
記錄我的大資料學習之旅 ---01.使用VMware安裝CentOs7
前言
從2017年初開始接觸大資料,從一無所知,到慢慢探索,到最後能夠獨立開發大資料專案。為此,趁著專案空閒的時間,分享與記錄一下我的大資料學習之旅。
一.準備資料,下載CentOs
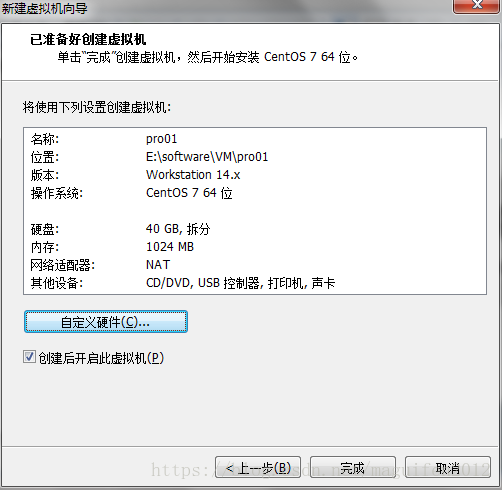
二.新建虛擬機器(檔案 →新建虛擬機器,如圖:)
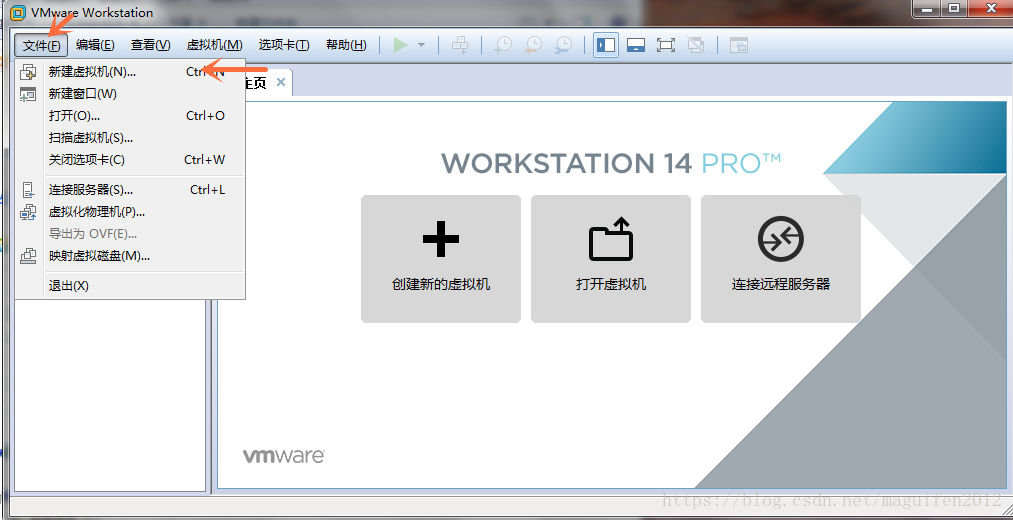
三,進入虛擬機器安裝嚮導,一般選擇典型安裝

四,選擇CentOs7映象檔案的路徑
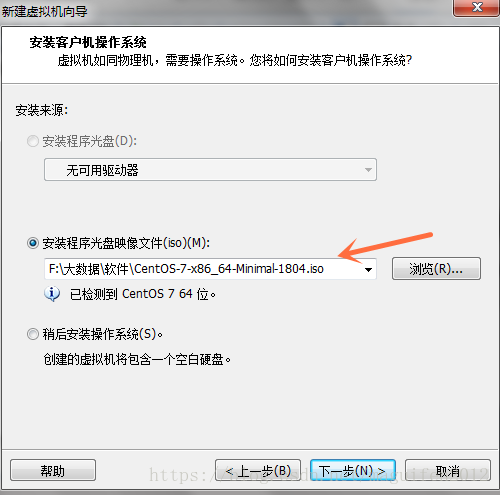
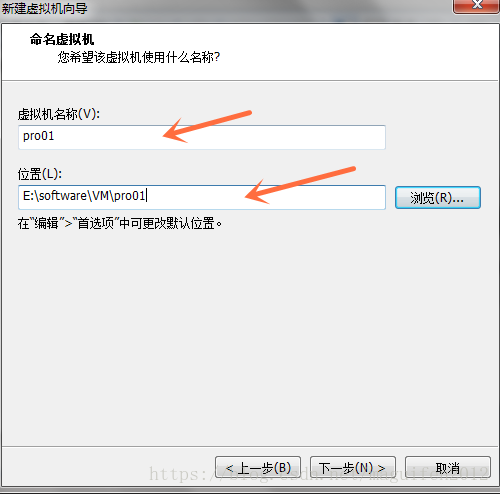
五,修改虛擬機器的名稱以及虛擬機器的存放位置
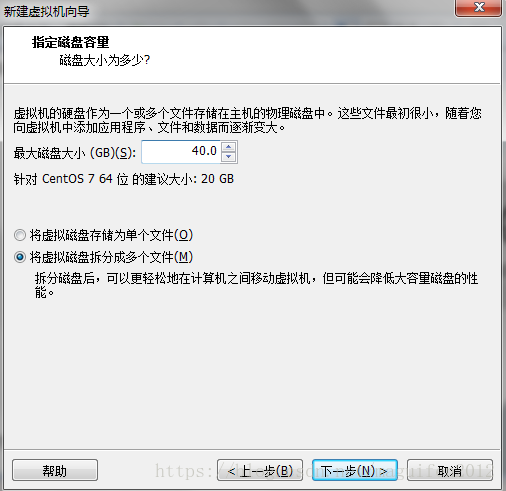
六、指定虛擬機器磁碟的容量
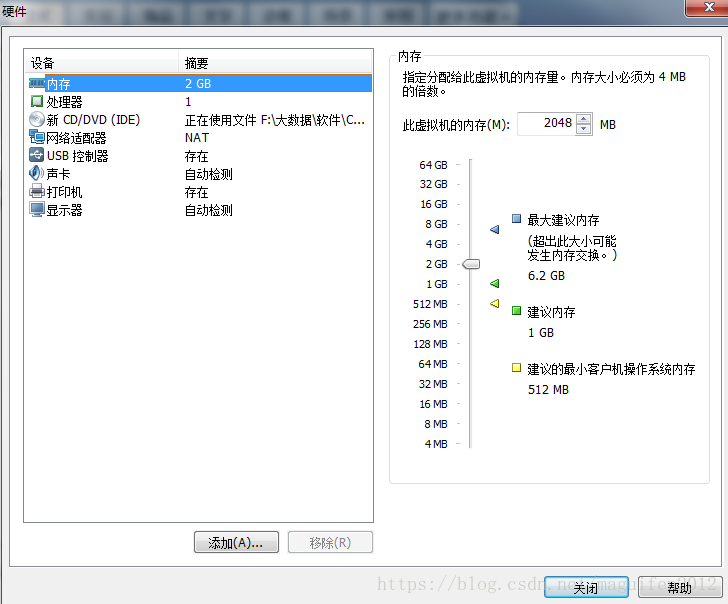
七,點選自定義硬體按鈕,設定虛擬機器的記憶體
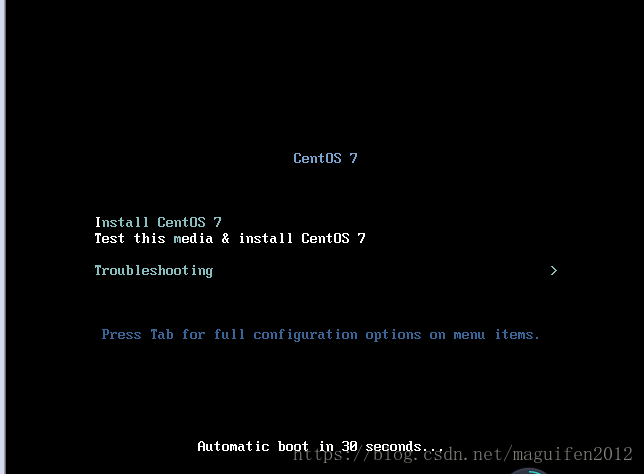
八,選擇第一個然後回車 接著等待安裝
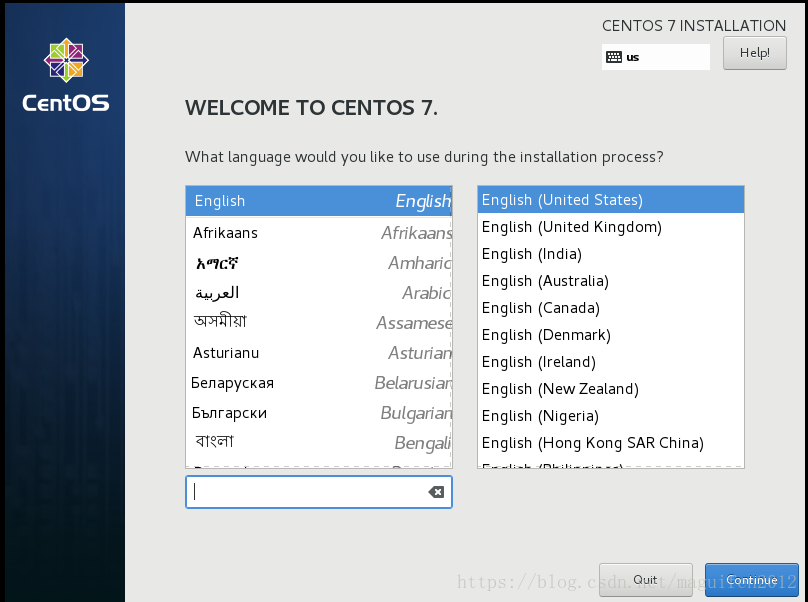
九,選擇虛擬機器的系統語言
十,設定系統的時區

十一,點選安裝位置,進入頁面,點選完成即可,系統會自動進行分割槽
十二,設定root以及普通使用者的賬號密碼

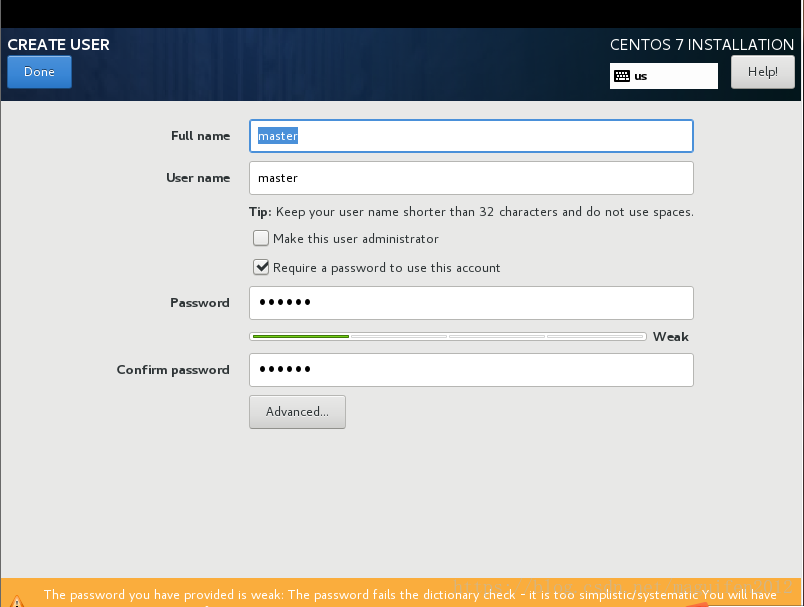
至此,VMware安裝CentOs7完成

下一篇文章將分享,Linux系統的常規設定
相關推薦
記錄我的大資料學習之旅 ---01.使用VMware安裝CentOs7
前言 從2017年初開始接觸大資料,從一無所知,到慢慢探索,到最後能夠獨立開發大資料專案。為此,趁著專案空閒的時間,分享與記錄一下我的大資料學習之旅。 一.準備資料,下載CentOs 二.新建虛擬機器
記錄我的Python學習之旅(二)time庫的基本操作
