
GoogLeNetv2 論文研讀筆記
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
摘要
當前神經網路層之前的神經網路層的引數變化,引起神經網路每一層輸入資料的分佈產生了變化,這使得訓練一個深度神經網路變得複雜。這樣就要求使用更小的學習率,引數初始化也需要更為謹慎的設定。並且由於非線性飽和(注:如sigmoid啟用函式的非線性飽和問題),訓練一個深度神經網路會非常困難。我們稱這個現象為:internal covariate shift。同時利用歸一化層輸入解決這個問題。我們將歸一化層輸入作為神經網路的結構,並且對每一個小批量訓練資料執行這一操作。Batch Normalization(BN) 能使用更高的學習率,並且不需要過多地注重引數初始化問題。BN 的過程與正則化相似,在某些情況下可以去除Dropout
引言
隨即梯度下降法(SGD)通過最小化 \(\theta\) 來最小化損失函式
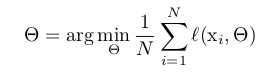
其中X1…N為訓練資料集。在使用SGD時,每次迭代我們使用一個大小為m 的小批量資料X1…m 。通過計算
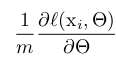
來逼近損失函式關於權值的梯度。在迭代過程中使用小批量資料相比使用一個樣本有幾個好處。首先,由小批量資料計算而來的損失函式梯度是由整個訓練資料集的損失函式梯度的估計。並且隨著小批量資料大小的增加,其效能會越好。其次,由於現代計算平臺的並行性,小批量訓練會比單個樣例訓練更高效
儘管隨機梯度下降法簡單有效,但卻需要謹慎的調整模型的引數,特別是在優化過程中加入學習率和引數初始化方式的選擇。每一層的輸入都會受之前所有層的引數影響,並且隨著網路越深,即使引數的變化很小也為對每一層的輸入產生很大的影響。這使得訓練一個網路變得十分複雜。神經網路層輸入分佈的改變,使得神經網路層必須不停的適應新的資料分佈。當一個學習系統的輸入資料分佈產生變化,稱這種現象為:Experience Covariate Shift。解決這種現象的典型方法是領域適應。輸入資料分佈相同這一特性,使得子網路更容易訓練。因此保持輸入的分佈不變是有利的。保持一個子網路的輸入資料分佈不變,對該子網路以外的隱藏層也有積極的作用
稱在訓練深度神經網路的過程中,網路內部節點的分佈發生變換這一現象為 Internal Covariate Shift。而消除這個現象能夠加速網路的訓練。因此提出了Batch Normalization ,通過減少依賴引數縮放和初始化,進而緩解Internal Covariate Shift,並動態的加速深度神經網路的訓練速度。BN 允許使用更高的學習率,而不會有發散的風險。進一步的,BN能夠正則化模型,並且不需要Dropout。最後,BN能夠使用s型啟用函式,同時不會陷入飽和端
降低內協變數漂移(Internal Covariate Shift)
將 Internal Covariate Shift 定義為:在神經網路的訓練過程中,由於引數改變,而引起的神經網路啟用值分佈的改變。通過緩解 Internal Covariate Shift 來提高訓練。在訓練的過程中保持神經網路層輸入的分佈不變,來提高訓練速度。已知,如果對網路的輸入進行白化(輸入線性變換為具有零均值和單位方差,並去相關),網路訓練將會收斂的更快。通過白化每一層的輸入,採取措施實現輸入的固定分佈,消除內部協變數轉移的不良影響
考慮在每個訓練步驟或在某些間隔來白化啟用值,通過直接修改網路或根據網路啟用值來更改優化方法的引數。然而,如果這些修改分散在優化步驟中,那麼梯度下降步驟可能會試圖以要求標準化進行更新的方式來更新引數,這會降低梯度下降步驟的影響
