
Paper Summary: Record Linkage
很久之前的記錄了,現在發出來,並會繼續新增以便查閱~ --2018.11.07
一、Ranking Scientific Articles by Exploiting Citations, Authors, Journals, and Time Information(2013年@AI)
1、論文目的
(1)如何綜合各種因素在異構網路上對論文進行排名?
(2)如何利用時間這個特性,因為引用量每天都是變化的,變化的引用量構成了一個動態的網路關係,一個近期才發表的論文,雖然當前的引用量不是很高,但是我們不能只根據引用量計算論文的排名,應該適當提升它的分數。
2、論文主要思想
(1) 構造了3個子網路,包括引用關係網路、論文和作者關係、論文和傳媒關係
(2) 使用了pagerank和HITS相結合的思想。
(3) 比較充分的考慮了時間的因素。使用了一些關於時間的策略。
3、論文可參考點
對時間特徵函式的設定。
二、A Unified Probabilistic Framework for Name Disambiguation in Digital Library(2012年@TKDE)
本篇論文是清華大學唐傑老師的一篇文章,其演算法也是應用在學術網站Aminer上姓名消歧的文章。網站網址:http://www.aminer.cn/
1、論文目的
對搜尋某一姓名下的所有文章分類,使真實的同名作者對應其不同的論文。
2、論文主要思想
(1)把論文當做節點,綜合考慮節點的相似度以及節點之間的關係,將其Formalize成一個隱馬爾科夫隨機場,其中論文是可觀測變數,論文所屬類別(屬於哪一個人)是隱變數。基於此模型,提出一種類似KMeans的演算法(與Kmeans的不同在於在將某論文分配給某類別時的演算法不同,KMeans最大似然平方和,而本篇論文是自定義的節點相似度以及節點間相互關係)
(2)將似然函式中出現的配分函式不可計算的NP-hard問題轉化為One-Step Sampling問題(這個主要引用了Hinton在2002年的文章:Hinton G E. Training products of experts by minimizing contrastive divergence.[M]. MIT Press, 2002.)。
(3)提出auto K的演算法,K是指具體要把某個姓名下的所有論文分成幾個人,這個演算法思想與Xmeans比較類似,都是利用了BIC準則。
3、論文可參考點
(1)Xmeans的auto K思想
(2)定義的relationship型別可參考
三、Ranking-Based Name Matching for Author Disambiguation in Bibliographic Data(2013年@KDD)
1、論文目的
Author-name disambiguation的兩個主要問題,一個是不同的作者有相同的姓名,同一個作者有不同的姓名。本文主要就是解決Author-name disambiguation的問題。
2、論文主要思想
通過一系列pattern確定兩個作者是不是同一作者。本文主要使用的是元路徑,基於元路徑來確定兩個實體的相似度。元路徑的pattern需要自己制定,可以轉化為矩陣運算的問題,最後基於不同pattern的元路徑相似度加權求和進行最終的決策。
3、其他
本文仍然是基於傳統的方法,類似於特徵工程,裡面除了包含大量的特徵工程外,將元路徑引入其中,可以將路徑中的隱藏關係以及路徑中跨度較大的關係加入進去。
四、CoLink: An Unsupervised Framework for User Identity Linkage(2018年@AAAI)
1、論文目的
對於兩個資料來源中的使用者,進行使用者連結。
2、論文背景
(1)有監督方法代價較高,所以本文使用的是無監督的方法。
(2)傳統的基於相似度的方法在很多場合下不適用,如:在一個數據源的職位是簡寫,另一個數據源使用的是全稱,對於這樣的問題使用傳統方法比較相似度為0。
(3)針對的是one-to-one的問題,即認為資料來源內容所有使用者唯一。
3、論文主要思想
考慮attribute-based model和relationship-based model。
(1)對於relationship-based model使用的比較簡單,主要是根據好友中匹配的個數進行連線.
