
Flink邊學邊記
阿新 • • 發佈:2018-12-13
都是自己從網上搜集的一些自己感興趣的東西
----------------------------------------------------------------------------------------------------------------------------------------
Flink是什麼?
- Apache Flink是一個面向分散式資料留處理和批量資料處理的開源計算平臺,提供支援流處理和批處理兩種型別應用的功能
-
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded
data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale. - Apache Flink是一個框架和分散式處理引擎,用於對無界和有界資料流進行有狀態計算。Flink設計為在所有常見的叢集環境中執行,以記憶體速度和任何規模執行計算。
- 什麼是有狀態的計算?
計算任務的結果不僅僅依賴於輸入,還依賴於它的當前狀態,其實大多數的計算都是 有狀態的計算。 比如wordcount,給一些word,其計算它的count,這是一個很常見的業務場景。count做 為輸出,在計算的過程中要不斷的把輸入累加到count上去,那麼count就是一個 state。
Flink是怎麼來的?
- 在2008 年,Flink 是柏林理工大學一個研究性專案。在 2014 被 Apache 孵化器所接受,然後迅速地成為了 ASF(Apache Software Foundation)的頂級專案之一。
相關的兩個框架
- spark於2009年誕生於加州大學伯克利分校AMPLab(AMP:Algorithms,Machines,People),它最初屬於伯克利大學的研究性專案,後來在2010年正式開源,並於 2013 年成為了 Apache 基金專案,到2014年便成為 Apache 基金的頂級專案。
- Twitter於2011年 對 Storm 開源。Storm的作者是Nathan Marz,Nathan Marz在BackType公司工作的時候有了Storm的點子並獨自一人實現了Storm。在2011年Twitter準備收購BackType之際,Nathan Marz為了提高Twitter對BackType的估值,在一篇部落格裡向外界介紹了Storm。Twitter對這項技術非常感興趣,因此在Twitter收購BackType的時候Storm發揮了重大作用。後來Nathan Marz開源Storm時,也藉著Twitter的品牌影響力而讓Storm名聲大震!
個人覺得Flink具備什麼特點呢?
- Flink兼備了spark的基於記憶體的快速計算,又實現了毫秒級的實時計算。並實現了很多更加方便快捷的東西,將對此進行學習。
開始學習
Flink生態圈是什麼?
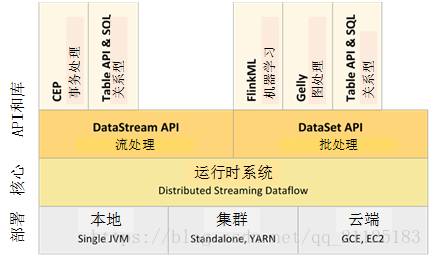
圖1 Flink的生態圈
- 從部署模式上講,Flink支援local模式、叢集模式(standalone叢集或者Yarn叢集)、Cloud端部署。
- Flink的核心是DistributedStreaming Dataflow引擎,它用來執行dataflow程式。Flink的核心執行引擎可以看作是Streaming Dataflow引擎,DataSetAPI和DataStreamAPI都可以通過該引擎建立執行時程式。
- Flink中有兩個核心API:用於處理有界資料集DataSet API(通常稱為批處理)和用於處理無界資料流的DataStream API(通常稱為實時流處理)。
- 在核心API的基礎上,Flink還綁定了用於特定於領域的庫和API,目前是用於機器學習的FlinkML, 用於圖處理的Gelly和用於sql的操作的Table API。從部署模式上講,Flink支援local模式、叢集模式(standalone叢集或者Yarn叢集)、Cloud端部署。
Flink的架構是什麼?

圖2 Flink的架構
matser-slaver
- JobManagers(master):用於協調分散式程式執行。它們用來排程task,協調檢查點,協調失敗時恢復等
- TaskManagers(worker):用於執行一個dataflow的task(或者特殊的subtask)、資料緩衝和data stream的交換。
Flink程式的核心概念是什麼?
flink程式三個基本構建塊
- source:資料來源
- transformations:基於資料流的一組operate操作
- sink:資料處理結果的目的地
並行資料流
- 在flink中,transformation是由一組operator組成,每一個operator被分割成operator subtask,同一個operator的多個 subtasks在不同的執行緒、不同的物理機或不同的容器中彼此互不依賴得並行執行。
- Stream在operator有兩種形式:One-to-one:類似於spark中的窄依賴;Redistributing:類似於spark中的寬依賴