
深度學習分散式訓練實戰(一)
本系列部落格主要介紹使用Pytorch和TF進行分散式訓練,本篇重點介紹相關理論,分析為什麼要進行分散式訓練。後續會從程式碼層面逐一介紹實際程式設計過程中如何實現分散式訓練。
常見的訓練方式
單機單卡(單GPU)
這種訓練方式一般就是在自己筆記本上,窮學生專屬。 : )
就是一臺機器,上面一塊GPU,最簡單的訓練方式。示例程式碼[2]:
#coding=utf-8
#單機單卡
#對於單機單卡,可以把引數和計算都定義再gpu上,不過如果引數模型比較大,視訊記憶體不足等情況,就得放在cpu上
import tensorflow as tf
with tf.device('/cpu:0'): 單機多卡(多GPU並行)
一臺機器上可以配置4塊GPU或者更多,如果我們在8塊GPU上都跑一次BP演算法計算出梯度,把所有GPU上計算出道梯度進行平均,然後更新引數。這樣的話,以前一次BP只能喂1個batch的資料,現在就是8個batch。理論上來說,速度提升了8倍(除去GPU通訊的時間等等)。這也是分散式訓練提升速度的基本原理。
以前不理解,為什麼這樣就會收斂快!這種做法,其實就是單位時間內讓模型多“過一些”資料。原因是這樣的,梯度下降過程中,每個batch的梯度經常是相反的,也就是前後兩次的更新方向相互抵消,導致優化過程中不斷震盪,如果我用多塊GPU,那麼每次不同GPU計算出來的梯度就會取平均互相抵消,避免了這種情況的出現。示意圖如下:
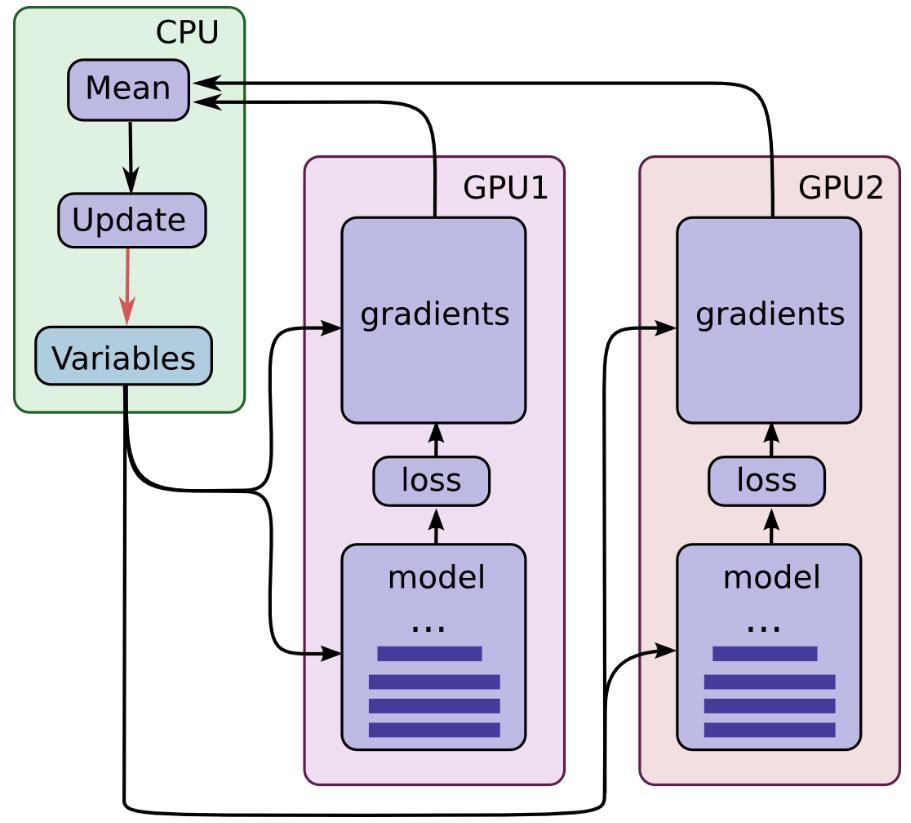
程式碼如下:
#coding=utf-8
#單機多卡:
#一般採用共享操作定義在cpu上,然後並行操作定義在各自的gpu上,比如對於深度學習來說,我們一把把引數定義、引數梯度更新統一放在cpu上
#各個gpu通過各自計算各自batch 資料的梯度值,然後統一傳到cpu上,由cpu計算求取平均值,cpu更新引數。