(2)本文主要是attribute-based model,attribute-based model使用了seq3sel model,也就是機器翻譯中資料對齊的思想,這樣可以解決上面提到的字元沒有重複,但是可以根據語義特徵等計算準確性從而更好地進行使用者連結。除此之外,seq2seq model在訓練的時候只需要使用少量正例,不需要使用負例。
(3)二分類問題。
4、論文主要創新點
(1)co-training演算法,即首先根據attribute-model產生匹配資料,再根據relationship-model產生匹配資料,接著去掉衝突資料,並不斷迭代,直到收斂或者達到閾值要求。
(2)第一次將機器翻譯中的Seq2seq-model用於實體連線問題,和機器翻譯不同的是,在最後沒有輸出序列, 因為解決的是二分類問題,所以直接獲取的是和不同target匹配的概率值,並基於此概率值使用合適的閾值確定分類結果。
5、其他
(1)在初步篩選之後,隨機匹配的F1值達到51.64,應該可以說明資料集本身的質量就比較高,這種方法換到其他問題不一定會有這麼好的效果。
(2)co-training和seq2seq都是套用已有的模型,並作出相應的更改,但是對於實體連線領域來說,算是比較前沿的解決方法。
五、ELM-based name disambiguation in bibliography(2015年@WWW)
1、論文目的
論文中的姓名消歧問題。
2、論文主要思想
提出兩個策略:①一個分類器訓練一個name(OCEN)。②一個分類器訓練所有name(OCAN)。使用ELM(極限學習機)技術。
(1)OCEN
構造了三個特徵:author name, titles and book titles。
這三個特徵的構造都是基於word,比如對於title,把title中的所有詞當做特徵。
因為特徵維度較大,所以使用了PCA進行降維。
(2)OCAN
提出了basic和enhanced特徵提取,在basic的特徵提取中,只是簡單的基於三個屬性進行了提取;在enhanced特徵提取中,加入了relationship特徵。
3、其他
使用ELM,演算法暫時沒有深入瞭解,演算法相比於單隱層神經網路,在保證學習精度的前提下比傳統的學習演算法速度更快。
六、Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop(2018年@KDD)
1、論文目的
Aminer系統中論文的作者消歧。
2、論文主要思想
考慮global model和local model。
(1)對於global model,藉助負取樣的思想,將
三個元素一起訓練,使得目標loss最小,從而得到global embedding function。
(2)對於local model,主要是藉助Encoder-Decoder的思想,輸入是兩篇論文的相似關係(輸入圖的構建藉助了特徵的相似度,超過設定閾值則說明兩篇文章有邊連線),目標是優化重構圖的鄰接矩陣的最小誤差。
(3)Cluster size的估計使用了RNN,輸入文章,預測這些文章屬於的作者數。
3、論文主要創新點
(1)把各種前沿技術運用其中。
(2)應用在成熟的系統中,實用性強。
七、Ethnicity sensitive author disambiguation using semi-supervised learning ( 2016年@KESW )
1、論文目的
數字圖書館中作者的姓名消歧,包括同一個姓名錶示不同的人,或者不同姓名指的是同一個人。
2、論文主要思想
論文主要分3階段:
(1)Blocking
第一階段就是常規的分塊階段,主要將比較相似的人分到同一個block中,不相似的人分到不同的block中。
(2)Linkage function
第二階段是根據構造的特徵和分類器,學習linkage function,linkage function就是距離函式,這裡學習其引數。
這一階段中涉及訓練集的構造。訓練集最簡單的構造方法是同一訓練集中pairwise,label為1;不同訓練集的資料pairwise,label為0。但是這樣構造訓練集比較Coarse-grained,因此採用的方法是:對於同一個block中,若A和B是一個實體,則label為1,否則label為0。
(3)Clustering
使用的是層次聚類,使用的距離計算方法就是(2)中學習到的linkage function。對於最後層次聚類結果的擷取,本文使用了3種方法生成:
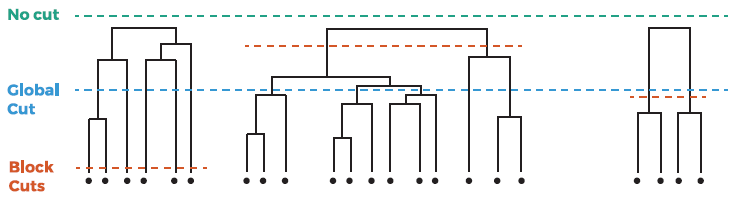
其中,
No cut表示的是不經擷取的層次聚類的結果。
Global Cut表示的是設定全域性閾值,即無論對於哪個cluster,都是用同一個閾值就行擷取。
Block Cut指標對每一個cluster,有一個擷取的閾值。
3、論文主要創新點
(1)在linkage function步驟中,考慮了不同地區的名稱以及種族習慣差異。
(2)在最後的cluster中,除了傳統了層次聚類,提出了基於Global和Block的擷取方案。
4、個人看法
(1)思路較傳統,但是有一些創新細節,比如考慮種族差異的特徵等。
(2)實驗結果太優秀。