1、time() 功能:獲取當前時間戳,即計算機內部時間值,浮點數 2、ctime() 功能:獲取當前時間並以易讀方式表示,返回字串 3、gmtime() 功能:獲取當前實踐,表示為計算機可處理的時間格式 4、時間格式化:如t=time.gmtime()
記錄我的Python學習之旅(一)關於turtle庫的基本用法
關於庫函式的匯入方法:①import <> ②import <> as <> ③ from tutle import <> 1、turtle.setup(width,height,startx,starty) /
13.大資料學習之旅——HBase第三天
LSM-TREE 概述 眾所周知傳統磁碟I/O是比較耗效能的,優化系統性能往往需要和磁碟I/O打交道,而磁碟I/O產 生的時延主要由下面3個因素決定: 1)尋道時間(將磁碟臂移動到適當的柱面上所需要的時間,尋道時移動到相鄰柱面移動所需 時間1ms,而隨機移動所需時間位5~1
12.大資料學習之旅——HBase第二天
HBASE完全分散式安裝 實現步驟 準備三臺虛擬機器,01作為主節點,02、03作為從節點。(把每臺虛擬機器防火牆都關掉,配 置免密碼登入,配置每臺的主機名和hosts檔案。) 01節點上安裝和配置:Hadoop+Hbase+JDK+Zookeeper
11.大資料學習之旅——HBase
一、HBASE概述 官方網址:http://hbase.apache.org/ HBase是一個分散式的、面向列的開源資料庫,該技術來源於Fay Chang 所撰寫的Google論文《Bigtable》一個結構 化資料的分散式儲存系統"。就像Bigtable利用了Google
10.大資料學習之旅——hive2
Hive解決資料傾斜問題 概述 什麼是資料傾斜以及資料傾斜是怎麼產生的? 簡單來說資料傾斜就是資料的key 的分化嚴重不均,造成一部分資料很多,一部分資料很少的局面。 舉個 word count 的入門例子,它的map 階段就是形成 (“aaa”,1)的形式,然後在redu
9.大資料學習之旅——hive
Hive介紹 Hadoop開發存在的問題 只能用java語言開發,如果是c語言或其他語言的程式設計師用Hadoop,存 在語言門檻。 需要對Hadoop底層原理,api比較瞭解才能做開發。 Hive概述 Hive是基於Hadoop的一個數據倉庫工具。可以將結構