#具體的深度學習多卡訓練程式碼,請參考:https://github.com/tensorflow/models/blob/master/inception/inception/inception_train.py
import tensorflow as tf
with tf.device('/cpu:0'):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
with tf.device('/gpu:1'):
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
while 1:
print sess.run([addwb,mutwb])
多機多卡(分散式)
多機多卡就是使用多個機器,每個機器上有很多GPU來訓練。示意圖和單機多卡一致,程式碼在後續部落格講解。
為什麼要使用分散式訓練
所謂分散式訓練,就是使用很多臺機器,每臺機器上都有很多GPU,模型跑在這些不同電腦的不同GPU上以加快訓練速度(這個訓練速度表示收斂速度,但是使用分散式之後,收斂的值好不好,那就是另外一回事了)。
通常情況下,我們自己的筆記本是1塊GPU,如果是一些桌上型電腦,可以有4塊GPU。如果兩臺桌上型電腦,GPU數量則更多。GPU數量越多,模型訓練越快,具體原先下面分析。
- 資料規模大,導致訓練時間很長
在單機8卡情況下,對於MS COCO 115k 這個規模的資料集。訓練resnet152模型需要40個小時。訓練Open Image dataset v41,740k 資料集則需要40天[1]。
對於煉丹的同學們來說,需要不斷的嘗試引數,調模型,改結果,這種訓練速度是無法接受的。因此就很有必要使用分散式訓練了。 - 分散式可能帶來一些精度上的提升
先回憶一下,我們為什麼要用SGD來優化模型,隨機梯度下降的“隨機”是指每次從資料集裡面隨機抽取一個小的batch資料來進行計算誤差,然後反向傳播。我們之所以只選一個小的batch,一是因為通常來說這個小的batch梯度方向基本上可以代替整個資料集的梯度方向,二是因為GPU視訊記憶體有限。實際情況下,有的時候小的batch梯度並不足夠就代替整個資料集的梯度,也就是說,每次BP演算法求出來的梯度方向並不完全一致。這樣就會導致優化過程不斷震盪,而使用分散式訓練,即大一點的batch size,就可以很好的避免震盪。但最終精度的話,也只能說可能會更好!
Batch Size對訓練的影響
前面提到Batch size對模型精度會有一些影響,具體影響可以大致分析一下:
考慮極端情況,batch size = 1時,那麼模型每次更新的梯度有當前資料決定,那麼每次更新梯度方向不確定,模型很難收斂,但由於隨機性大,也沒那麼容易陷入區域性最優
如果batch size = total datasets呢,這個時候算出來的梯度就是整個資料集的梯度,如果學習速率合適(採用最速下降法),模型一次就收斂了。可能直接就掉到區域性最優了。
下面是知乎上一位同學做的實驗[1]:
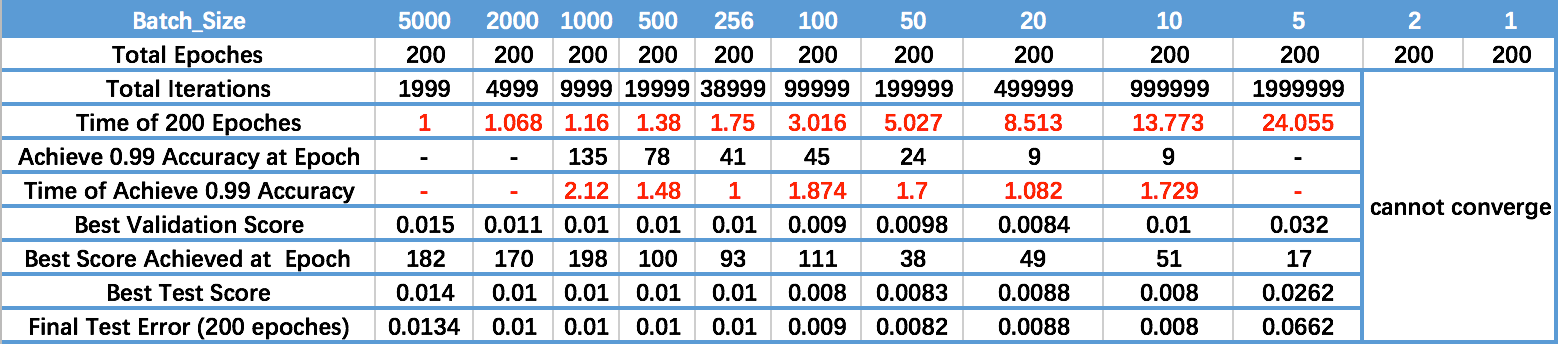
對錶格每一行分析,可以知道:
- 從Time of 200 Epoches可以看出,batch size越大,訓練到200個epoch的速度越快。即單位時間內,模型“看到的”資料越多
- 從Achieve 0.99 Accuracy at Epoch可以看出,batch size越大,實現同樣的精度,模型需要的時間越久。這一點可以理解為,batch size越大,模型收斂越慢嗎? 個人認為不可以,batch size越大,導致模型越容易陷入區域性最優,即模型收斂後的最終精度下降。所以才導致看起來,實現同樣精度,模型需要時間越久。
- 從Time of Achieve 0.99 Accuracy可以看出,batch size為256時,模型最快達到0.99精度。batch size過大,則導致模型精度上限下降,過小則不收斂。