我們希望確保對於任何引數值,網路總是產生具有所需分佈的啟用值。這樣做將允許關於模型引數損失的梯度來解釋標準化,以及它對模型引數\(\Theta\)的依賴。希望通過對相對於整個訓練資料統計資訊的單個訓練樣本的啟用值進行歸一化來保留網路中的資訊
通過Mini-Batch統計進行標準化
由於每一層輸入的整個白化是代價昂貴的並且不是到處可微分的,因此做了兩個必要的簡化。首先是單獨標準化每個標量特徵,從而代替在層輸入輸出對特徵進行共同白化,使其具有零均值和單位方差。對於多為輸入的層,將標準化每一維。簡單標準化層的每一個輸入可能會改變層可以表示什麼。例如,標準化sigmoid的輸入會將它們約束到非線性的線性狀態。為了解決這個問題,要確保插入到網路中的變換可以表示恆等變換。為了實現這個,對於每一個啟用值x(k),引入成對的引數\(\gamma^{(k)}, \beta^{(k)}\),它們會歸一化和移動標準值
\[ y^{k} = \gamma^{k} \hat a^{k} + \beta(k) \]
這些引數與原始的模型引數一起學習,並恢復網路的表示能力
每個訓練步驟的批處理設定是基於整個訓練集的,將使用整個訓練集來標準化啟用值。然而,當使用隨機優化時,這是不切實際的。因此,做了第二個簡化:由於在隨機梯度訓練中使用小批量,每個小批量產生每次啟用平均值和方差的估計。這樣,用於標準化的統計資訊可以完全參與梯度反向傳播。通過計算每一維的方差而不是聯合協方差,可以實現小批量的使用;在聯合情況下,將需要正則化,因為小批量大小可能小於白化的啟用值的數量,從而導致單個協方差矩陣
批標準化步驟

BN變換可以新增到網路上來操縱任何啟用。在公式\(y=BN_{\gamma,\beta}(x)\)中,引數\(\gamma\)和\(\beta\)需要進行學習,但應該注意到在每一個訓練樣本中BN變換不單獨處理啟用。相反,\(BN_{\gamma,\beta}(x)\)取決於訓練樣本和小批量資料中的其它樣本。所有的這些子網路輸入都有固定的均值和方差,儘管這些標準化的\(\hat {x} ^{(k)}\)的聯合分佈可能在訓練過程中改變,但預計標準化輸入的引入會加速子網路的訓練,從而加速整個網路的訓練
BN變換是將標準化啟用引入到網路中的可微變換。這確保了在模型訓練時,層可以繼續學習輸入分佈,表現出更少的內部協變數轉移,從而加快訓練。此外,應用於這些標準化的啟用上的學習到的仿射變換允許BN變換表示恆等變換並保留網路的能力
批量標準化網路的訓練與推理
為了批標準化一個網路,根據上面的演算法,指定一個啟用的子集,然後在每一個啟用中插入BN變換。任何以前接收x作為輸入的層現在接收BN(x)作為輸入。採用批標準化的模型可以使用批梯度下降,或者用小批量資料大小為m>1的隨機梯度下降,或使用它的任何變種例如Adagrad進行訓練。依賴小批量資料的啟用值的標準化可以有效地訓練,但在推斷過程中是不必要的也是不需要的;希望輸出只確定性地取決於輸入。為此,一旦網路訓練完成,將使用總體統計來進行標準化,而不是小批量資料統計
\[ \hat x = \frac {x - E[x]}{\sqrt {Var[x] + \epsilon}} \]
此時,如果忽略\(\epsilon\),這些標準化的啟用具有相同的均值0和方差1,使用無偏方差估計\(Var[x] = \frac{m}{m-1} E_{\beta} [\sigma^2_{\beta}]\),其中期望是在大小為m的小批量訓練資料上得到的,\(\sigma^2_{\beta}\)是其樣本方差。使用這些值移動平均,在訓練過程中可以跟蹤模型的準確性。由於均值和方差在推斷時是固定的,因此標準化是應用到每一個啟用上的簡單線性變換。它可以進一步由縮放\(\gamma\)和轉移\(\beta\)組成,以產生代替BN(x)的單線性變換
訓練批標準化網路的過程

批標準化卷積網路
批標準化可以應用於網路的任何啟用集合。這裡專注於仿射變換和元素級非線性組成的變換
\[ z = g(Wu + b) \]
其中W和b是模型學習的引數,g(⋅)是非線性例如sigmoid或ReLU。這個公式涵蓋了全連線層和卷積層。在非線性之前通過標準化x=Wu+b加入BN變換。也可以標準化層輸入u,但由於u可能是另一個非線性的輸出,它的分佈形狀可能在訓練過程中改變,並且限制其第一矩或第二矩不能去除協變數轉移。相比之下,Wu+b更可能具有對稱,非稀疏分佈,即“更高斯”,對其標準化可能產生具有穩定分佈的啟用
由於對Wu+b進行標準化,偏置b可以忽略,因為它的效應將會被後面的中心化取消(偏置的作用會歸入到演算法1的β)。因此,z=g(Wu+b)被\(z=g(BN(Wu))\)替代,其中BN變換獨立地應用到x=Wu的每一維,每一維具有單獨的成對學習引數\(\gamma^{(k)},\beta^{(k)}\)
另外,對於卷積層,希望標準化遵循卷積特性——為的是同一特徵對映的不同元素,在不同的位置,以相同的方式進行標準化。為了實現這個,在所有位置聯合標準化了小批量資料中的所有啟用。在第一個演算法中,讓\(B\)是跨越小批量資料的所有元素和空間位置的特徵圖中所有值的集合——因此對於大小為m的小批量資料和大小為p×q的特徵對映,使用有效的大小為m' = \(|B|\) = m ⋅ pq 的小批量資料。每個特徵對映學習一對引數\(\gamma^{(k)}\)和\(\beta^{(k)}\),而不是每個啟用。第二個演算法進行類似的修改,以便推斷期間BN變換對在給定的特徵對映上的每一個啟用應用同樣的線性變換
批標準化可以提高學習率
通過標準化整個網路的啟用值,在資料通過深度網路傳播時,它可以防止層引數的微小變化被放大。批標準化也使訓練對引數的縮放更有彈性。通常,大的學習率可能會增加層引數的縮放,這會在反向傳播中放大梯度並導致模型爆炸。然而,通過批標準化,通過層的反向傳播不受其引數縮放的影響。對於標量\(\alpha\)
\[ BN(Wu)=BN((aW)u) \]
因此,\(\frac {∂BN((aW)u)}{∂u}= \frac {∂BN(Wu)}{∂u}\)。因此,標量不影響層的雅可比行列式,從而不影響梯度傳播。此外,\(\frac {∂BN((aW)u)}{∂(aW)}=\frac {1}{a}⋅\frac {∂BN(Wu)}{∂W}\),因此更大的權重會導致更小的梯度,並且批標準化會穩定引數的增長。研究者進一步推測,批標準化可能會導致雅可比行列式的奇異值接近於1,這被認為對訓練是有利的
實驗
實驗表明,批標準化有助於網路訓練的更快,取得更高的準確率,原因是隨著訓練的進行,批標準化網路中的分佈更加穩定,這有助於訓練
加速BN網路
提高學習率。在批標準化模型中,能夠從高學習率中實現訓練加速,沒有不良的副作用
刪除丟棄。發現從BN-Inception中刪除丟棄可以使網路實現更高的驗證準確率
推測批標準化提供了類似丟棄的正則化收益,因為對於訓練樣本觀察到的啟用受到了同一小批量資料中樣本隨機選擇的影響
更徹底地攪亂訓練樣本。這導致驗證準確率提高了約1%
減少L2全中正則化。雖然在Inception中模型引數的L2損失會控制過擬合,但在修改的BN-Inception中,損失的權重減少了5倍。研究者發現這提高了在提供的驗證資料上的準確性
通過僅使用批標準化(BN-Baseline),可以在不到Inception一半的訓練步驟數量內將準確度與其相匹配,這顯著提高了網路的訓練速度
結論
提出的方法(批標準化)大大加快了深度網路的訓練。該方法從標準化啟用以及將這種標準化結合到網路體系結構本身中汲取了它的力量。批處理規範化每次啟用只新增兩個額外的引數,並且這樣做保留了網路的表示能力。本文提出了一種用批量標準化網路構建、訓練和執行推理的演算法。所得到的網路可以用飽和非線性進行訓練,更容忍增加的訓練速率,並且通常不需要dropout來進行正規化
總結
為什麼需要它
在BN出現之前,我們的歸一化操作一般都在資料輸入層,對輸入的資料進行求均值以及求方差做歸一化,但是BN的出現打破了這一個規定,我們可以在網路中任意一層進行歸一化處理。因為我們現在所用的優化方法大多都是min-batch SGD,所以我們的歸一化操作就成為Batch Normalization
神經網路層之前的神經網路層的引數變化,將會引起神經網路每一層輸入資料的分佈產生了變化,這使得訓練一個深度神經網路會非常困難。作者稱這個現象為:internal covariate shift
BatchNorm就是在深度神經網路訓練過程中使得每一層神經網路的輸入保持相同的分佈的方法,是用來解決“Internal Covariate Shift”問題的
Mini-Batch SGD相對於One Example SGD的兩個優勢:梯度更新方向更準確;平行計算速度快
它的思想
BN的基本思想是:因為深層神經網路在做非線性變換前的啟用輸入值(就是那個x=WU+B,U是輸入)隨著網路深度加深或者在訓練過程中,其分佈逐漸發生偏移或者變動,之所以訓練收斂慢,一般是整體分佈逐漸往非線性函式的取值區間的上下限兩端靠近,這導致反向傳播時低層神經網路的梯度消失,這是訓練深層神經網路收斂越來越慢的本質原因,而BN就是通過一定的規範化手段,把每層神經網路任意神經元這個輸入值的分佈強行拉回到均值為0方差為1的標準正態分佈,這樣使得啟用輸入值落在非線性函式對輸入比較敏感的區域,這樣輸入的小變化就會導致損失函式較大的變化,即通過這種方法讓梯度變大,避免梯度消失問題產生,而且梯度變大意味著學習收斂速度快,能大大加快訓練速度
BN其實就是把每個隱層神經元的啟用輸入分佈從偏離均值為0方差為1的正態分佈通過平移均值壓縮或者擴大麴線尖銳程度,調整為均值為0方差為1的正態分佈
當輸入均值為0,方差為1時,當使用sigmoid啟用函式時,絕大多數的輸入都落到了[-2,2]的區間,而這一段是sigmoid函式接近於線性變換的區域,意味著x的小變化會導致非線性函式值較大的變化,也即是梯度變化較大,對應導數函式圖中明顯大於0的區域,就是梯度非飽和區。即經過BN後,目前大部分Activation的值落入非線性函式的線性區內,其對應的導數遠離導數飽和區,這樣來加速訓練收斂過程
然後為了不讓網路的表達能力下降,保證非線性的獲得,它又對變換後的滿足均值為0方差為1的x又進行了scale加上shift操作(y=scale*x+shift),這樣就等價於將非線性函式的值從正中心周圍的線性區往非線性區移動了一點
推理的過程中,我們得不到例項集合的均值和方差,因此,這裡用從所有訓練例項中獲得的統計量來代替Mini-Batch裡面m個訓練例項獲得的均值和方差統計量
BN的優點
- 提升了訓練速度,收斂過程大大加快
- 增加分類效果,一種解釋是這是類似於Dropout的,一種是自帶了防止過擬合的正則化表達方式,所以不用Dropout也能達到相當的效果
- 調參過程也簡單多了,對於初始化要求沒那麼高,而且可以使用大的學習率等
參考連結
深入理解Batch Normalization批標準化
批歸一化(Batch Normalization)
視訊連結