
王小草【深度學習】筆記第四彈--卷積神經網路與遷移學習
標籤(空格分隔): 王小草深度學習筆記
1. 影象識別與定位
影象的相關任務可以分成以下兩大類和四小類:
影象識別,影象識別+定位,物體檢測,影象分割。
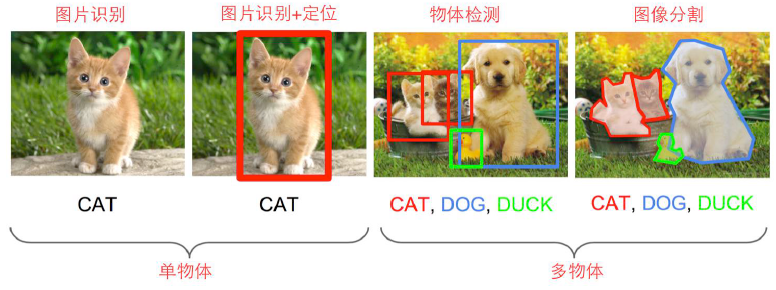
影象的定位就是指在這個圖片中不但識別出有只貓,還把貓在圖片中的位置給精確地摳出來今天我們來講一講如何神經網路來做影象識別與定位。
影象的識別:
可以看成是影象的分類》C個類別
輸入:整個圖片
輸出:類別標籤(每個類別會有一個概率,選出概率最大的標籤)
評估標準:準確率
圖形的定位:
輸入:整個影象
輸出:物體邊界框(x,y,w,h)。x,y是物體邊界框的左上定點的橫縱座標;w,h是這個圖片的長和高。通過這4個指標就可以定位出圖中的物體的位置。
評估標準:交併準則
所以影象的識別與定位就是以上兩個任務組成。
下面介紹2中思路去實現影象的識別與定位。
1.1 思路1:視作迴歸
對於影象定位來說只要求出了(x,y,w,h)這四個值就得到了定位,因為這四個值是連續性,所以不能用分類的方法來做,這裡考慮用迴歸來做。
與之前分類問題不同的是,現在我們使用L2loss也就是歐氏距離來求損失函式。
步驟1:
首先得搭一個影象識別的神經網路,可以在VGG,GoogleLenet這些優秀的模型上fine-tuning一下。
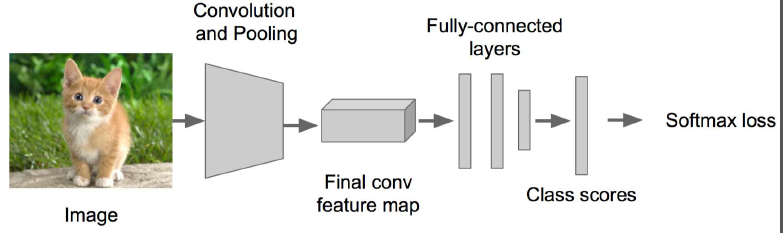
步驟2:
接下來在上述神經網路的尾部展開成兩個部分:成為classification + regression的模式。前者是為了識別,後者是為了定位。一般這個展開會放在卷積層後面,也有時候放在全連線層後面。
