
9.大資料學習之旅——hive
Hive介紹

Hadoop開發存在的問題
只能用java語言開發,如果是c語言或其他語言的程式設計師用Hadoop,存
在語言門檻。
需要對Hadoop底層原理,api比較瞭解才能做開發。
Hive概述
Hive是基於Hadoop的一個數據倉庫工具。可以將結構化的資料檔案對映為
一張表,並提供完整的sql查詢功能,可以將 sql語句轉換為 MapReduce任
務進行執行。其優點是學習成本低,可以通過類 SQL語句快速實現
MapReduce統計,不必開發專門的MapReduce應用,十分適合資料倉庫的統
計分析。
Hive是建立在 Hadoop 上的資料倉庫基礎構架。它提供了一系列的工具,
可以用來進行資料提取、轉化、載入( ETL Extract- - Transform- - Load ),
也可以叫做資料清洗,這是一種可以儲存、查詢和分析儲存在 Hadoop 中
的大規模資料的機制。Hive 定義了簡單的類 SQL 查詢語言,稱為
HiveQL,它允許熟悉 SQL 的使用者查詢資料。
Hive的Hq
HQL - Hive通過類SQL的語法,來進行分散式的計算。HQL用起來和SQL非
常的類似, Hive在執行的過程中會將 HQL轉換為 MapReduce去執行,所以
Hive其實是基於Hadoop的一種分散式計算框架,底層仍然是,所以它本質上還是一種離線大資料分析工具。
資料倉庫的特徵
- 資料倉庫是多個異構資料來源所整合的。
- 資料倉庫儲存的一般是歷史資料。 大多數的應用場景是讀資料(分析
資料),所以資料倉庫是弱事務的。 - 資料庫是為捕獲資料而設計,資料倉庫是為分析資料而設計。
- 資料倉庫是時變的,資料儲存從歷史的角度提供資訊。即資料倉庫中的
關鍵結構都隱式或顯示地包含時間元素。 - 資料倉庫是弱事務的,因為資料倉庫存的是歷史資料,一般都讀(分
析)資料場景。
資料庫屬於OLTP系統。(Online n Transaction Processing)聯機事務處
理系統。涵蓋了企業大部分的日常操作,如購物、庫存、製造、銀行、工
資、註冊、記賬等。比如Mysql,oracle等關係型資料庫。
資料倉庫屬於OLAP系統。(Online l Analytical Processing)聯機分析處
理系統。Hive,Hbase等
OLTP是面向使用者的、用於程式設計師的事務處理以及客戶的查詢處理。
OLAP是面向市場的,用於知識工人(經理、主管和資料分析人員)的資料
分析。
OLAP通常會整合多個異構資料來源的資料,數量巨大。
OLTP系統的訪問由於要保證原子性,所以有事務機制和恢復機制。
OLAP系統一般儲存的是歷史資料,所以大部分都是隻讀操作,不需要事務。


適用場景
Hive 構建在基於靜態(離線)批處理的Hadoop 之上,Hadoop 通常都有較
高的延遲並且在作業提交和排程的時候需要大量的開銷。因此,Hive 並不
能夠在大規模資料集上實現低延遲快速的查詢,例如,Hive 在幾百MB 的
資料集上執行查詢一般有分鐘級的時間延遲。因此,Hive 並不適合那些需
要低延遲的應用,例如,聯機事務處理(OLTP)。Hive 查詢操作過程嚴格遵
守Hadoop MapReduce 的作業執行模型,Hive 將使用者的HiveQL 語句通過解
釋器轉換為MapReduce 作業提交到Hadoop 叢集上,Hadoop 監控作業執行
過程,然後返回作業執行結果給使用者。Hive 並非為聯機事務處理而設計,
Hive 並不提供實時的查詢和基於行級的資料更新操作。Hive 的最佳使用場
合是大資料集的離線批處理作業,例如,網路日誌分析。
Hive的安裝配置
實現步驟
- 安裝JDK
- 安裝Hadoop
- 配置JDK和Hadoop的環境變數
- 下載Hive安裝包
- 解壓安裝hive
- 啟動Hadoop的HDFS和Yarn
- 啟動Hive
進入到bin目錄,指定:sh hive (或者執行:./hive)

