
決策樹基礎梳理
1.資訊理論基礎
1.1.熵
熵是資訊的關鍵度量,通常指一條資訊中需要傳輸或者儲存一個訊號的平均位元數。熵衡量了預測隨機變數的不確定度,不確定性越大熵越大。
針對隨機變數XX,其資訊熵的定義如下:
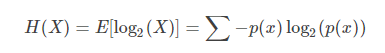
資訊熵是信源編碼中,壓縮率的下限。當我們使用少於資訊熵的資訊量做編碼,那麼一定有資訊的損失。
1.2.聯合熵
聯合熵是一集變數之間不確定的衡量手段。
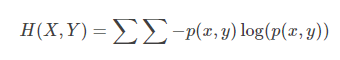
1.3.條件熵
條件熵描述變數Y在變數X確定的情況下,變數Y的熵還剩多少。

聯合熵和條件熵的關係是:
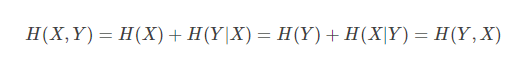
1.4.資訊增益
資訊增益在決策樹演算法中是用來選擇特徵的指標,資訊增益越大,則這個特徵的選擇性越好,在概率中定義為:待分類的集合的熵和選定某個特徵的條件熵之差(這裡只的是經驗熵或經驗條件熵,由於真正的熵並不知道,是根據樣本計算出來的),公式如下:
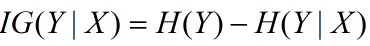
1.5.基尼不純度
基尼不純度:將來自集合的某種結果隨機應用於某一資料項的預期誤差率。
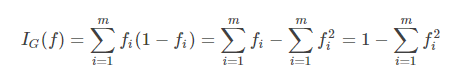
- (1)顯然基尼不純度越小,純度越高,集合的有序程度越高,分類的效果越好;
- (2)基尼不純度為 0 時,表示集合類別一致;
- (3)基尼不純度最高(純度最低)時,
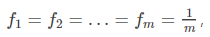
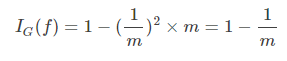
2.ID3演算法
2.1原理
ID3演算法的核心是在決策樹各個結點上應用資訊增益準則選擇特徵,遞迴地構建決策樹。具體方法是:從根結點開始,對結點計算所有可能的特徵的資訊增益,選擇資訊增益最大的特徵作為結點的特徵,由該特徵的不同取值建立子結點;再對子結點遞迴地呼叫以上方法,構建決策樹;直到所有特徵的資訊增益均很小或沒有特徵可以選擇為止。最後得到一個決策樹,ID3相當於用極大似然法進行概率模型的選擇
2.2過程
1.決策樹開始時,作為一個單個節點(根節點)包含所有訓練樣本集
2.若一個節點的樣本均為同一類別,則該節點就成為葉節點並標記為該類別。否則演算法將採用資訊熵(成為資訊增益)作為啟發指示來幫助選擇合適的(分支)屬性,以便將樣本集劃分為若干自己。選擇能夠最好地講樣本分類的屬性。該屬性成為該節點的“測試”或“判定”屬性。在演算法中,所有屬性均為離散值,若有取連續值的屬性,必須首先將其離散化。
3.對測試屬性的每個已知的值,建立一個分支,並據此劃分樣本
4.演算法使用同樣的過程,遞迴的形成每個劃分上的樣本判定樹。一旦一個屬性出現在一個節點上,就不必考慮該節點的任何後代
遞迴劃分步驟僅當下列條件之一成立時立即停止:
1.給定節點的所有樣本屬於同一類
2.沒有剩餘屬性可以用來進一步劃分樣本。在此情況下,使用多數表決,講給定的節點轉換成樹葉,並用樣本中的多數所在的類標記它。另外,可以存放節點樣本的類分佈。
3.分支test_attribute=a(i),沒有樣本。在這種情況下,以samples中的多數類建立一個樹葉。
2.3優缺點
優點:
理論清晰,演算法簡單,很有實用價值的示例學習演算法;
計算時間是例子個數、特徵屬性個數、節點個數之積的線性函式,總預測準確率較令人滿意
缺點:
存在偏向問題,各特徵屬性的取值個數會影響互資訊量的大小;
特徵屬性間的相關性強調不夠,是單變元演算法;
對噪聲較為敏感,訓練資料的輕微錯誤會導致結果的不同;魯棒性
結果隨訓練集記錄個數的改變而不同,不便於進行漸進學習
3.C4.5
3.1原理
C4.5演算法是用於生成決策樹的一種經典演算法,是ID3演算法的一種延伸和優化。
C4.5演算法採用PEP(Pessimistic Error Pruning)剪枝法
