資料集提供了23個類的分割標註(文中有詳細的各個類別的名稱),包含7061張標註了的分割圖片作為訓練集,5000張的測試集和2500張的驗證集。這些圖片均來自OpenSurfaces資料集[58],同時使用其他來源如Flickr或Houzz進行增強。因此,該資料集中的影象的解析度是變化的,平均來看,圖片的解析度一般是800x500或500x800。
密集標註的視訊分割資料集(DAVIS)[44,45](http://davischallenge.org/index.html):該競賽的目標是視訊中的物體的分割,這個資料集由50個高清晰度的序列組成,選出4219幀用於訓練,2023張用於驗證。序列中的幀的解析度是變化的,但是均被降取樣為480p的。給出了四個不同類別的畫素級別的標註,分別是人、動物、車輛、物體。該資料集的另一個特點是每個序列均有至少一個目標前景物體。另外,該資料集特意地較少不同的大動作物體的數量。對於那些確實有多個前景物體的場景,該資料集為每個物體提供了單獨的真實標註,以此來支援例項分割。
斯坦福背景資料集[40] (http://dags.stanford.edu/data/iccv09Data.tar.gz)包含了從現有公開資料集中採集的戶外場景圖片,包括LabelMe, MSRC, PASCAL VOC 和Geometric Context。該資料集有715張圖片(320x240解析度),至少包含一個前景物體,且有影象的水平位置資訊。該資料集被以畫素級別標註(水平位置、畫素語義分類、畫素幾何分類以及影象區域),用來評估場景語義理解方法。
SiftFlow [41]:包含2688張完全標註的影象,是LabelMe資料集[59]的子集。多數影象基於8種不同的戶外場景,包括街道、高山、田地、沙灘、建築等。影象是256x256的,分別屬於33個語義類別。未標註的或者標為其他語義類別的畫素被認為是空。
|
||||||
|
3.2 2.5維資料集 隨著廉價的掃描器的到來,帶有深度資訊的資料集開始出現並被廣泛使用。本章,我們回顧最知名的2.5維資料集,其中包含了深度資訊。 NYUDv2資料集[46](http://cs.nyu.edu/∼silberman/projects/indoor scene seg sup.html)包含1449張由微軟Kinect裝置捕獲的室內的RGB-D影象。其給出密集的畫素級別的標註(類別級別和實力級別的均有),訓練集795張與測試集654張均有40個室內物體的類[60],該資料集由於其刻畫室內場景而格外重要,使得它可以用於某種家庭機器人的訓練任務。但是,它相對於其他資料集規模較小,限制了其在深度網路中的應用。
SUN3D資料集[47](http://sun3d.cs.princeton.edu/):與NYUDv2資料集相似,該資料集包含了一個大規模的RGB-D視訊資料集,包含8個標註了的序列。每一幀均包含場景中物體的語義分割資訊以及攝像機位態資訊。該資料集還在擴充中,將會包含415個序列,在41座建築中的254個空間中獲取。另外,某些地方將會在一天中的多個時段被重複拍攝。
SUNRGBD資料集[48](http://rgbd.cs.princeton.edu/)由四個RGB-D感測器得來,包含10000張RGB-D影象,尺寸與PASCAL VOC一致。該資料集包含了NYU depth v2 [46], Berkeley B3DO [61], 以及SUN3D [47]資料集中的影象,整個資料集均為密集標註,包括多邊形、帶方向的邊界框以及三維空間,適合於場景理解任務。
相關推薦應用於語義分割問題的深度學習技術綜述摘要 計算機視覺 語義分割深度學習方法集錦Papers Deep Joint Task Learning for Generic Object Extraction intro: NIPS 2014 homepage: http://vision.sysu.edu.cn/projects/deep-joint- [深度學習]圖片語義分割深度學習演算法要點回顧Review of Deep Learning Algorithms for Image Semantic Segmentation Arthur Ouaknine Dec 11 使用深度學習技術的影象語義分割最新綜述http://abumaster.com/2017/07/10/%E4%BD%BF%E7%94%A8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8A%80%E6%9C%AF%E7%9A%84%E5%9B%BE%E5%83%8F%E8%AF 達觀資料於敬:深度學習來一波,受限玻爾茲曼機原理及在推薦系統中的應用深度學習相關技術近年來在工程界可謂是風生水起,在自然語言處理、影象和視訊識別等領域得到極其廣泛的應用,並且在效果上更是碾壓傳統的機器學習。一方面相對傳統的機器學習,深度學習使用更多的資料可以進行更好的擴充套件,並且具有非常優異的自動提取抽象特徵的能力。 