Hive基礎指令






Hive的內部表和外部表
在檢視元資料資訊時,有一張TBLS表,
其中有一個欄位屬性:TBL_TYPE——MANAGED_TABLE
MANAGED_TABLE 表示內部表

內部表的概念
先在hive裡建一張表,然後向這個表插入資料(用insert可以插入資料,也可以通過載入外部
檔案方式來插入資料),
這樣的表稱之為hive的內部表。
什麼是內部表:現有hive表,再有資料
特點是:當內部表被刪除時,對應的HDFS的資料也會被刪除掉
外部表的概念
HDFS裡已經有資料了,比如有一個2.txt檔案,裡面儲存了這樣的一些資料:
1 jary
2 rose
什麼是外部表:先有資料,再建立hive表
特點是:刪除外部表,但對應的資料依然還在
在實際生產環境下,大多數建立都是外部表
然後,通過hive建立一張表stu來管理這個檔案資料。則stu這樣表稱之為外部表。注意,hive
外部表管理的是HDFS裡的某一個目錄下的檔案資料。
所以,做這個實驗,要先HDFS建立一個目錄節點,然後把資料檔案上傳到這個目錄節點下。
建立外部表的命令:
進入hive,執行:
create external table stu (id int,name string) row format delimited fields terminated
by ' ' location '/目錄路徑'
然後檢視TBLS表,

hive無論是內部表或外部表,當向HDFS對應的目錄節點下追加檔案時(只要格式符合),
hive都可以把資料管理進來
內部表和外部標的區別
通過hive執行:drop table stu 。這是刪除表操作。如果stu是一個內部表,則HDFS對應的目錄
節點會被刪除。
如果stu是一個外部表,HDFS對應的目錄節點不會刪除
Hive分割槽表
概念
Hive的表有兩種,①內部表 ②外部表
此外,內部表和外部表都可以是分割槽表
分割槽表的作用:可以避免查詢整表,在生產環境下,基本都是建立帶有分割槽欄位的表,
在查詢時,帶上分割槽條件。
分割槽表在HDFS,一個分割槽,就對應一個目錄。
分割槽表的實際應用:一般是以天為單位來建立分割槽,這樣方便管理表資料,
尤其是按日期查詢很方便。比如:
普通表和分割槽表區別:有大量資料增加的需要建分割槽表
語法
執行:
create table book (id int, name string) partitioned by (category string)
row format delimited fields terminated by '\t';
注:在建立分割槽表時,partitioned欄位可以不在欄位列表中。生成的表中自動就會具有該欄位。
category 是自定義的欄位。
分割槽表載入資料
load data local inpath '/home/cn.txt' overwrite into table book partition (category='cn');
load data local inpath './book_english.txt' overwrite into table book partition (category='en');
經檢查發現分割槽也是一個目錄。

select * from book; //查詢book目錄下的所有資料
select * from book where category='cn'; //只查詢 cn分割槽的資料
此外,通過檢視mysql的SDS表來查詢元資料資訊

通過建立目錄來增加分割槽
如果想先在HDFS的目錄下,自己建立一個分割槽目錄,然後在此目錄下上傳檔案,比如:
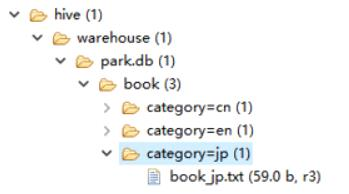
此時手動建立目錄是無法被hive使用的,因為元資料庫中沒有記錄該分割槽。
如果需要將自己建立的分割槽也能被識別,
需要執行:ALTER TABLE book add PARTITION (category = ‘fr’) location
‘/user/hive/warehouse/park01.db/book/category=fr’;
這行命令的作用是在元資料Dock表裡建立對應的元資料資訊
分割槽命令
- 顯示分割槽
show partitions iteblog;
- 新增分割槽
alter table book add partition (category='jp') location
'/user/hive/warehouse/test.db/book/category=jp';
或者:
msck repair table book;
- 刪除分割槽
alter table book drop partition(category='cn')
- 修改分割槽
alter table book partition(category='french') rename to partition (category='hh');
Hive 資料型別
常用的基本資料型別
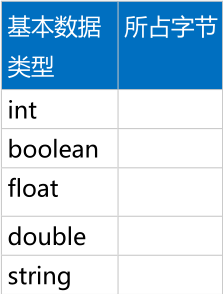
複雜資料型別