C4.5演算法通過資訊增益率選擇分裂屬性。
屬性A的“分裂資訊”(split information):、

其中,訓練資料集S通過屬性A的屬性值劃分為m個子資料集,|Sj||Sj|表示第j個子資料集中樣本數量,|S||S|表示劃分之前資料集中樣本總數量。
通過屬性A分裂之後樣本集的資訊增益:
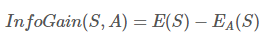
通過屬性A分裂之後樣本集的資訊增益率:
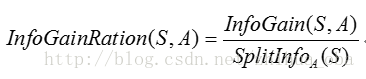
通過C4.5演算法構造決策樹時,資訊增益率最大的屬性即為當前節點的分裂屬性,隨著遞迴計算,被計算的屬性的資訊增益率會變得越來越小,到後期則選擇相對比較大的資訊增益率的屬性作為分裂屬性。
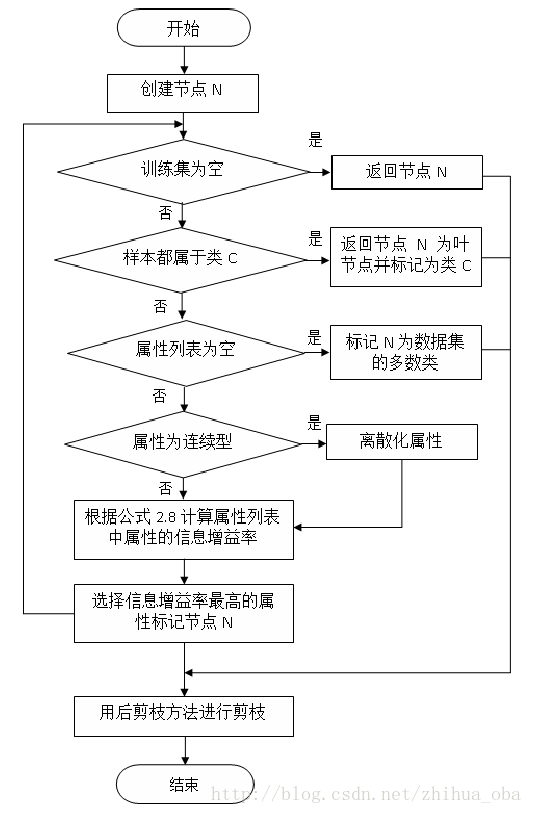
3.2過程
3.3優缺點
優點:
(1)通過資訊增益率選擇分裂屬性,克服了ID3演算法中通過資訊增益傾向於選擇擁有多個屬性值的屬性作為分裂屬性的不足;
(2)能夠處理離散型和連續型的屬性型別,即將連續型的屬性進行離散化處理;
(3)構造決策樹之後進行剪枝操作;
(4)能夠處理具有缺失屬性值的訓練資料。
缺點:
(1)演算法的計算效率較低,特別是針對含有連續屬性值的訓練樣本時表現的尤為突出。
(2)演算法在選擇分裂屬性時沒有考慮到條件屬性間的相關性,只計算資料集中每一個條件屬性與決策屬性之間的期望資訊,有可能影響到屬性選擇的正確性。
4.CART分類樹
4.1原理
Classification And Regression Tree(CART)是決策樹的一種,並且是非常重要的決策樹,屬於Top Ten Machine Learning Algorithm。顧名思義,CART演算法既可以用於建立分類樹(Classification Tree),也可以用於建立迴歸樹(Regression Tree)、模型樹(Model Tree),兩者在建樹的過程稍有差異。前文“機器學習經典演算法詳解及Python實現–決策樹(Decision Tree)”詳細介紹了分類決策樹原理以及ID3、C4.5演算法,本文在該文的基礎上詳述CART演算法在決策樹分類以及樹迴歸中的應用。
建立分類樹遞迴過程中,CART每次都選擇當前資料集中具有最小Gini資訊增益的特徵作為結點劃分決策樹。ID3演算法和C4.5演算法雖然在對訓練樣本集的學習中可以儘可能多地挖掘資訊,但其生成的決策樹分支、規模較大,CART演算法的二分法可以簡化決策樹的規模,提高生成決策樹的效率。對於連續特徵,CART也是採取和C4.5同樣的方法處理。為了避免過擬合(Overfitting),CART決策樹需要剪枝。預測過程當然也就十分簡單,根據產生的決策樹模型,延伸匹配特徵值到最後的葉子節點即得到預測的類別。
建立迴歸樹時,觀察值取值是連續的、沒有分類標籤,只有根據觀察資料得出的值來建立一個預測的規則。在這種情況下,Classification Tree的最優劃分規則就無能為力,CART則使用最小剩餘方差(Squared Residuals Minimization)來決定Regression Tree的最優劃分,該劃分準則是期望劃分之後的子樹誤差方差最小。建立模型樹,每個葉子節點則是一個機器學習模型,如線性迴歸模型
CART演算法的重要基礎包含以下三個方面:
(1)二分(Binary Split):在每次判斷過程中,都是對觀察變數進行二分。
CART演算法採用一種二分遞迴分割的技術,演算法總是將當前樣本集分割為兩個子樣本集,使得生成的決策樹的每個非葉結點都只有兩個分枝。因此CART演算法生成的決策樹是結構簡潔的二叉樹。因此CART演算法適用於樣本特徵的取值為是或非的場景,對於連續特徵的處理則與C4.5演算法相似。
(2)單變數分割(Split Based on One Variable):每次最優劃分都是針對單個變數。
(3)剪枝策略:CART演算法的關鍵點,也是整個Tree-Based演算法的關鍵步驟。
