
13.大資料學習之旅——HBase第三天
LSM-TREE
概述
眾所周知傳統磁碟I/O是比較耗效能的,優化系統性能往往需要和磁碟I/O打交道,而磁碟I/O產
生的時延主要由下面3個因素決定:
1)尋道時間(將磁碟臂移動到適當的柱面上所需要的時間,尋道時移動到相鄰柱面移動所需
時間1ms,而隨機移動所需時間位5~10ms)
2)旋轉時間(等待適當的扇區旋轉到磁頭下所需要的時間)
3)實際資料傳輸時間(低端硬碟的傳輸速率為5MB/ms,而高速硬碟的速率是10MB/ms)
近20年平均尋道時間改進了7倍,傳輸速率改進了1300倍,而容量的改進則高達50000倍,這
一格局主要是因為磁碟中運動部件的改進相對緩慢和漸進,而記錄表面則達到了相當高的密
度。對於一個塊的訪問完全由尋道時間和旋轉延遲所決定,所以花費相同時間訪問一個盤塊,
那麼取的資料越多越好。
磁碟I/O瓶頸可能出現在seek(尋道)和transfer(資料傳輸)上面。
根據磁碟I/O型別,關係型儲存引擎中廣泛使用的B樹及B+樹,而Bigtable的儲存架構基礎的會
使用Log-Structured Merge Tree。
B- Tree和B+Tree
如果沒有太多的寫操作,B+樹可以工作的很好,它會進行比較繁重的優化來保證較低的訪問
時間。而寫操作往往是隨機的,隨機寫到磁碟的不同位置上,更新和刪除都是以磁碟seek的速
率級別進行的。RDBMS通常都是Seek型的,主要是由用於儲存資料的B樹或者是B+樹結構引起
的,在磁碟seek的速率級別上實現各種操作,通常每個訪問需要log(N)個seek操作
LSM-Tree
而LSM-tree工作在磁碟傳輸速率的級別上,可以更好地擴充套件到更大的資料規模上,保證一個比
較一致的插入速率,因為它會使用日誌檔案和一個記憶體儲存結構,將隨機寫操作轉化為順序
寫。
在傳輸等量資料場景下,隨機寫I/O的時延大部分花費在了seek操作上,資料庫對磁碟進行零
碎的隨機寫會產生多次seek操作;而順序存取只需一次seek操作,便可以傳輸大量資料,針對
批量寫入大量資料的場景,順序寫比隨機寫具有明顯的優勢。
The Log-Structured Merge-Tree(LSM-Tree)的一個重要思想就是通過使用某種演算法,該演算法會對
索引變更進行延遲及批量處理,並通過一種類似於歸併排序的方式高效地將更新遷移到磁碟,
進行批量寫入,利用磁碟順序寫效能遠好於隨機寫這一特點,將隨機寫轉變為順序寫,從而保
證對磁碟的操作是順序的,以提升寫效能,同時建立索引,以獲取較快的讀效能,在讀和寫性
能之間做一個平衡。
插入100億條資料,每條資料大約100kb。
比如更新1%的資料,如果用B-tree,用時100天
如果用LSM-TREE,用時1天。
LSM-Tree原理
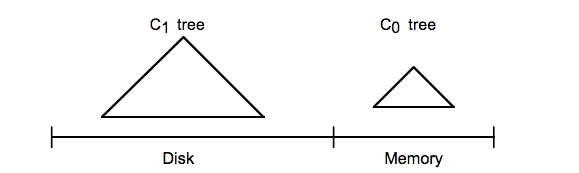
c0 Tree 是存在記憶體的的樹結構,可以是(B-樹,B+樹,二叉樹,跳躍表)
c1 Tree 是存在磁碟上的檔案(本身也是一個樹結構)
寫入或者更新某條記錄時,首先會預寫日誌,用於資料寫入失敗時進行資料恢復。之後
該條記錄會被插入到駐留在記憶體中的C0樹,在符合某個條件的時候從被移到磁碟上的C1樹
中。
C0樹不一定要具有一個類B-樹的結構。HBase中採用了執行緒安全的ConcurrentSkipListMap
資料結構。
向記憶體中的C0樹插入一個條目速度是非常快的,因為操作不會產生磁碟I/O開銷。然而用於
C0的記憶體成本要遠高於磁碟,通常做法是限制它的大小。採用一種有效的方式來將記錄遷移
到駐留在更低成本的儲存裝置上的C1樹中。為了實現這個目的,在當C0樹因插入操作而達到
接近某個上限的閾值大小時,就會啟動一個rolling merge過程,來將某些連續的記錄段(保
