
常用的幾種機器學習演算法迴歸模型python程式碼實現
阿新 • • 發佈:2019-01-01
由於在論文實驗過程中一直使用的是python語言完成的論文實驗,所以在論文需要使用機器學習方法時就考慮使用了scikit-learn。
scikit-learn是一款很好的Python機器學習庫,它包含以下的特點:
(1)簡單高效的資料探勘和資料分析工具;
(2)可供大家使用,可在各種環境中重複使用;
(3)建立在NumPy, SciPy和matplotlib上;
(4)開放原始碼,可商業使用;
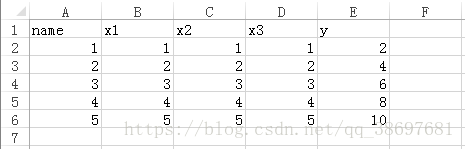
在本文中將把我在論文實驗過程中使用幾種機器學習方法原始碼貼出來方便呼叫,但每種機器學習方法的原理就不贅述了,可以參考官方給出的文件。這幾種方法使用的測試資料均為如下所示:
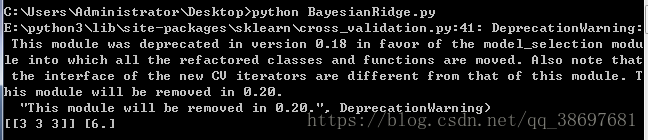
一、貝葉斯嶺迴歸
import numpy as np import pandas as pd from sklearn import datasets, linear_model from sklearn.cross_validation import train_test_split from sklearn import metrics from sklearn import preprocessing from sklearn.naive_bayes import GaussianNB from sklearn import linear_model from sklearn import metrics def Bayes(path): data = pd.read_excel(path) data.dropna(inplace=True) array=data.values X=array[:,1:len(data.columns)-1] y=array[:,len(data.columns)-1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) reg=linear_model.BayesianRidge() reg_=reg.fit(X_train, y_train) y_pred = reg.predict(X_test) return (X_test,y_pred) x,y=Bayes("./test.xls") print (x,y)
執行程式碼,可以看到結果如下所示:
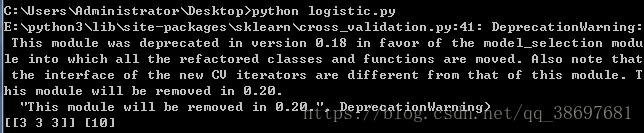
二、Logistic迴歸
import numpy as np import pandas as pd from sklearn import datasets, linear_model from sklearn.cross_validation import train_test_split from sklearn import metrics from sklearn import preprocessing from sklearn.linear_model import LogisticRegression from sklearn.svm import l1_min_c from sklearn import metrics def Logist(path): data = pd.read_excel(path) data.dropna(inplace=True) array=data.values X=array[:,1:len(data.columns)-1] y=array[:,len(data.columns)-1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0) cls = LogisticRegression(C=1.0,tol=1e-6) rbf=cls.fit(X_train, y_train) y_pred = cls.predict(X_test) return (X_test,y_pred) x,y=Logist("./test.xls") print(x,y)
執行程式碼,可以看到結果如下所示:
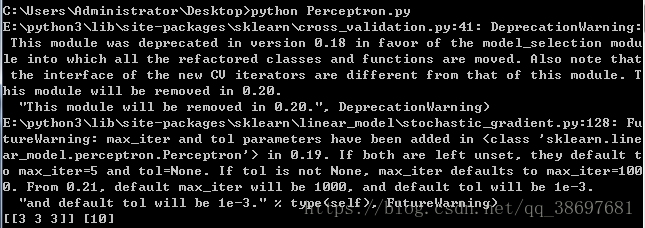
三、多層感知器
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn.linear_model import Perceptron
from sklearn import metrics
def Percep(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
per=Perceptron()
rbf=per.fit(X_train, y_train)
y_pred = per.predict(X_test)
return (X_test,y_pred)
#X=preprocessing.scale(X)
#y=preprocessing.scale(y)
x,y=Percep("./test.xls")
print(x,y)執行程式碼,可以看到結果如下所示:
四、支援向量機迴歸
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import svm
from sklearn import metrics
from sklearn import preprocessing
def SVM(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
#X=preprocessing.scale(X)
#y=preprocessing.scale(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
rbf_svc = svm.SVR(kernel='rbf') #此處使用的是徑向基核心
rbf_svc.tol=1
rbf=rbf_svc.fit(X_train, y_train)
y_pred = rbf_svc.predict(X_test)
return (X_test,y_pred)
x,y=SVM("./test.xls")
print(x,y)執行程式碼,可以看到結果如下所示:
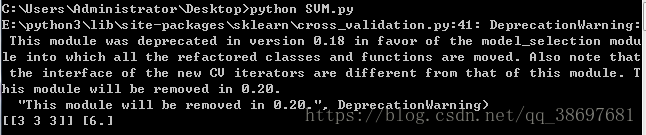
五、決策樹迴歸
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn import tree
def Tree(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
#X=preprocessing.scale(X)
#y=preprocessing.scale(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
clf = tree.DecisionTreeRegressor()
rbf=clf.fit(X_train, y_train)
y_pred = rbf.predict(X_test)
return (X_test,y_pred)
x,y=Tree("./test.xls")
print(x,y)執行程式碼,可以看到結果如下所示:
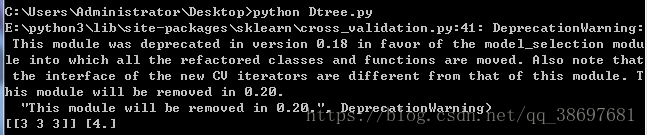
六、最近鄰迴歸
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn import neighbors
from sklearn import metrics
from sklearn.model_selection import cross_val_predict
def KNN(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
knn = neighbors.KNeighborsRegressor(1, weights="uniform") //修改第一個引數的值可以變為KNN_N近鄰
knn=knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
return(X_test,y_pred)
x,y=KNN("./test.xls")
print(x,y)執行程式碼,可以看到結果如下所示:
