
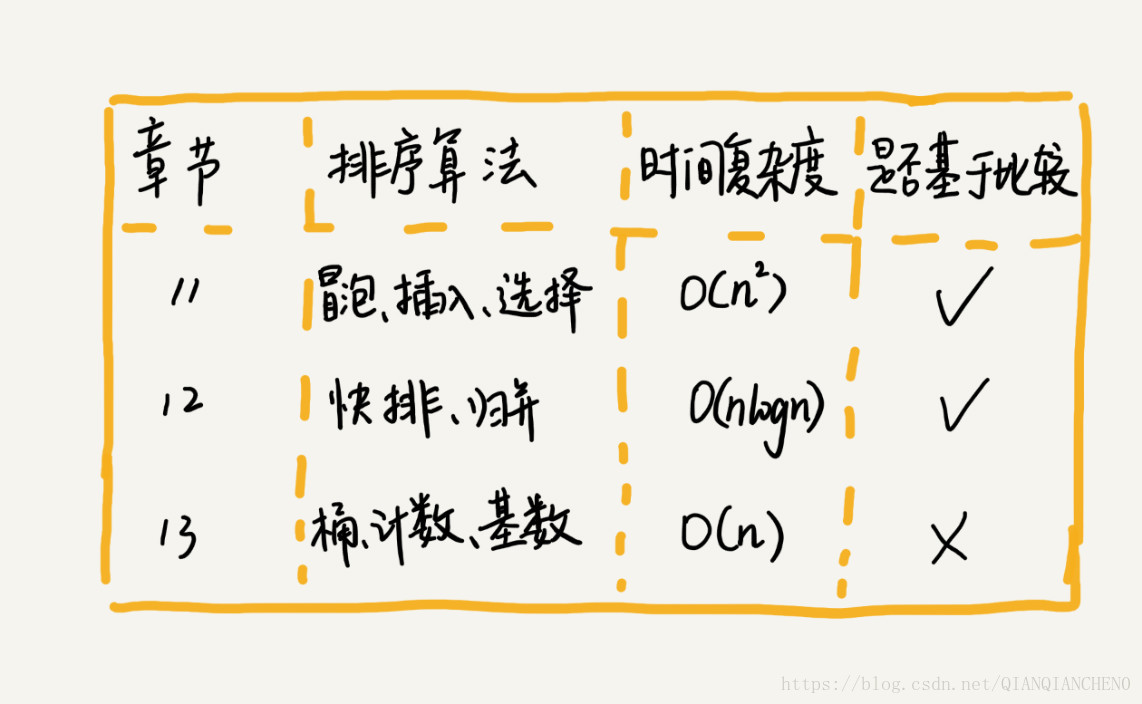
11 排序1:為什麼插入排序比氣泡排序更受歡迎?
問題:插入排序和氣泡排序的時間複雜度相同,都是 O(n2),在實際的軟體開發裡,為什麼我們更傾向於使用插入排序演算法而不是氣泡排序演算法呢?
一、如何分析一個“排序演算法”?