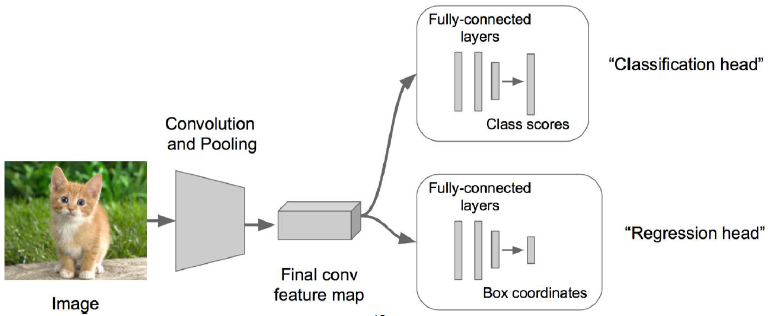
步驟3:
在regression迴歸部分使用歐氏距離計算損失,然後運用SGD來訓練,在classification部分和以前一樣不變。
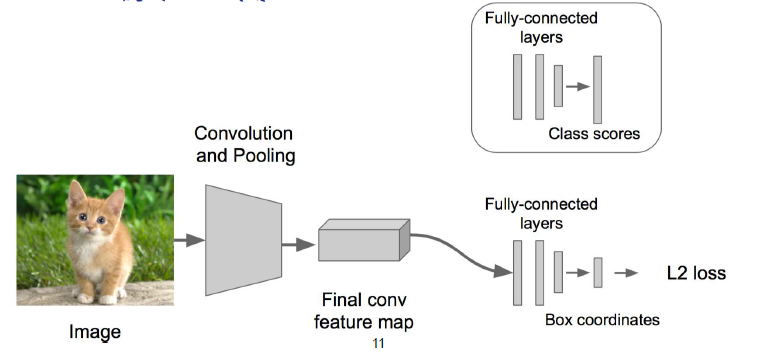
步驟4:
在預測階段,將classification和regression兩個模組拼上,讓他們各自去實現自己不同的功能。
regression模組加在什麼位置呢?
可以放在卷積層後,如VGG
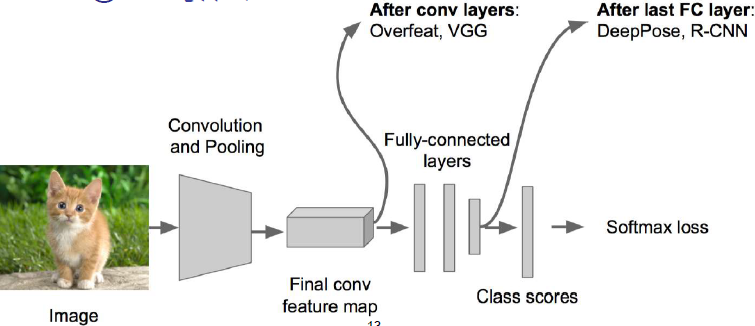
也可以放在全連線層後, 如DeepPose
能否對主體有更細緻的識別?
神經網路能夠對圖形進行定位,那麼能否識別出這個物體在幹啥子在做什麼動作呢?
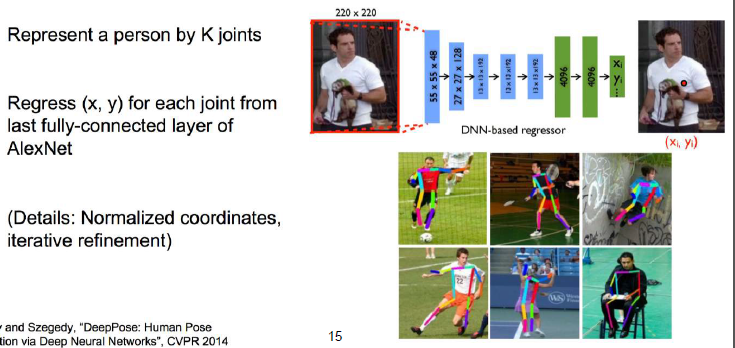
這也可以,需要提前把規定好K個組成部分,然後分別去做k個部分的迴歸就行了。
比如識別人的姿勢,每個人的組成部分是固定的,可以將人分成K個首尾相接的線段,然後對這些線段分別求迴歸。
1.2 思路2:藉助影象視窗
另一個思路是來自於2014年發表的一篇論文。它的邏輯是這樣的:取不同大小的“框”,讓框出現在不同位置,判定每個框在每個為上的得分,按照得分高低對結果寬工作抽取與合併。
如下圖,取一個3*221*221的一個框,讓它在影象的4個位置走一遍,然後得出每個位置的得分,右下角的框得分最高,識別出貓的概率為0.8.