另外得益於GPU、SSD儲存、大 LED應用於非照明領域的技術趨勢LED光源具有高效、節能、環保、易維護等顯著特點,在全球能源短缺的背景下,LED照明產品是實現節能減排的有效途徑。近年來,隨著LED技術的不斷成熟,LED照明產品價格快速下降,已逐步取代白熾燈、熒光燈等其他照明光源,滲透率持續快速提升。 雖然LED照明逐漸成為照明領域的主流成品,但其市場 應用大資料和機器學習技術實現車險全流程智慧化的方案(中) -理賠流程智慧化改造一、簡要說明 本篇討論的是理賠環節用大資料和機器學習技術實現車險理賠流程的智慧化。理賠與承保不同,重點要放在風險控制方面(既包括外部風險控制,也包括內部風險控制),對於如何簡化理賠流程、提高理賠時效等提升客戶體驗等方面沒有必要採用承保減少人工干預的方法(PS:原因?自己想...)。 二、 應用大資料和機器學習技術實現車險全流程智慧化的方案(上)應用大資料和機器學習技術實現車險全流程智慧化的方案(上) -承保流程智慧化改造 一、簡要說明 以技術替代人力的思路對車險全業務流程改造,即應用車險大資料和機器學習技術全部或部分替代承保理賠管理相關業務處理崗位,實現車險業務處理流程、風險識別與控制的智慧化。本篇只討論 AI從業者需要應用的10種深度學習方法原文《the-10-deep-learning-methods-ai-practitioners QA問答系統中的深度學習技術實現應用場景 智慧問答機器人火得不行,開始研究深度學習在NLP領域的應用已經有一段時間,最近在用深度學習模型直接進行QA系統的問答匹配。主流的還是CNN和LSTM,在網上沒有找到特別合適的可用的程式碼,自己先寫了一個CNN的(theano),效果還行,跟論文中的結論是吻合的。目前已經應用到了我們的產品上。 面臨的深度學習技術問題以及基於TensorFlow的開發實踐一、用於Bot的深度學習技術及其面臨的難題 聊天機器人(chatbot),也被稱為會話代理或對話系統,現已成為了一個熱門話題。微軟在聊天機器人上押上了重注,Facebook(M)、蘋果(Siri)、谷歌、微信和 Slack 等公司也是如此。通過開發 Operator 或 【深度學習技術】卷積神經網路常用啟用函式總結本文記錄了神經網路中啟用函式的學習過程,歡迎學習交流。 神經網路中如果不加入啟用函式,其一定程度可以看成線性表達,最後的表達能力不好,如果加入一些非線性的啟用函式,整個網路中就引入了非線性部分,增加了網路的表達能力。目前比較流行的啟用函式主要分為以下7種: 10分鐘看懂全卷積神經網路( FCN ):語義分割深度模型先驅大家好,我是為人造的智慧操碎了心的智慧禪師。今天是10月24日,既是程式設計師節,也是程式設計師 機器學習大熱—— LINKZOL深度學習GPU工作站、伺服器主機配置深度學習技術 機器學習大熱—— LINKZOL深度學習GPU工作站、伺服器主機配置深度學習技術 深度學習是近幾年熱度非常高的的計算應用方向,其目的在於建立,模擬人腦進行分析學習的神經網路,它模仿人腦的機制來解析資料,依據其龐大的網路結構,引數等配合大資料,利用其學習能強等特點 AI改變金融風控,深度學習技術可以將壞賬降低35% | 乾貨昨天在風控群內,大家都在討論平安普惠COO的觀點,“在放貸領域,只有0和1的概念,要麼借要麼不借”,有人說,0和1的概念肯定不適用於貸款審批,信貸審批是多維評判的,沒有不能貸的客戶,只有不能貸的機制;也有人說,風險定價、風險補償機制就是用來在0和1之間進行調節的;而大家都 【深度學習技術】LRN 區域性響應歸一化LRN(Local Response Normalization) 區域性響應歸一化筆記 本筆記記錄學習 LRN(Local Response Normalization),若有錯誤,歡迎批評指正,學習交流。 1.側抑制(lateral inhibiti 『深度應用』NLP機器翻譯深度學習實戰課程·零(基礎概念)0.前言 深度學習用的有一年多了,最近開始NLP自然處理方面的研發。剛好趁著這個機會寫一系列NLP機器翻譯深度學習實戰課程。 本系列課程將從原理講解與資料處理深入到如何動手實踐與應用部署,將包括以下內容:(更新ing) NLP機器翻譯深度學習實戰課程·零(基礎概念) NLP機器翻譯深 用深度學習技術FCN自動生成口紅1 這個是什麼? 基於全卷積神經網路(FCN)的自動生成口紅Python程式。 圖1 FCN生成口紅的效果(注:此兩張人臉圖來自人臉公開資料庫LFW) 2 怎麼使用了? 基於深度學習的圖像語義分割技術概述之5.1度量標準-s 公平性 的確 由於 表示 n-2 sub 包含 提升 本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmentation:原文鏈接 5.1度量標準 為何需 基於深度學習的影象語義分割技術概述之4常用方法 5.4未來研究方向https://blog.csdn.net/u014593748/article/details/72794459 本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmen | ||||||