8.大資料學習之旅——hadoop-Hadoop完全分散式配置
Hadoop完全分散式配置 關閉防火牆 修改主機名 配置hosts檔案。將需要搭建叢集的主機全部配置到hosts檔案中 192.168.32.138 hadoop01 192.168.32.139 hadoop02 192.168.32.14
7.大資料學習之旅——hadoop-MapReduce
序列化/反序列化機制 當自定義一個類之後,如果想要產生的物件在hadoop中進行傳輸,那麼需要 這個類實現Writable的介面進行序列化/反序列化 案例:統計每一個人產生的總流量 import java.io.DataInput; import java.io.DataOutp
5.大資料學習之旅——hadoop-HDFS
NameNode 檢視edits檔案: hdfs oev -i edits_0000000000000000022-0000000000000000023 -o edits.xml 檢視fsimage檔案: hdfs oiv -i fsimage_000000000000000002
5.大資料學習之旅——hadoop-簡介及偽分散式安裝
Hadoop簡介 是Apache的頂級專案,是一個可靠的、可擴充套件的、支援分散式計算的開源 專案。 起源 創始人:Doug Cutting 和Mike 2004 Doug和Mike建立了Nutch - 利用通用爬蟲爬取了網際網路上的所有數 據,獲取了10億個網頁資料 - 1
4.大資料學習之旅——Avro
一、概述 Avro是一種遠端過程呼叫和資料序列化框架,是在Apache的Hadoop專案之內開發的。它使用JSON來定義資料類 型和通訊協議,使用壓縮二進位制格式來序列化資料。它主要用於Hadoop,它可以為持久化資料提供一種序列化格 式,併為Hadoop節點間及從客戶端程式到
3.大資料學習之旅——Zookeeper
Zookeeper Zookeeper是開源的分散式的協調服務框架,是Apache Hadoop的子件,適用 於絕大部分分散式叢集的管理 分散式引發問題: 死鎖:至少有一個執行緒佔用了資源,但是不佔用CPU 活鎖:所有執行緒都沒有把持資源,但是執行緒卻是在不斷地