這個方法存在最大的問題是:“引數多”,“計算慢”。因為要去嘗試不同大小的框並放在不同位置。但是論文中提到了解決這兩個缺陷的方案。
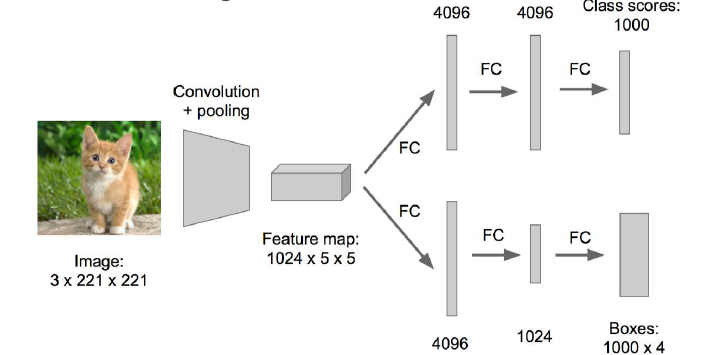
下圖是神經網路最初的形式,從卷積層出來或分成了兩個模組,每個模組中分別有及幾層的全連線。如果FC層中的神經元有4096個,那麼這個過程會產生4096*4096個引數。
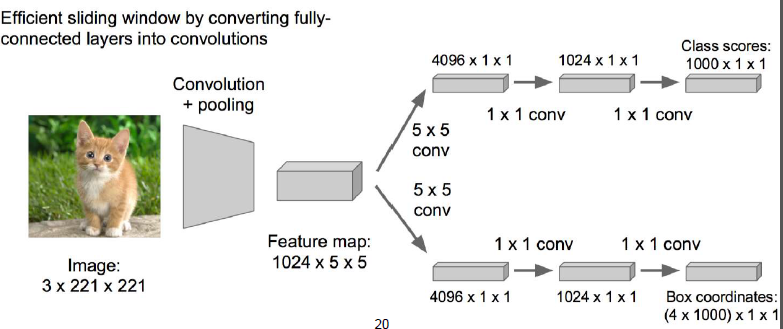
論文作者提出了這樣的方案,從卷積層出來後的兩個模組中,將FC層乘以一個1*1的conv卷積層,那麼引數的數量就下降到了4069*1了。
論文裡的東東拿出來講的要十分龐大,有興趣的童鞋直接看原文論,哈哈。