剪枝過程特別重要,所以在最優決策樹生成過程中佔有重要地位。有研究表明,剪枝過程的重要性要比樹生成過程更為重要,對於不同的劃分標準生成的最大樹(Maximum Tree),在剪枝之後都能夠保留最重要的屬性劃分,差別不大。反而是剪枝方法對於最優樹的生成更為關鍵。
4.2過程
CART假設決策樹是二叉樹,內部結點特徵的取值為“是”和“否”,左分支是取值為“是”的分支,右分支是取值為“否”的分支。這樣的決策樹等價於遞迴地二分每個特徵,將輸入空間即特徵空間劃分為有限個單元,並在這些單元上確定預測的概率分佈,也就是在輸入給定的條件下輸出的條件概率分佈。
CART演算法由以下兩步組成:
1.決策樹生成:基於訓練資料集生成決策樹,生成的決策樹要儘量大; 決策樹剪枝:用驗證資料集對已生成的樹進行剪枝並選擇最優子樹,這時損失函式最小作為剪枝的標準。
2.CART決策樹的生成就是遞迴地構建二叉決策樹的過程。CART決策樹既可以用於分類也可以用於迴歸。本文我們僅討論用於分類的CART。對分類樹而言,CART用Gini係數最小化準則來進行特徵選擇,生成二叉樹。 CART生成演算法如下:
輸入:訓練資料集D,停止計算的條件:
輸出:CART決策樹。
根據訓練資料集,從根結點開始,遞迴地對每個結點進行以下操作,構建二叉決策樹:
設結點的訓練資料集為D,計算現有特徵對該資料集的Gini係數。此時,對每一個特徵A,對其可能取的每個值a,根據樣本點對A=a的測試為“是”或 “否”將D分割成D1和D2兩部分,計算A=a時的Gini係數。
在所有可能的特徵A以及它們所有可能的切分點a中,選擇Gini係數最小的特徵及其對應的切分點作為最優特徵與最優切分點。依最優特徵與最優切分點,從現結點生成兩個子結點,將訓練資料集依特徵分配到兩個子結點中去。
對兩個子結點遞迴地呼叫步驟l~2,直至滿足停止條件。
生成CART決策樹。
演算法停止計算的條件是結點中的樣本個數小於預定閾值,或樣本集的Gini係數小於預定閾值(樣本基本屬於同一類),或者沒有更多特徵。
五.連續特徵和離散特徵處理

六.剪枝 模型評估
由於決策樹的建立完全是依賴於訓練樣本,因此該決策樹對訓練樣本能夠產生完美的擬合效果。但這樣的決策樹對於測試樣本來說過於龐大而複雜,可能產生較高的分類錯誤率。這種現象就稱為過擬合。因此需要將複雜的決策樹進行簡化,即去掉一些節點解決過擬合問題,這個過程稱為剪枝。
剪枝方法分為預剪枝和後剪枝兩大類。預剪枝是在構建決策樹的過程中,提前終止決策樹的生長,從而避免過多的節點產生。預剪枝方法雖然簡單但實用性不強,因為很難精確的判斷何時終止樹的生長。後剪枝是在決策樹構建完成之後,對那些置信度不達標的節點子樹用葉子結點代替,該葉子結點的類標號用該節點子樹中頻率最高的類標記。後剪枝方法又分為兩種,一類是把訓練資料集分成樹的生長集和剪枝集;另一類演算法則是使用同一資料集進行決策樹生長和剪枝。常見的後剪枝方法有CCP(Cost Complexity Pruning)、REP(Reduced Error Pruning)、PEP(Pessimistic Error Pruning)、MEP(Minimum Error Pruning)。
PEP(Pessimistic Error Pruning)剪枝法
PEP剪枝法由Quinlan提出,是一種自上而下的剪枝法,根據剪枝前後的錯誤率來判定是否進行子樹的修剪,因此不需要單獨的剪枝資料集。
對於一個葉子節點,它覆蓋了n個樣本,其中有e個錯誤,那麼該葉子節點的錯誤率為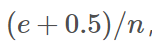 其中0.5為懲罰因子(懲罰因子一般取值為0.5)。
其中0.5為懲罰因子(懲罰因子一般取值為0.5)。
對於一棵子樹,它有L個葉子節點,那麼該子樹的誤判率為:

其中,ei表示子樹第i個葉子節點錯誤分類的樣本數量,ni表示表示子樹第i個葉子節點中樣本的總數量。
假設一棵子樹錯誤分類一個樣本取值為1,正確分類一個樣本取值為0,那麼子樹的誤判次數可以認為是一個伯努利分佈,因此可以得到該子樹誤判次數的均值和標準差:
