
自編碼器深度分析+定製特徵描述子構建初探
1. 關於tailored 特徵描述子
自從深度學習的繁榮,利用自編碼器、孿生網路、對抗網路採用資料驅動的形式設計tailored 特徵描述子 成為了計算機視覺領域發展的重要推動力, 這不僅大大削弱了特徵工程的壓力,而且降低了相關領域學者對於數學基礎的要求。 本博文重點在於介紹自編碼器在tailored feature方面的潛力。
2. 什麼是自編碼器(Autoencoder)初步探索
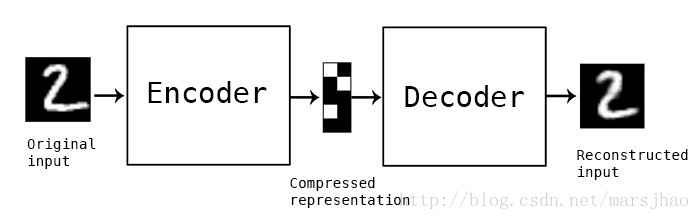
自動編碼器實質是Encode+Decode的過程,實際可以理解為是一種資料壓縮+資料重建演算法,其中資料的壓縮和解壓縮函式是資料相關的、有損的、從樣本中自動學習的。在大部分提到自動編碼器的場合,壓縮和解壓縮的函式是通過神經網路實現的。
- 自動編碼器是資料相關的(data-specific 或 data-dependent),這意味著自動編碼器只能壓縮那些與訓練資料類似的資料,這維學習某一領域的tailored feature提供了可能。比如,使用人臉訓練出來的自動編碼器在壓縮別的圖片,比如樹木時效能很差,因為它學習到的特徵是與人臉相關的
- 自動編碼器是有損的,意思是解壓縮的輸出與原來的輸入相比是退化的,這潛在有利於去除資料中不一致、非緊緻的噪聲
- 自動編碼器是從資料樣本中自動學習的,這意味著很容易對指定類的輸入訓練出一種特定的編碼器,而不需要完成任何新工作。
搭建一個自動編碼器需要完成下面三樣工作:搭建編碼器,搭建解碼器,設定一個損失函式,用以衡量由於壓縮而損失掉的資訊。編碼器和解碼器一般都是引數化的方程,並關於損失函式可導,典型情況是使用神經網路。編碼器和解碼器的引數可以通過最小化損失函式而優化,例如SGD。自編碼器是一個自監督的演算法,並不是一個無監督演算法。
目前自編碼器的應用主要有兩個方面,第一是資料去噪,第二是為進行視覺化而降維。配合適當的維度和稀疏約束,自編碼器可以學習到比PCA等技術更有意思的資料投影。對於2D的資料視覺化,t-SNE(讀作tee-snee)或許是目前最好的演算法,但通常還是需要原資料的維度相對低一些。所以,視覺化高維資料的一個好辦法是首先使用自編碼器將維度降低到較低的水平(如32維),然後再使用t-SNE將其投影在2D平面上。
3. 幾種典型自編碼器調研