2. 物體識別
2.1 背景
在衣服圖中可能有多個物體,此時就需要去把每個物體都識別出來。比如下圖中有4個物體,兩個貓星人,一個汪星人,一個小鴨子。如果用迴歸,要去識別四個物體就需要預測4*4 = 16 個連續值了。

用迴歸來做物體識別需要先確定物體的個數K。但是通常情況下,我們並不知道影象中有多少個物體,就像下圖這樣。
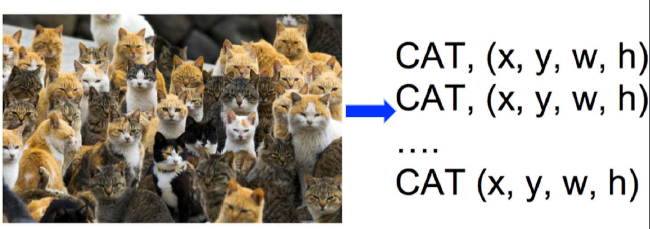
於是我們又回到了分類問題,讓不同大小的框去移動然後做分類,就像下圖這樣。

但是分類問題來做物體識別也有難處:
–你需要找很多位置,還需要設定很多不同大小的框
–還要對每個框在每個位置的影象做分類
–而且你選的框的大小也不一定對啊
–…..
2.2 邊緣策略
我們來換一個角度想問題,為什麼要用那麼多的框大海撈針呢,為什麼不在圖中先找到一個可能成框的東東作為候選框呢。
–也就是說,想辦法找到包含內容的圖框。
原理是這樣的,先找到一個畫素點,然後將它周圍與它相近的點也包羅進來形成了一個小的候選框,這些小的候選框再向周圍擴張,將顏色相似的點包含進來,如此一輪一輪候選框就會逐漸擴大了。具體過程如下圖:
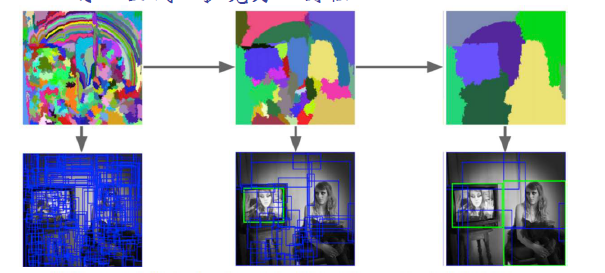
最後一張圖中其實已經非常清晰地識別出來牆上的相框和旁邊的美女了。
2.3 R-CNN
一個大牛在2014年發表了一篇物體識別的論文。
它的實驗大概是這樣做的:
首先對圖片使用邊緣策略進行物體識別,然後將每個候選框輸入卷積層產出特徵,接著一邊讓卷基層的輸出進入SVM做一個“有無物體”的分類,如果有的話就進行迴歸計算。迴歸計算是去調整候選框,使其能剛好摳出一個物體。
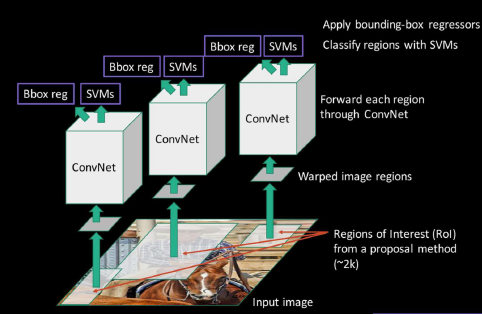
有興趣的童鞋還是可以去看原版論文:

3. Neural Style
人人都是梵高
有沒有這樣一個可能,傳入一張我的自畫像,再傳入一張大師的畫作,然後將我的自畫像變成大師畫作一樣的風格。2015年,德國的幾位同學,本來想研究研究有沒有新的更優秀的損失函式,不小心發現了用卷積神經網路提取影象風格的方法。這麼一來,我們是不是可以一方面提取出自己照片內的內容,一方面提取出大師畫作的風格,將兩者融合,就等於讓大師幫我畫了一張自畫像了。說得如果有點繞,來看看一箇中國的童鞋做的一個案例
這是這位童鞋與好基友在玩耍的照片

這是家喻戶曉的名畫“星空”

做了融合之後,這是星空風格的基友玩耍圖:

有木有醉醉的。類似的例子有多,比如:

再比如:

還比如:

也就是說,你可以把任何一張以自己的或是貓貓狗狗的或是風景的照片,變換成任何風格的大師作品。
總結一下,就是醬紫的:

原理介紹
看論文有點繞繞的,還是我來總結一下。
首先,明確我們有三張圖,一張圖是照片,一張圖是畫作,一張是融合了畫作風格和照片內容的新圖。既然這張新圖是來自於照片的內容,和畫作的風格,那麼這張新圖必然與照片在內容上的差距越小越好,與畫作在風格上的差距越小越好。這麼說,我們找到了目標,有了目標就可以建立目標函式,這裡是建立兩個損失函式,即:
loss_total = loss(照片內容-新圖內容)+ loss(畫作風格-新圖風格)。
這就是我們的目標函式。當目標函式最小的時候所生成的新圖就是我們要得到的結果!
那麼問題來了,如何提取照片的內容,和畫作的風格呢?
提取照片的內容:
首先,讓我們站上巨人的肩膀上,下載一個已經搭建好的並且非常棒的卷積神經網路模型,比如VGG,比如Alexnet.論文中用的是VGG, 我們這邊用Alexnet.
然後我們往這個模型中輸入一張照片(注意我們現在要提取內容,所以輸入的是照片)
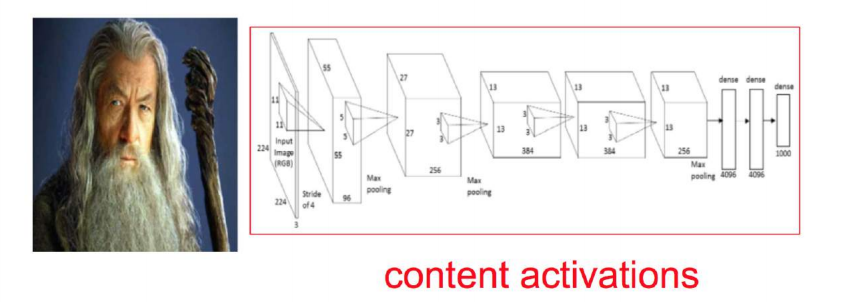
這張照片一層一層地經過卷基層,在第5層的時候輸出的是一個14*14*256的矩陣。256是第五層卷基層中神經元的個數,不同的模型不同,也可以自己調整,這邊只是舉個例子。14 * 14 是一個feature map,所以這裡總共有256個feature map.我們知道一個神經元會關注某一個特徵,所以一個feature map隱含著一類特徵資訊。而這一整個14 * 14 * 256的輸出我們稱之為content representation–內容表徵。也就是我們提取出來的“照片內容”。
這裡注意的是,我們直接使用了Alexnet,它已經訓練好了權重即其他所有引數,我們不需要去訓練得到,在這裡,我們直接使用這些引數,做一次前向計算,將圖片輸出成內容的表徵。
提取畫作的風格:
首先,我們仍然直接使用Alexnet這個模型。
然後向這個模型輸入一張畫作:

這張畫作經過層層卷基層進行前向計算,在某一層,比如第一層的輸出是224 * 224 * 64,同樣,64是這一層神經元的個數,可以自己調整的。於是可以看成是有64個224*224的二維矩陣。
接下來是重點。
我們將這64個平面兩兩做點乘,最後會得到64 * 64 的矩陣,這個矩陣,就是style representation–風格表徵。叫做gram matrix.
建立目標函式:
我們已經提取了照片的內容和畫作的風格,但是我們需要將它們分別與新圖做比較。於是,我們也需要將新圖分別輸入這兩個神經網路,並且提取出新圖的內容和新圖的風格。
那麼問題又來了,新圖是我們要最後生成的圖,我們一開始是沒有的,怎麼輸入?
是這樣滴,在一開始的時候我們會隨機定義一個新圖,這個隨機真的是隨便的,你可以把照片作為初始的新圖,也可以把畫作作為初始的新圖,也可以隨機產生任何一張新圖。
將這張初始的新圖輸入兩個模型中分別會得到一個內容表徵與一個風格表徵。
於是,我們就可以建立完整的損失函數了!:
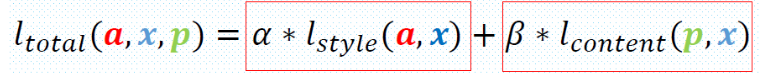
p是照片,a是畫作,x是新圖。
Lcontent是照片與新圖的內容上的差距,即對應位置相減的平方和,之所以乘以1/2是為了求導方便。
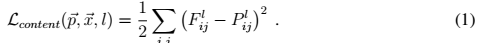
Lstyle是畫作與新圖在風格上的差距,也是差值的平方和,公式與上同
α和β分別是內容和風格兩個損失的權重。α+β=1.如果α比較大,那麼輸出後的新圖會更多地傾向於內容上的吻合,如果β較大,那麼輸出的新圖會更傾向於與風格的吻合。這兩個引數是一個trade-off,可以根據自己需求去調整最好的平衡。論文的作者給出了它調整引數的不同結果,如下圖,從左到右四列分別是α/β = 10^-5, 10^-4,10^-3, 10^-2.也就是α越來越大,的確影象也越來越清晰地呈現出了照片的內容。

現在損失函式已經確定了,在這個損失函式中,所有的模型的引數都是一開始就給定的,不需要去調整。在訓練過程中,需要調整與更新的是輸入的新圖x。最後輸出的是,是的損失函式最小的時候的新圖!這樣,本次大師模仿秀就完美結束了。