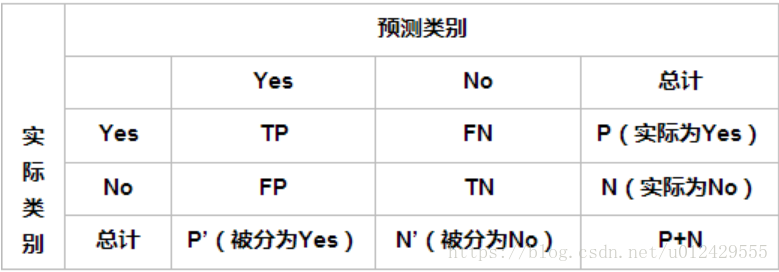
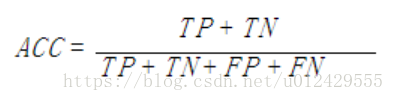準確率與召回率 阿新 • • 發佈:2018-12-14 1、兩個最常見的衡量指標是“準確率(precision)”(你給出的結果有多少是正確的)和“召回率(recall)”(正確的結果有多少被你給出了) 這兩個通常是此消彼長的(trade off),很難兼得。很多時候用引數來控制,通過修改引數則能得出一個準確率和召回率的曲線(ROC),這條曲線與x和y軸圍成的面積就是AUC(ROC Area)。AUC可以綜合衡量一個預測模型的好壞,這一個指標綜合了precision和recall兩個指標。 2、混淆矩陣 True Positive(真正,TP):將正類預測為正類數 True Negative(真負,TN):將負類預測為負類數 False Positive(假正,FP):將負類預測為正類數誤報 (Type I error) False Negative(假負,FN):將正類預測為負類數→漏報 (Type II error) 3、 準確率(Accuracy) 準確率(accuracy)計算公式為: 準確率是我們最常見的評價指標,而且很容易理解,就是被分對的樣本數除以所有的樣本數,通常來說,正確率越高,分類器越好。 準確率確實是一個很好很直觀的評價指標,但是有時候準確率高並不能代表一個演算法就好。比如某個地區某天地震的預測,假設我們有一堆的特徵作為地震分類的屬性,類別只有兩個:0:不發生地震、1:發生地震。一個不加思考的分類器,對每一個測試用例都將類別劃分為0,那那麼它就可能達到99%的準確率,但真的地震來臨時,這個分類器毫無察覺,這個分類帶來的損失是巨大的。為什麼99%的準確率的分類器卻不是我們想要的,因為這裡資料分佈不均衡,類別1的資料太少,完全錯分類別1依然可以達到很高的準確率卻忽視了我們關注的東西。再舉個例子說明下。在正負樣本不平衡的情況下,準確率這個評價指標有很大的缺陷。比如在網際網路廣告裡面,點選的數量是很少的,一般只有千分之幾,如果用acc,即使全部預測成負類(不點選)acc也有 99% 以上,沒有意義。因此,單純靠準確率來評價一個演算法模型是遠遠不夠科學全面的。 4、召回率是覆蓋面的度量,度量有多個正例被分為正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率與靈敏度是一樣的。衡量了分類器對正例的識別能力