證是順序寫)從C0樹中刪除,並merge到磁碟上的C1樹中。

磁碟上的C1樹是一個類似於B-Tree的資料結構,但是它是為順序性的磁碟訪問優化過的。
HBase的實現
MemStore
MemStore是HBase中C0的實現,向HBase中寫資料的時候,首先會寫到記憶體中的
MemStore,當達到一定閥值之後,flush(順序寫)到磁碟,形成新的StoreFile(HFile),最後
多個StoreFile(HFile)又會進行Compact。
memstore內部維護了一個數據結構:ConcurrentSkipListMap,資料儲存是按照RowKey排
好序的跳躍列表。跳躍列表的演算法有同平衡樹一樣的漸進的預期時間邊界,並且更簡單、更快
速和使用更少的空間。
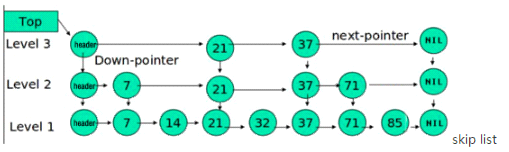
HFile
HFlile是lsm tree中C1的實現
BloomFilter
背景說明
Hash 函式在計算機領域,尤其是資料快速查詢領域,加密領域用的極廣。
其作用是將一個大的資料集對映到一個小的資料集上面(這些小的資料集叫做雜湊值,或者雜湊
值)。
Hash table(散列表,也叫雜湊表),是根據雜湊值(Key value)而直接進行訪問的資料結構。也就是
說,它通過把雜湊值對映到表中一個位置來訪問記錄,以加快查詢的速度。下面是一個典型的示意
圖:

但是這種簡單的Hash Table存在一定的問題,就是Hash衝突的問題。假設 Hash 函式是良好的,如果
我們的位陣列長度為 m 個點,那麼如果我們想將衝突率降低到例如 1%, 這個散列表就只能容納 m *
1% 個元素。顯然這就不叫空間有效了(Space-efficient)。
Bloom Filter概述
Bloom Filter是1970年由布隆(Burton Howard Bloom)提出的。它實際上是一個很長的二進位制向
量和一系列隨機對映函式(Hash函式)。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的
優點是空間效率和查詢時間都遠遠超過一般的演算法。Bloom Filter廣泛的應用於各種需要查詢的場合
中,如:
Google 著名的分散式資料庫 Bigtable 使用了布隆過濾器來查詢不存在的行或列,以減少磁碟查詢的
IO次數。
在很多Key-Value系統中也使用了布隆過濾器來加快查詢過程,如 Hbase,Accumulo,Leveldb,一
般而言,Value 儲存在磁碟中,訪問磁碟需要花費大量時間,然而使用布隆過濾器可以快速判斷某個
Key對應的Value是否存在,因此可以避免很多不必要的磁碟IO操作,只是引入布隆過濾器會帶來一定
的記憶體消耗。
Bloom Filter 原理
如果想判斷一個元素是不是在一個集合裡,一般想到的是將所有元素儲存起來,然後通過比較確定。
連結串列,樹等等資料結構都是這種思路. 但是隨著集合中元素的增加,我們需要的儲存空間越來越大,檢
索速度也越來越慢。
一個Bloom Filter是基於一個m位的位向量(b1,…bm),這些位向量的初始值為0。另外,還有一系
列的hash函式(h1,…hk),這些hash函式的值域屬於1~m。下圖是一個bloom filter插入x,y,z並判斷
某個值w是否在該資料集的示意圖:
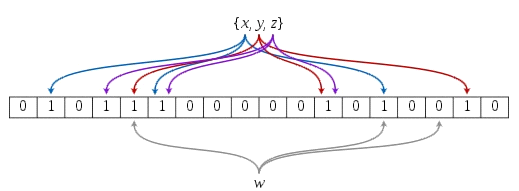
但是布隆過濾器的缺點和優點一樣明顯。誤算率(False Positive)是其中之一。隨著存入的元素數量
增加,誤算率隨之增加。但是如果元素數量太少,則使用散列表足矣。
總結:Bloom Filter 通常應用在一些需要快速判斷某個元素是否屬於集合,但是並不嚴格要求100%正
確的場合。此外,引入布隆過濾器會帶來一定的記憶體消耗。