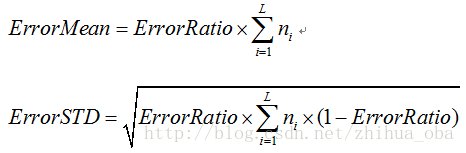
把子樹替換成葉子節點後,該葉子節點的誤判率為:
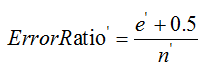
其中,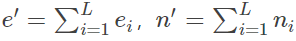
同時,該葉子結點的誤判次數也是一個伯努利分佈,因此該葉子節點誤判次數的均值為:
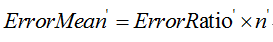
剪枝的條件為:

滿足剪枝條件時,則將所得葉子節點替換該子樹,即為剪枝操作。
CCP(代價複雜度)剪枝法
代價複雜度選擇節點表面誤差率增益值最小的非葉子節點,刪除該非葉子節點的左右子節點,若有多個非葉子節點的表面誤差率增益值相同小,則選擇非葉子節點中子節點數最多的非葉子節點進行剪枝。
可描述如下:
令決策樹的非葉子節點為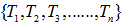 。
。
a)計算所有非葉子節點的表面誤差率增益值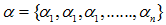
b)選擇表面誤差率增益值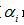 最小的非葉子節點
最小的非葉子節點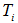 (若多個非葉子節點具有相同小的表面誤差率增益值,選擇節點數最多的非葉子節點)。
(若多個非葉子節點具有相同小的表面誤差率增益值,選擇節點數最多的非葉子節點)。
c)對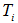 進行剪枝
進行剪枝
表面誤差率增益值的計算公式:
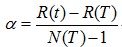
其中:
 表示葉子節點的誤差代價,
表示葉子節點的誤差代價,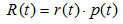 ,
,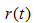 為節點的錯誤率,
為節點的錯誤率, 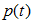 為節點資料量的佔比;
為節點資料量的佔比;
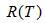 表示子樹的誤差代價,
表示子樹的誤差代價,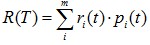 ,
, 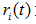 為子節點i的錯誤率,
為子節點i的錯誤率,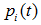 表示節點i的資料節點佔比;
表示節點i的資料節點佔比;
 表示子樹節點個數。
表示子樹節點個數。
算例:
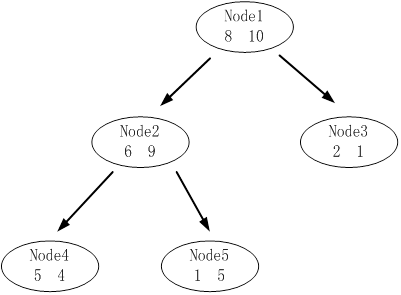
下圖是其中一顆子樹,設決策樹的總資料量為40。
該子樹的表面誤差率增益值可以計算如下:
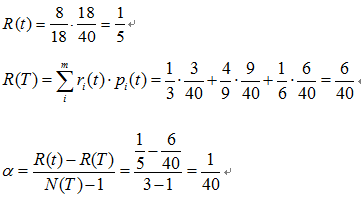
求出該子樹的表面錯誤覆蓋率為 ,只要求出其他子樹的表面誤差率增益值就可以對決策樹進行剪枝。
七.sklearn引數詳解
https://blog.csdn.net/young_gy/article/details/69666014
https://blog.csdn.net/u014688145/article/details/53212112
https://blog.csdn.net/yjt13/article/details/72794557
https://blog.csdn.net/zhihua_oba/article/details/70632622
https://blog.csdn.net/e15273/article/details/79648502