2.大資料學習之旅——紅黑樹
紅黑樹 自平衡二叉查詢樹 — 時間複雜度O(logn) 特徵: 每一個節點非紅即黑 根節點一定是黑色 所有的葉子節點一定是黑色的nil節點 紅節點的子節點一定是黑節點 任意一條路徑中的黑色節點個數一致 插入的節點一定是紅色 修復
1.大資料學習之旅——NIO
Concurrent包 jdk1.5所提供的一個針對高併發進行程式設計的包。 阻塞式佇列 - BlockingQueue 遵循先進先出(FIFO)的原則。阻塞式佇列本身使用的時候是需要指定界限。 ArrayBlockingQueue - 阻塞式順序佇列 - 底層是基於陣列來進
14.大資料學習之旅——HBASE表設計&HBase優化
HBASE表設計 Rowkey設計 Rowkey是不可分割的位元組數,按字典排序由低到高儲存在表中。 在設計HBase表時,Rowkey設計是最重要的事情,應該基於預期的訪問模式來為Rowkey建 模。Rowkey決定了訪問HBase表時可以得到的效能,原因有兩個: 1)R
16.大資料學習之旅——Storm叢集配置&Strom叢集中各角色說明&Storm併發機制*
實現步驟: 安裝和配置jdk 安裝和配置zookeeper 上傳和解壓storm 配置storm安裝目錄conf目錄下的storm.yaml檔案 storm.yaml配置示例: 注意配置項開頭需要有空格,:後面需要跟空格,否則啟動會報錯 5.
19.大資料學習之旅——flume介紹
flume介紹 概述 Flume最早是Cloudera提供的日誌收集系統,後貢獻給Apache。所以目前是Apache下的專案,Flume支援在日誌 系統中定製各類資料傳送方,用於收集資料。 Flume是一個高可用的,高可靠的魯棒性(robust 健壯性),分散式的海量日誌採集、聚合
大資料學習之旅2——從零開始搭hadoop完全分散式叢集
前言 本文從零開始搭hadoop完全分散式叢集,大概花費了一天的時間邊搭邊寫部落格,一步一步完成完成叢集配置,相信大家按照本文一步一步來完全可以搭建成功。需要注意的是本文限於篇幅和時間的限制,也是為了突出重點,一些很基礎的操作就不再詳細