
Image Caption任務綜述
引言
Image Caption是一個融合計算機視覺、自然語言處理和機器學習的綜合問題,它類似於翻譯一副圖片為一段描述文字。該任務對於人類來說非常容易,但是對於機器卻非常具有挑戰性,它不僅需要利用模型去理解圖片的內容並且還需要用自然語言去表達它們之間的關係。除此之外,模型還需要能夠抓住影象的語義資訊,並且生成人類可讀的句子。
隨著機器翻譯和大資料的興起,出現了Image Caption的研究浪潮。當前大多數的Image Caption方法基於encoder-decoder模型。其中encoder一般為卷積神經網路,利用最後全連線層或者卷積層的特徵作作為影象的特徵,decoder一般為遞迴神經網路,主要用於影象描述的生成。由於普通RNN存在梯度下降的問題,RNN只能記憶之前有限的時間單元的內容,而LSTM是一種特殊的RNN架構,能夠解決梯度消失等問題,並且其具有長期記憶,所以一般在decoder階段採用LSTM.
問題描述
Image Caption問題可以定義為二元組(I,S)的形式, 其中I表示圖,S為目標單詞序列,其中S={S1,S2,…},其中St為來自於資料集提取的單詞。訓練的目標是使最大似然p(S|I)取得最大值,即使生成的語句和目標語句更加匹配,也可以表達為用盡可能準確的用語句去描述影象。
資料集
論文中常用資料集為Flickr8k,Flick30k,MSCOCO,其中各個資料集的圖片數量如下表所示。


資料集圖片和描述示例如圖
其中每張影象都至少有5張參考描述。為了使每張影象具有多種互相獨立的描述,資料集使用了不同的語法去描述同一張影象。如示例圖所示,相同影象的不同描述側重場景的不同方面或者使用不同的語法構成。
模型
本文主要介紹基於神經網路的方法
1 NIC[1]
Show and Tell: A Neural Image Caption Generator
本文提出了一種encoder-decoder框架,其中通過CNN提取影象特徵,然後經過LSTM生成目標語言,其目標函式為最大化目標描述的最大似然估計。
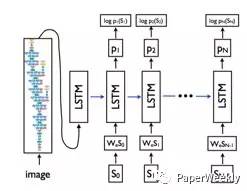
該模型主要包括encoder-decoder兩個部分。encoder部分為一個用於提取影象特徵的卷積神經網路,可以採用VGG16,VGG19, GoogleNet等模型, decoder為經典的LSTM遞迴神經網路,其中第一步的輸入為經過卷積神經網路提取的影象特徵,其後時刻輸入為每個單詞的詞向量表達。對於每個單詞首先通過one-hot向量進行表示,然後經過詞嵌入模型,變成與影象特徵相同的維度。
2 MS Captivator[2]
From captions to visual concepts and back
本文首先利用多例項學習,去訓練視覺檢測器來提取一副影象中所包含的單詞,然後學習一個統計模型用於生成描述。對於視覺檢測器部分,由於資料集對影象並沒有準確的邊框標註,並且一些形容詞、動詞也不能通過影象直接表達,所以本文采用Multiple Instance Learning(MIL)的弱監督方法,用於訓練檢測器。

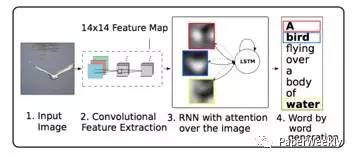
3 Hard-Attention Soft-Attention[3]
Show, atten and tell: Neural image caption generation with visual attention
受最近注意機制在機器翻譯中發展的啟發,作者提出了在影象的卷積特徵中結合空間注意機制的方法,然後將上下文資訊輸入到encoder-decoder框架中。在encoder階段,與之前直接通過全連線層提取特徵不同,作者使用較低層的卷積層作為影象特徵,其中卷積層保留了影象空間資訊,然後結合注意機制,能夠動態的選擇影象的空間特徵用於decoder階段。在decoder階段,輸入增加了影象上下文向量,該向量是當前時刻影象的顯著區域的特徵表達。
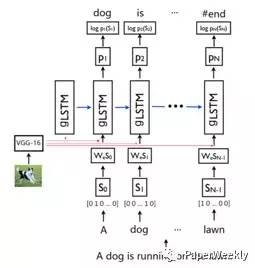
4 gLSTM[4]
Guiding long-short term memory for image caption generation
使用語義資訊來指導LSTM在各個時刻生成描述。由於經典的NIC[1]模型,只是在LSTM模型開始時候輸入影象,但是LSTM隨著時間的增長,會慢慢缺少影象特徵的指導,所以本文采取了三種不同的語義資訊,用於指導每個時刻單詞的生成,其中guidance分別為Retrieval-based guidance (ret-gLSTM), Semantic embedding guidance(emb-gLSTM) ,Image as guidance (img-gLSTM).

5 sentence-condition[5]
Image Caption Generation with Text-Conditional Semantic Attention
該模型首先利用卷積神經網路提取影象特徵,然後結合影象特徵和詞嵌入的文字特徵作為gLSTM的輸入。由於之前gLSTM的guidance都採用了時間不變的資訊,忽略了不同時刻guidance資訊的不同,而作者採用了text-conditional的方法,並且和影象特徵相結合,最終能夠根據影象的特定部分用於當前單詞的生成。
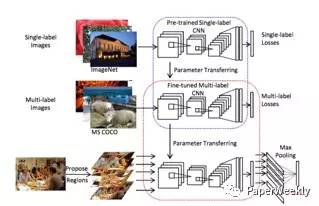
6 Att-CNN+LSTM [6]
What value do explicit high level concepts have in vision to language problems?
如圖,作者首先利用VggNet模型在ImageNet資料庫進行預訓練,然後進行多標籤數訓練。給一張圖片,首先產生多個候選區域,將多個候選區域輸入CNN產生多標籤預測結果,然後將結果經過max pooling作為影象的高層語義資訊,最後輸入到LSTM用於描述的生成。該方法相當於保留了影象的高層語義資訊,不僅在Image Caption上取得了不錯的結果,在VQA問題上,也取得很好的成績。
7 MSM[7]
BOOSTING IMAGE CAPTIONING WITH ATTRIBUTES
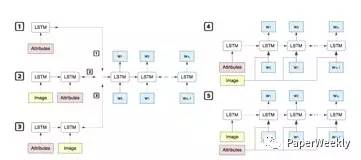
該文研究了影象屬性特徵對於描述結果的影響,其中影象屬性特徵通過多例項學習[2]的方法進行提取。作者採用了五種不同的組合形式進行對比。其中第3種、第5種,在五種中的表現出了比較好的效果。由於提取屬性的模型,之前用於描述影象的單詞的生成,所以屬性特徵能夠更加抓住影象的重要特徵。而該文中的第3種形式,相當於在NIC模型的基礎上,在之前加上了屬性作為LSTM的初始輸入,增強了模型對於影象屬性的理解。第5種,在每個時間節點將屬性和文字資訊進行結合作為輸入,使每一步單詞的生成都能夠利用影象屬性的資訊。
8 When to Look[8]
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
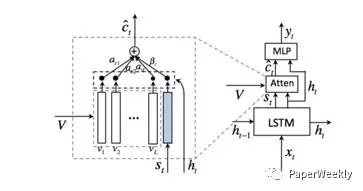
該文主要提出了何時利用何種特徵的概念。由於有些描述單詞可能並不直接和影象相關,而是可以從當前生成的描述中推測出來,所以當前單詞的生成可能依賴影象,也可能依賴於語言模型。基於以上思想,作者提出了“視覺哨兵”的概念,能夠以自適應的方法決定當前生成單詞,是利用影象特徵還是文字特徵。
結果
本文列出的模型的在COCO測試集上的結果如下:
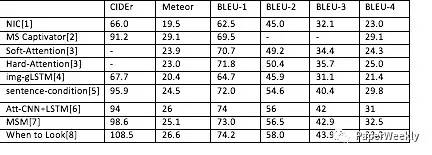
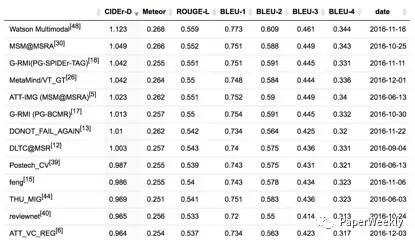
以下為online MSCOCO testing server的結果:
總結
最近的Image Caption的方法,大多基於encoder-decoder框架,而且隨著flickr30,mscoco等大型資料集的出現,為基於深度學習的方法提供了資料的支撐,並且為論文實驗結果的比較提供了統一的標準。模型利用之前在機器翻譯等任務中流行的Attention方法,來加強對影象有效區域的利用,使在decoder階段,能夠更有效地利用影象特定區域的特徵[3]。模型利用影象的語義資訊在decoder階段指導單詞序列的生成,避免了之前只在decoder開始階段利用影象資訊,從而導致了影象資訊隨著時間的增長逐漸丟失的問題[4][5]。模型為了更好的得到影象的高層語義資訊,對原有的卷積神經網路進行改進,包括利用多分類和多例項學習的方法,更好的提取影象的高層語義資訊,加強encoder階段影象特徵的提取[6][7]。隨著增強學習,GAN等模型已經在文字生成等任務中取得了不錯的效果,相信也能為Image Caption效果帶來提升。
參考文獻
1. Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[J]. Computer Science, 2015:3156-3164.
2.Fang H, Gupta S, Iandola F, et al. From captions to visual concepts and back[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2015:1473-1482.
3.Xu K, Ba J, Kiros R, et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention[J]. Computer Science, 2016:2048-2057.
4.Jia X, Gavves E, Fernando B, et al. Guiding Long-Short Term Memory for Image Caption Generation[J]. 2015.
5.Zhou L, Xu C, Koch P, et al. Image Caption Generation with Text-Conditional Semantic Attention[J]. 2016.
6.Wu Q, Shen C, Liu L, et al. What Value Do Explicit High Level Concepts Have in Vision to Language Problems?[J]. Computer Science, 2016.
7.Yao T, Pan Y, Li Y, et al. Boosting Image Captioning with Attributes[J]. 2016.
8.Lu J, Xiong C, Parikh D, et al. Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning[J]. 2016.
作者
朱欣鑫,北京郵電大學在讀博士,研究方向為視覺語義理解