- 從最後一行可以看出,小的batch size確實取得了較好的精度,但是訓練速度堪憂。
總結,batch size對訓練的影響:
- batch size 大點可以減少模型優化過程中的震盪問題
- 大的batch size可以提高矩陣乘法計算的並行度,提高記憶體利用率
- batch size過大,可能一定程度上導致模型收斂後的極限精度下降
- batch size過大,可能會有微小的精度損失
分散式訓練實現方式
資料並行
把資料進行拆分,比如有4塊GPU,batch size=1024,那麼每塊GPU就是256個數據。分別在每塊GPU都跑BP演算法,然後進行引數更新。
模型並行
把模型拆分成多個部分,對於很大的網路結構在如此,一般沒必要。
混合並行
兩者兼用,組內模型並行,組外資料並行[3]
多GPU訓練的引數更新方式
多GPU訓練情況下,包括單機多卡,多機多卡情況。其引數更新方式有兩種:
-
同步更新
每塊GPU分別執行反向傳播求出梯度,然後對梯度進行平均,更新引數。
缺點:每次引數更新,都要等待所有GPU梯度都計算完畢。此外,需要有一箇中心節點彙總梯度,並進行引數更新,這也會影響訓練速度。
-
非同步更新
每塊GPU各自進行反向傳播,計算出梯度,各自對模型進行更新(不進行梯度平均)
缺點:各個GPU梯度更新不同步,可能導致梯度已更新,然而某個GPU的梯度還是上一時刻的梯度,導致優化過程不穩定。
總之,各個GPU算力差不多時,推薦使用同步模式,否則使用非同步模式
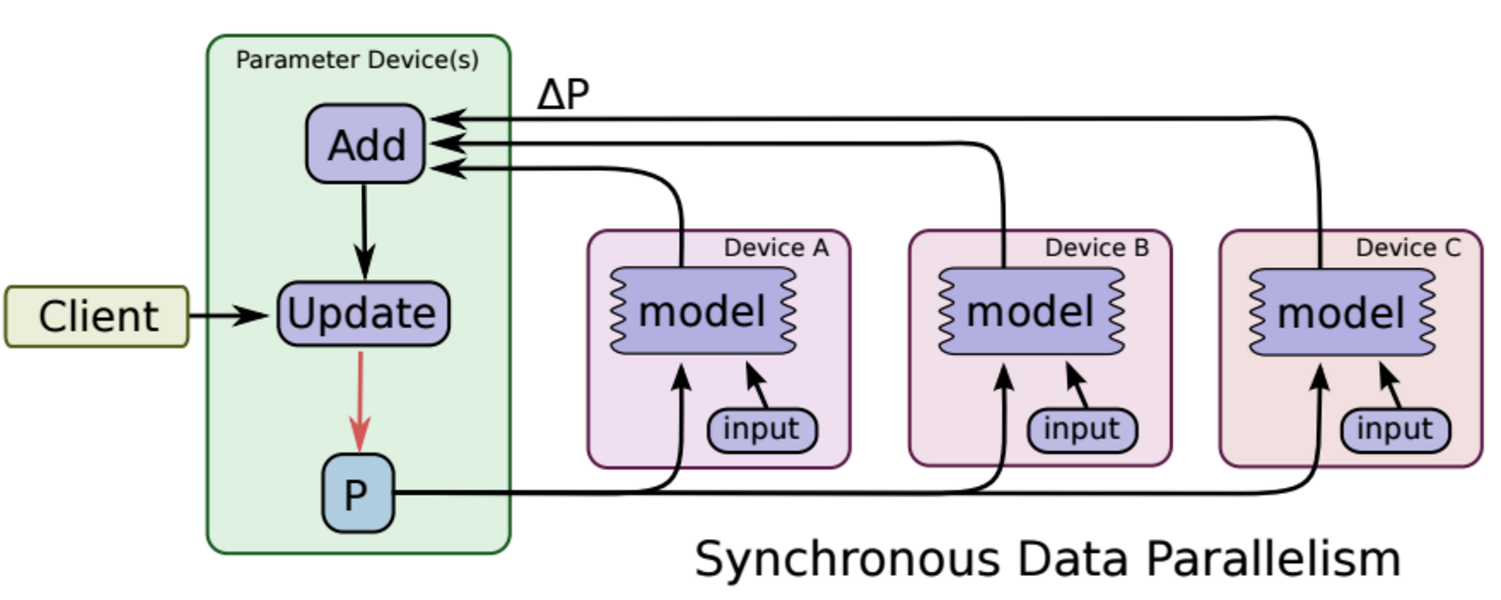
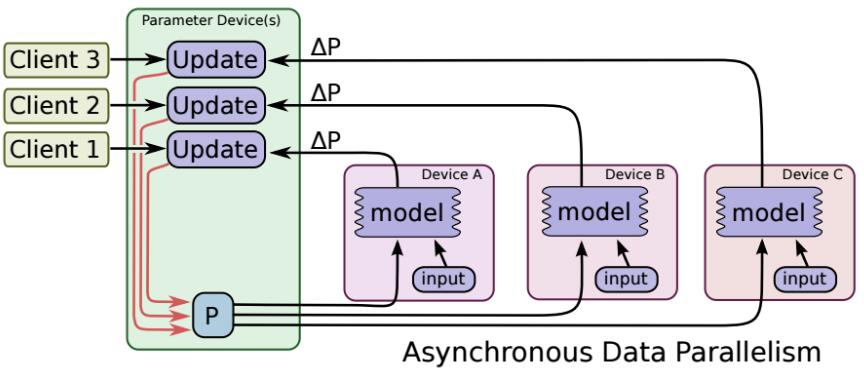
總結
- 分散式訓練有一點點精度損失
- 可以在前期改模型,調演算法過程採用分散式訓練,後期模型成熟了可以採用單GPU的小batch size訓練。(不過從mnist那一點點的精度差距來看,根本沒必要為了這一點點差距去做調參)