自編碼是神經網路的一種,經過訓練後能嘗試將輸入複製到輸出。自編碼器內部有一個隱藏層 h,可以產生編碼(code)表示輸入。該網路可以看作由兩部分組成:一個由函式 h = f(x) 表示的編碼器和一個生成重構的解碼器 r = g(h)。如果一個自編碼器只是簡單地學會將處處設定為 g(f(x)) = x,那麼這個自編碼器就沒什麼特別的用處。相反,我們不應該將自編碼器設計成輸入到輸出完全相等。這通常需要向自編碼器強加一些約束,使它只能近似地複製,並只能複製與訓練資料相似的輸入。這些約束強制模型考慮輸入資料的哪些部分需要被優先複製,因此它往往能學習到資料的有用特性。
- 欠完備自編碼器
從自編碼器獲得有用特徵的一種方法是限制 h的維度比 x 小,這種編碼維度小於輸入維度的自編碼器稱為欠完備undercomplete自編碼器。學習欠完備的表示將強制自編碼器捕捉訓練資料中最顯著的特徵。學習過程可以簡單地描述為最小化一個損失函式L(x,g(f(x))),其中 L 是一個損失函式,懲罰g(f(x)) 與 x 的差異,如均方誤差。當解碼器是線性的且 L 是均方誤差,欠完備的自編碼器會學習出與 PCA 相同的生成子空間。這種情況下,自編碼器在訓練來執行復制任務的同時學到了訓據的主元子空間。如果編碼器和解碼器被賦予過大的容量,自編碼器會執行復制任務而捕捉不到任何有關資料分佈的有用資訊。
- 正則自編碼器
正則自編碼器使用的損失函式可以鼓勵模型學習其他特性(除了將輸入複製到輸出),而不必限制使用淺層的編碼器和解碼器以及小的編碼維數來限制模型的容量。這些特性包括稀疏表示、表示的小導數、以及對噪聲或輸入缺失的魯棒性。即使模型容量大到足以學習一個無意義的恆等函式,非線性且過完備的正則自編碼器仍然能夠從資料中學到一些關於資料分佈的有用資訊。
- 稀疏自編碼器
稀疏自編碼器簡單地在訓練時結合編碼層的稀疏懲罰 Ω(h) 和重構誤差:L(x,g(f(x))) + Ω(h),其中 g(h) 是解碼器的輸出,通常 h 是編碼器的輸出,即 h = f(x)。稀疏自編碼器一般用來學習特徵,以便用於像分類這樣的任務。稀疏正則化的自編碼器必須反映訓練資料集的獨特統計特徵,而不是簡單地充當恆等函式。以這種方式訓練,執行附帶稀疏懲罰的複製任務可以得到能學習有用特徵的模型。
- 去噪自編碼器
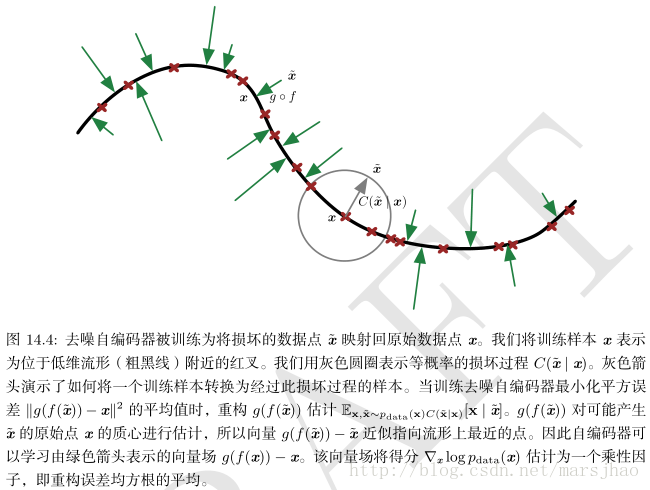
去噪自編碼器(denoisingautoencoder, DAE)最小化L(x,g(f(˜ x))),其中 ˜ x 是被某種噪聲損壞的 x 的副本。因此去噪自編碼器必須撤消這些損壞,而不是簡單地複製輸入。它是一類接受損壞資料作為輸入,並訓練來預測原始未被損壞資料作為輸出的自編碼器。DAE 的訓練準則(條件高斯p(x | h))能讓自編碼器學到能估計資料分佈得分的向量場 (g(f(x)) − x) ,這是 DAE 的一個重要特性。
4. 使用Keras建立簡單的自編碼器
利用全連線層構建簡單的自編碼器如下:

程式碼和效果和下圖所示:
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
encoding_dim = 32
input_img = Input(shape=(784,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=encoded)
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(inputs=encoded_input, outputs=decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()Dense784-Dense32-Dense784結果如下,其損失loss=0.1044:

Dense784-Dense256-Dense64-Dense256-Dense784結果如下,其損失loss=0.0879:


- 稀疏自編碼器、深層自編碼器
如果我們對隱層單元施加稀疏性約束的話,會得到更為緊湊的表達,只有一小部分神經元會被啟用。在Keras中,可以通過新增一個activity_regularizer達到對某層啟用值進行約束的目的。encoded = Dense( encoding_dim, activation='relu', activity_regularizer = regularizers.activity_l1(10e-5) )(input_img)。深度-稀疏自編碼器如下:
Note:在keras中存在3個正則化技巧,分別是權重正則化。偏置正則化、啟用正則化
from keras.layers import Input, Dense
from keras import regularizers
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
# only need images, this is self-supervised process
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255. # normalization
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(784,))
encoded = Dense(128,
activation='relu',
#activity_regularizer = regularizers.l1(0.000001)
)(input_img)
encoded = Dense(64,
activation='relu',
#activity_regularizer = regularizers.l1(0.00001)
)(encoded)
decoded_input = Dense(32,
activation='relu',
#activity_regularizer = regularizers.l1(0.00001)
)(encoded)
decoded = Dense(64, activation='relu')(decoded_input)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(decoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=decoded_input)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = autoencoder.predict(x_test)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 6))
for i in range(n):
# original images
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(encoded_imgs[i].reshape(8, 4))
#plt.gray()
plt.set_cmap('jet')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()Dense784-Dense128-Dense64-Dense32-Dense64-Dense128-Dense784 (無正則化)結果顯示,loss=0.1144:
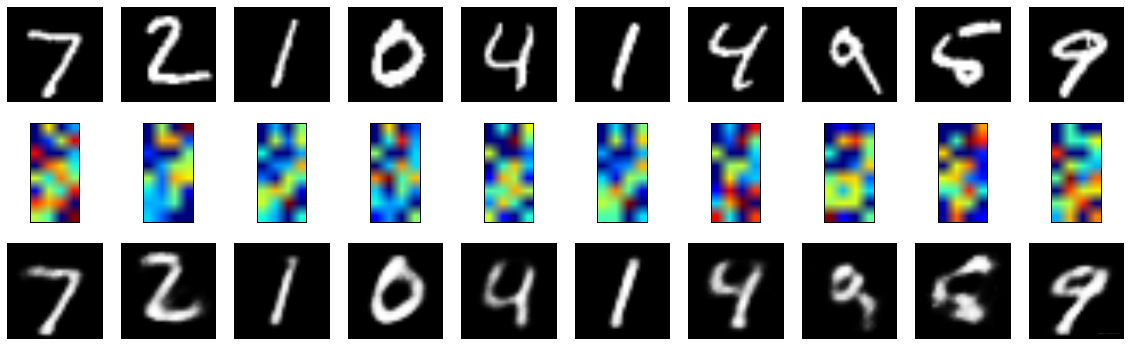
Dense784-Dense128-Dense64-Dense32-Dense64-Dense128-Dense784 (啟用正則化1e-6)結果顯示,loss=0.1396:

- 卷積自編碼器:用卷積層構建自編碼器
當輸入是影象時,使用卷積神經網路是更好的。卷積自編碼器的編碼器部分由卷積層和MaxPooling層構成,MaxPooling負責空域下采樣。而解碼器由卷積層和上取樣層構成。
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
from keras.callbacks import TensorBoard
import matplotlib.pyplot as plt
# only need images, this is self-supervised process
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255. # normalization
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), 28, 28, 1))
x_test = x_test.reshape((len(x_test), 28, 28, 1))
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
encoder = Model(inputs=input_img, outputs=encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
encoded_imgs = encoder.predict(x_test)
decoded_imgs = autoencoder.predict(x_test)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 6))
for i in range(n):
# original images
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(encoded_imgs[i].reshape(16, 8))
#plt.gray()
plt.set_cmap('jet')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()結果顯示:


- 使用自動編碼器進行影象去噪
我們把訓練樣本用噪聲汙染,然後使解碼器解碼出乾淨的照片,以獲得去噪自動編碼器。首先我們把原圖片加入高斯噪聲,然後把畫素值clip到0~1。
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
from keras.callbacks import TensorBoard
import matplotlib.pyplot as plt
# only need images, this is self-supervised process
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255. # normalization
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), 28, 28, 1))
x_test = x_test.reshape((len(x_test), 28, 28, 1))
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
encoder = Model(inputs=input_img, outputs=encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
encoded_imgs = encoder.predict(x_test)
decoded_imgs = autoencoder.predict(x_test)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 6))
for i in range(n):
# original images
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(encoded_imgs[i].reshape(16, 8))
#plt.gray()
plt.set_cmap('jet')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()去噪效果顯示,loss=0.1028:

博文參考: