
GoogLeNetv4 論文研讀筆記
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
摘要
向傳統體系結構中引入殘差連線使網路的效能變得更好,這提出了一個問題,即將Inception架構與殘差連線結合起來是否能帶來一些好處。在此,研究者通過實驗表明使用殘差連線顯著地加速了Inception網路的訓練。也有一些證據表明,相比沒有殘差連線的消耗相似的Inception網路,殘差Inception網路在效能上具有微弱的優勢。針對是否包含殘差連線的Inception網路,本文同時提出了一些新的簡化網路,同時進一步展示了適當的啟用縮放如何使得很寬的殘差Inception網路的訓練更加穩定
引言
在本研究中,研究者研究了當時最新的兩個想法:殘差連線和最新版的Inception架構。他們研究了使用殘差連線來代替Inception架構中的過濾連線階段,這將使Inception架構保持它的計算效率的同時獲得殘差連線方法的好處。除了將兩者直接整合,也研究了Inception本身能否通過加寬和加深來變得更高效。為此,他們設計了Inception v4,相比v3,它有更加統一簡化的網路結構和更多的inception模組
在本文中,他們將兩個純Inception變體(Inception-v3和v4)與消耗相似的 Inception-ResNet混合版本進行比較。挑選的模型滿足和非殘差模型具有相似的引數和計算複雜度的約束條件。實驗對組合模型的效能進行了評估,結果顯示Inception-v4和Inception-ResNetv2的效能都很好,同時發現單個框架效能的提升不會引起組合效能大幅的提高
相關工作
殘差連線的作者認為殘差連線在訓練深度卷積模型是很有必要的,但是至少在影象識別上,本研究並不支援這一點,該實驗表明使用殘差連線來訓練深度網路也不是很難做到。不過,殘差連線所帶來的潛在優勢可能需要在更深網路結構中來展現。但是,使用殘差連線確實能夠極大地提高訓練速度,這一點很值得肯定。
殘差連線

為減少計算而優化的ResNet連線
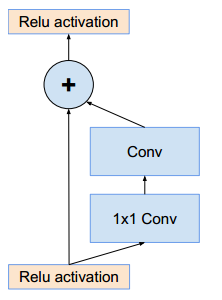
架構選擇
純Inception模組
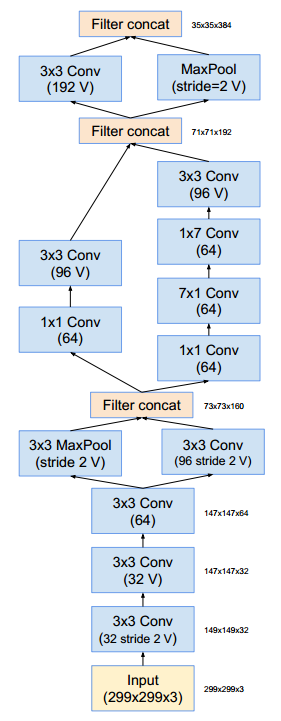
以前的Inception模組為了能夠在記憶體中對整個模型進行擬合,採用分散式訓練的方法,該方法將每個副本劃分成一個含多個子網路的模型。然而,Inception結構是高度可調的,這就意味著各層濾波器的數量可以有多種變化,而整個訓練網路的質量不會受到影響。為了優化訓練速度,他們對層的尺寸進行調整以平衡多模型子網路的計算。因為TensorFlow的引入和為了優化,本研究對Inception塊的每個網格尺寸進行了統一。以下所有架構圖中,卷積層沒有標記"V"的表示使用相同的填充原則,即它們的輸出網格尺寸與它們的輸入相匹配。標記了"V"的卷積層使用valid填充,即每個單元輸入塊全部包含在前幾層中,同時輸出啟用圖(output activation map)的網格尺寸也相應地減少
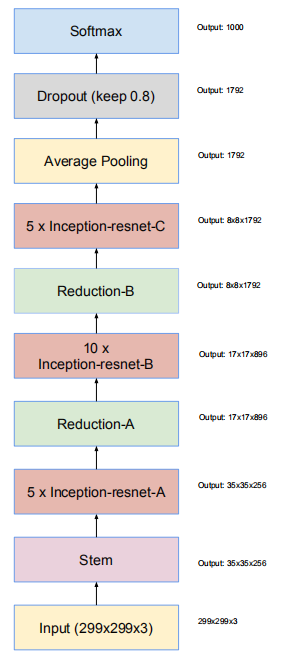
Inception-v4網路整體架構
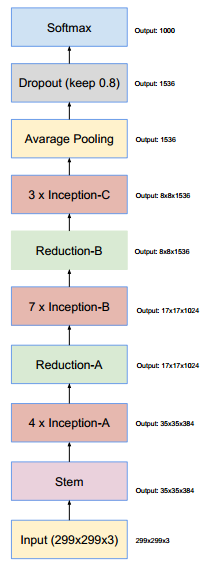
Inception-v4和Inception-ResNet-v2網路結構,這是輸入部分(Fig3)
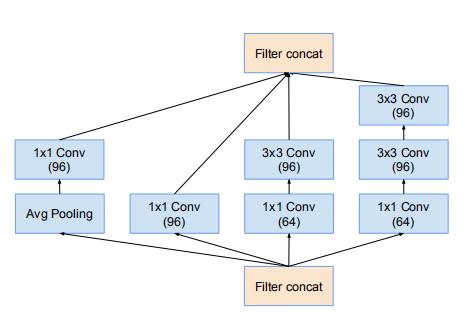
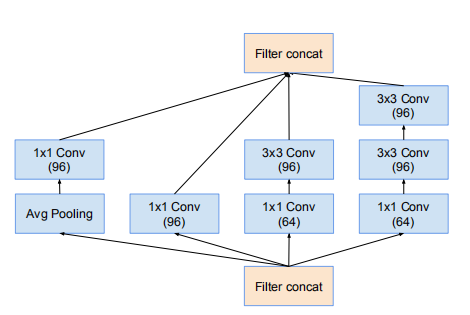
Inception-v4網路的35 * 35 網格模組,對應Inception-v4的Inception-A
Inception-v4網路的17 * 17 網格模組,對應Inception-v4的Inception-B
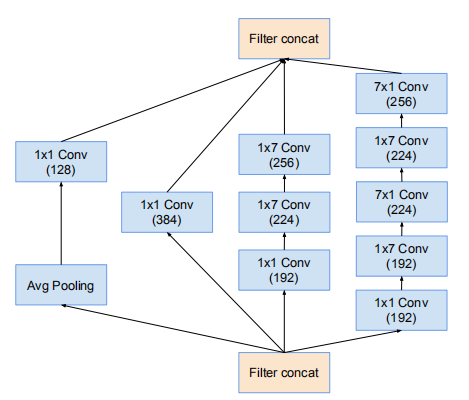
Inception-v4網路的8 * 8 網格模組,對應Inception-v4的Inception-C
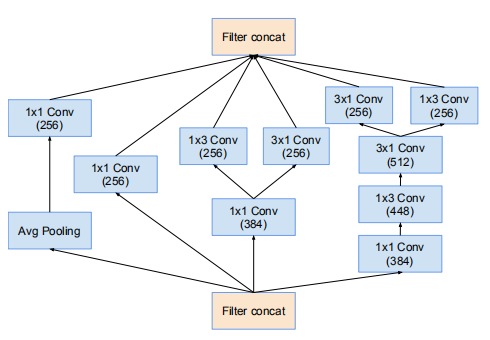
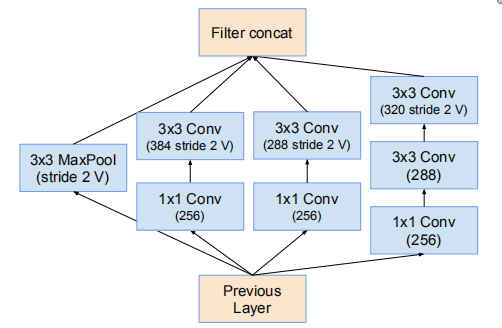
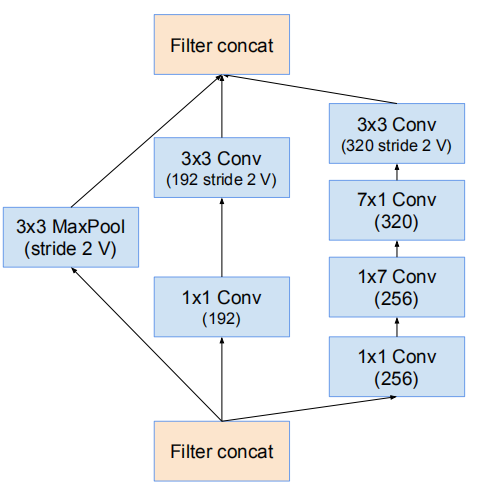
35 * 35 -> 17 * 17 的降維模組(Fig7)
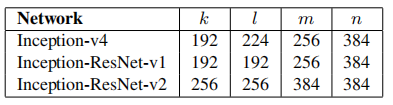
引數設定
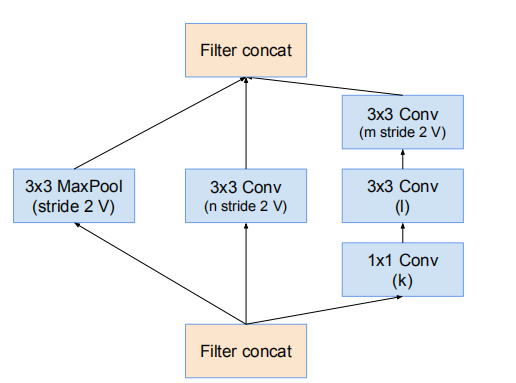
17 * 17 -> 8 * 8 的網格縮減模組
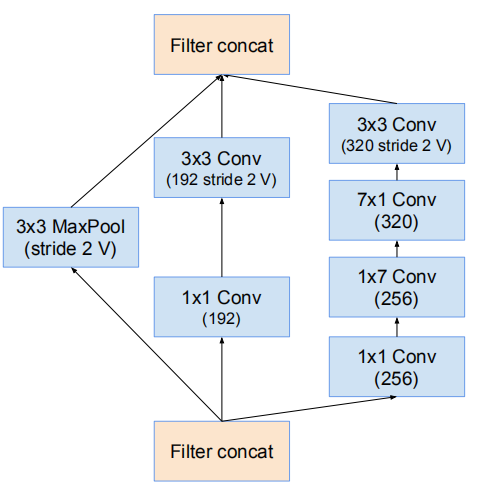
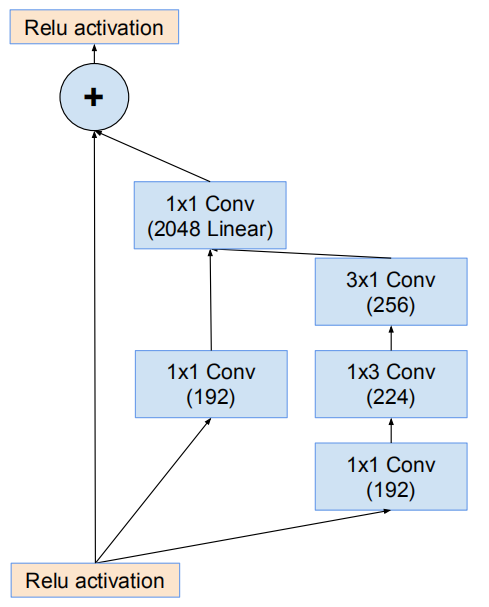
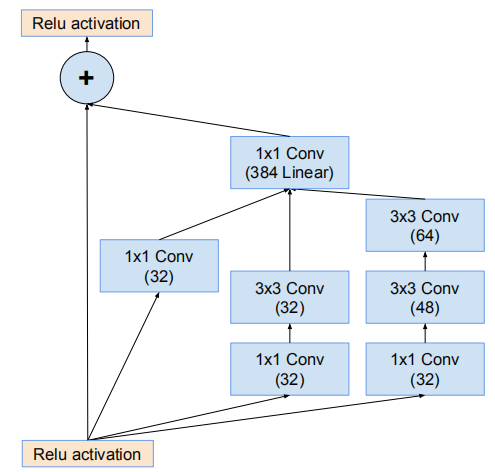
殘差Inception塊
殘差版本的Inception網路使用了比源Inception更廉價的Inception塊。每個Inception塊後緊連線著濾波膨脹層(沒有啟用函式的1×1卷積)以在相加之前放大濾波器組的維度,以實現輸入的匹配。這樣補償了在Inception塊中的降維。
Inception-ResNet-v1與Inception-v3的計算代價相近,Inception-ResNet-v2與Inception-v4的計算代價相近。另一個研究使用的殘差和非殘差變體技術上的不同是:在Inception-ResNet上僅在傳統層的頂部而非所有層的頂部中使用batch-normalization。這是因為研究者想要保持每個模型副本在單個GPU上就可以訓練,在部分層的頂部忽略 batch-normalization能夠增加Inception塊的數量
Inception-ResNet-v1和Inception-ResNet-v2網路完整架構
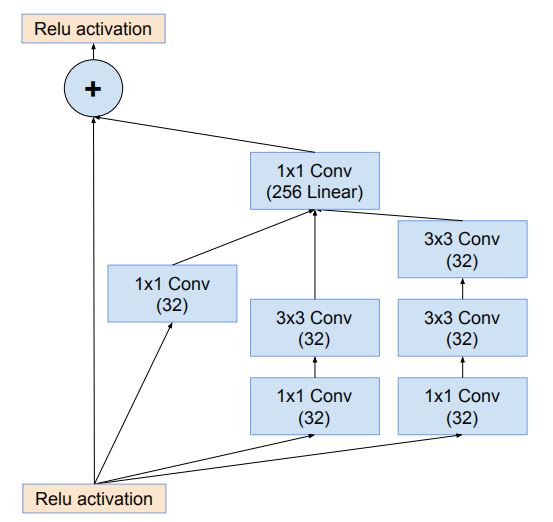
Inception-ResNet-v1
網路使用35*35網格模組(Inception-ResNet-A)
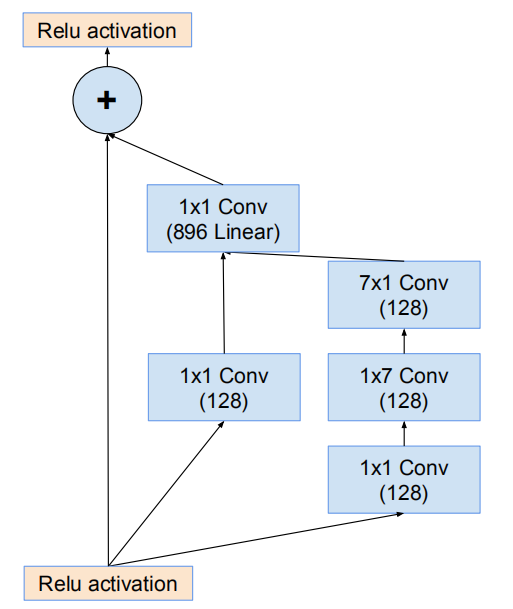
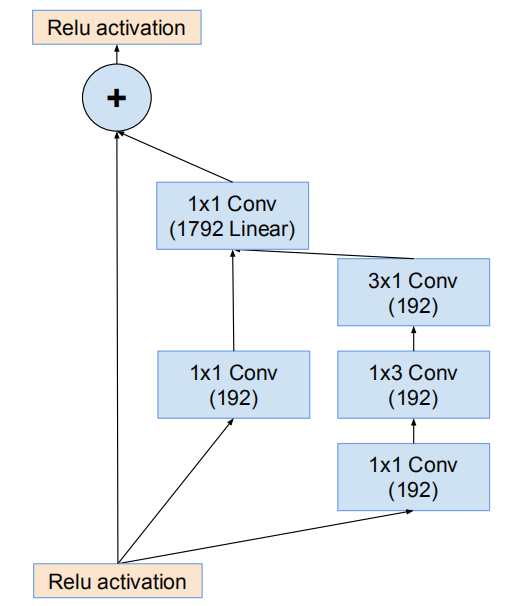
網路的17*17網格模組(Inception-ResNet-B)
使用Fig7作為Reduction-A
網路的17*17 -> 8*8網格縮減模組(Reduction-B)

網路的8*8網格模組(Inception-ResNet-C)
網路的主幹(stem)

Inception-ResNet-v2
Fig3用於網路stem
網路35*35的網格模組(Inception-ResNet-A)
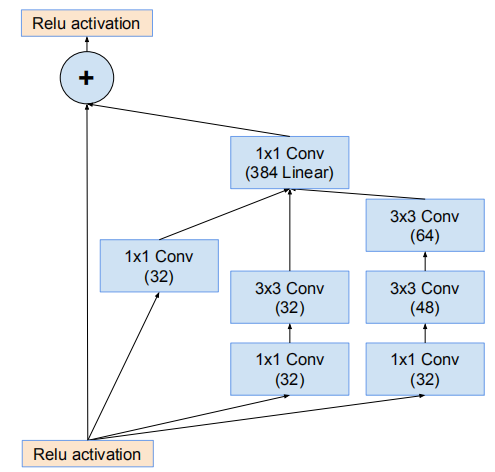
網路17*17網格模組(Inception-ResNet-B)
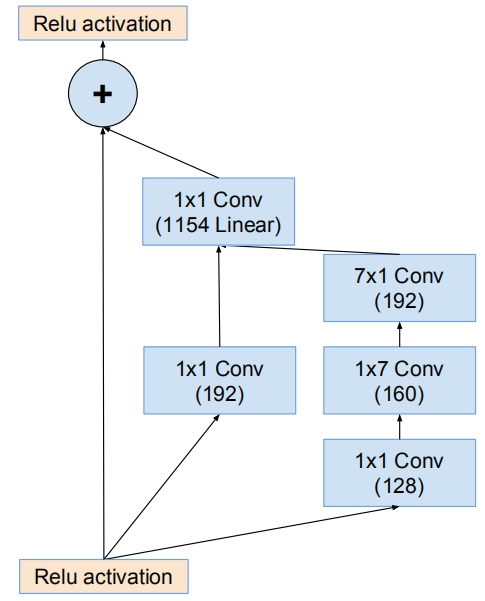
Fig7用於Reduction-A
網路17*17 -> 8*8網格縮減模組(Reduction-B)
網路8*8網格模組(Inception-ResNet-C)
對殘差模組的縮放
研究者發現如果濾波器數量超過1000,殘差網路開始出現不穩定,同時網路會在訓練過程早期便會出現“死亡”,意即經過成千上萬次迭代,在平均池化(average pooling) 之前的層開始只生成0。通過降低學習率,或增加額外的batch-normalizatioin都無法避免這種狀況。同時,發現在將殘差模組新增到activation啟用層之前,對其進行放縮能夠穩定訓練,通常來說將殘差放縮因子定在0.1-0.3,即使縮放並不是完全必須的,它似乎並不會影響最終準確率,但是放縮能有益於訓練的穩定性
實驗結果表明Inception-ResNet-v1,Inception-v4,Inception-ResNet-v2的錯誤率逐個降低並都比Inception-v3和BN-Inception表現的好
結論
本文詳細呈現了三種新的網路結構
- Inception-ResNet-v1:混合Inception版本,它的計算效率與Inception-v3相近
- Inception-ResNet-v2:更加昂貴的混合Inception版本,明顯改善了識別效能
- Inception-v4:沒有殘差連線的純Inception變種,效能與Inception-ResNet-v2相近
研究者們研究了引入殘差連線如何顯著地提高Inception網路地訓練速度。並且他們最新地模型僅僅憑藉增加模型尺寸就能表現地優於他們現有的網路
總結
本文研究了將Inception和殘差連線相結合的效果,實驗表明結合ResNet可以加速訓練,同時提高效能,在構建 Inception-ResNet 網路同時,還設計了一個更深更優化的 Inception v4 模型,能達到相媲美的效能
比較了一下文章中提到的三個網路的架構,然後發現,Inception-ResNet-v1與Inception-ResNet-v2,Inception-v4相比,最明顯的差別是stem部分不同,特別是與Inception-ResNet-v2相比,其它部分幾乎就只是卷積層數的變化,而在stem部分,其它兩個使用相同的結構,使用的引數量的比較 4112 : 5344,同時v1這部分輸出為35*35*256,其它兩個輸出為35*35*384,顯然這裡明顯讓v1吃虧了,其效能差的原因我覺得這個部分有很大的原因。之後Inception-ResNet-v2與Inception-v4相比,架構的總體結構可以看出是很相似的,最大的區別在於資料是否是直接傳到下一層的,如下
Inception-v4(Inception-A)
Inception-ResNet-v2(Inception-A)
Inception-v4(Reduction-B)
Inception-ResNet-v2(Reduction-B)
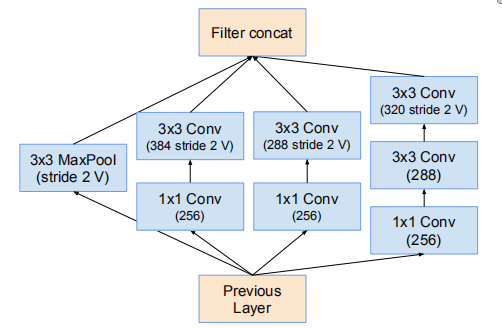
個人感覺差別不是很大,很直觀地可以看出因為Inception-ResNet-v2使用的變換較少,計算量較小,因而可以獲得更好的效能吧,其它的更多是各種引數的問題
GoogLeNetv1 論文研讀筆記
GoogLeNetv2 論文研讀筆記
GoogLeNetv3 論文研讀筆記
ResNet 論文研讀筆記