一、陣列型別 array
案例一
元資料:
100,200,300
200,300,500
建表語句:
create external table ex(vals array<int>) row format delimited
fields terminated by '\t' collection items terminated by ',' location
'/ex';
查詢每行陣列的個數,查詢語句:
select size(vals) from ex;
注:hive 內建函式不具備查詢某個具體行的陣列元素。需要自定義函式
來實現,但這樣的需求在實際開發裡很少,所以不需要在意。
案例二
元資料:
100,200,300 tom,jary
200,300,500 rose,jack
建表語句:
create external table ex1( info1 array<int>, info2 array<string>)
row format delimited fields terminated by '\t' collection items
terminated by ',' location '/ex';
結果:
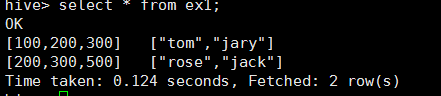
二、map型別
案例一
元資料:
tom,23
rose,25
jary,28
建表語句:
create external table m1 ( vals map<string,int>) row format
delimited fields terminated by '\t' map keys terminated by ','
location '/map';
查詢語句:
select vals['tom'] from m1;
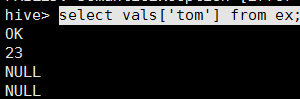
案列二
要求查詢tom這個人都瀏覽了哪些網站,並且為null的值不顯示
源資料(分隔符為空格):
tom 192.168.234.21
rose 192.168.234.21
tom 192.168.234.22
jary 192.168.234.21
tom 192.168.234.24
tom 192.168.234.21
rose 192.168.234.21
tom 192.168.234.22
jary 192.168.234.21
tom 192.168.234.22
tom 192.168.234.23
建表語句
create external table ex (vals map<string,string>) row format
delimited fields terminated by '/t' map keys terminated by ' '
location '/ex';
注意:map型別,列的分割符必須是\t
查詢語句
select vals['tom'] from ex where vals['tom'] is not null;
如果想做去重工作,可以呼叫distinct內建函式
select distinct(ip) from (select vals['tom'] ip from ex where
vals['tom'] is not null)ex1;
select distinct(vals['tom']) from m2 where vals['tom'] is not null;
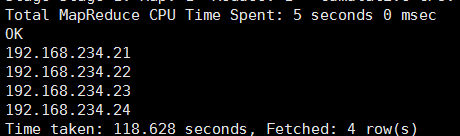
三、struct 型別
元資料:
tom 23
rose 22
jary 26
建表語句:
create external table ex (vals struct<name:string,age:int>)row
format delimited collection items terminated by ' ' location
'/ex';
查詢語句:
select vals.age from ex where vals.name='tom';
Hive常用字串操作函式




Hive explode
explode 命令可以將行資料,按指定規則切分出多行。
案例一,利用split執行切分規則
有如下資料:
100,200,300
200,300,500
要將上面兩行資料根據逗號拆分成多行(每個數字佔一行)
實現步驟
1.準備元資料
2.上傳HDFS,並建立對應的外部表
執行:create external table ex1 (num string) location ‘/ex’;
注:用explode做行切分,注意表裡只有一列,並且行資料是string型別,因為只有字元型別
才能做切分。
3.通過explode指令來做行切分
執行:select explode(split(num,',')) from ex1;
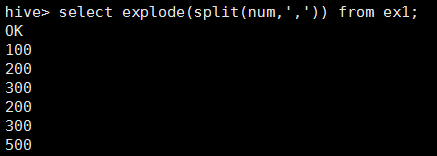
Hive的UDF
如果hive的內建函式不夠用,我們也可以自己定義函式來使用,這樣的函式稱為
hive的使用者自定義函式,簡稱UDF。
實現步驟:
- 新建java工程,匯入hive相關包,匯入hive相關的lib。
- 建立類繼承UDF
- 自己編寫一個evaluate方法,返回值和引數任意。

- 為了能讓mapreduce處理,String要用Text處理。
- 將寫好的類打成jar包,上傳到linux中
- 在hive命令列下,向hive註冊UDF:add jar /xxxx/xxxx.jar

- 在hive命令列下,為當前udf起一個名字:
create temporary function fname as '類的全路徑名';

- 之後就可以在hql中使用該自定義函數了。