(一)排序演算法的執行效率
1、最好情況、最壞情況、平均情況時間複雜度
還要說出最好、最壞時間複雜度對應的要排序的原始資料是什麼樣的。
為什麼要區分這三種時間複雜度?1 為了好對比;2 對於要排序的資料,有的接近有序,有的完全無需。有序度不用的資料,對於排序的執行時間有影響,我們要知道排序演算法在不同資料下的效能表現。
2、時間複雜度的係數、常數、低階
時間複雜度反應的是資料規模n很大的時候的一個增長趨勢,所以它表示的時候會忽略係數、常數、低階。但在實際軟體開發中,排序的可能是10、100、1000個這樣規模小的資料。
3、比較次數和交換(或移動)次數
(二)排序演算法的記憶體消耗
原地排序(Sorted in place).原地排序演算法,特指空間複雜度時O(1)的排序演算法。
(三)排序演算法的穩定性
如果待排序的序列中存在值相等的元素,經過排序之後,相等元素之間原有的先後順序不變。

二、氣泡排序Bubble Sort
氣泡排序只會操作相鄰的兩個資料。每次冒泡操作都會對相鄰的兩個元素進行比較,看是否滿足大小關係要求。如果不滿足就讓他們互換。一次冒泡會讓至少一個元素移動到它應該的位置,重複n次,就完成了n個數據的排序工作。
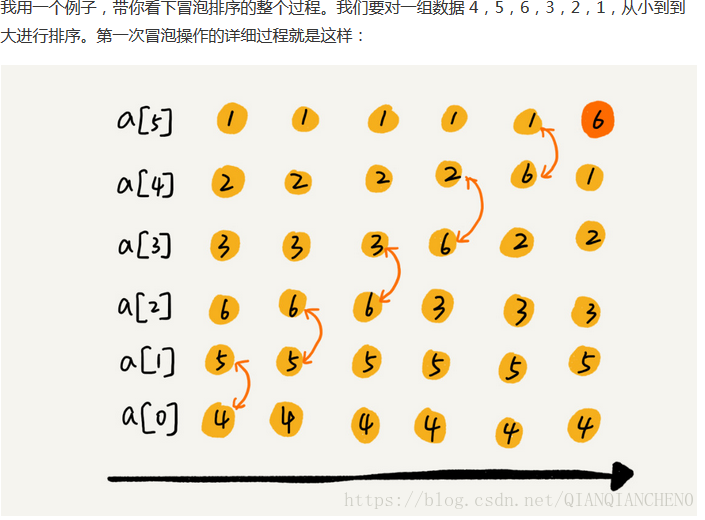
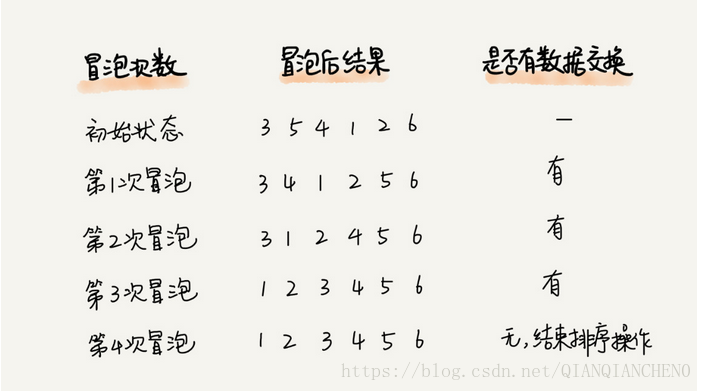
// 氣泡排序,a 表示陣列,n 表示陣列大小 public void bubbleSort(int[] a, int n) { if (n <= 1) return; for (int i = 0; i < n; ++i) { // 提前退出冒泡迴圈的標誌位 boolean flag = false; for (int j = 0; j < n - i - 1; ++j) { if (a[j] > a[j+1]) { // 交換 int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; flag = true; // 表示有資料交換 } } if (!flag) break; // 沒有資料交換,提前退出 } }
1、氣泡排序是原地排序演算法麼?
冒泡的過程只涉及相鄰資料的交換操作,只需要常量級的臨時空間,所以它的空間複雜度為O(1),是一個原地排序演算法。
2、氣泡排序是穩定的排序演算法麼?
在氣泡排序中,只有交換才可以改變兩個元素的前後順序。為了保證氣泡排序演算法的穩定性,當有相鄰的兩個元素大小相等的時候,我們不做交換,相同大小的資料在排序前後不會改變順序,所以氣泡排序是穩定的排序演算法。
3、氣泡排序的時間複雜度是多少?
最好情況 1,2,3,4,5,6 1次冒泡 時間複雜度 O(n)
最壞情況 6,5,4,3,2,1 6次冒泡 時間複雜度 O(n2)
平均時間複雜度就是加權平均期望時間複雜度,分析的時候要結合概率論的知識。
對於包含n個數據的陣列,這n個數據就有n!中排列方式。不同的排列方式,氣泡排序執行的時間肯定是不同的。如果用概率論方法定量分析平均時間複雜度,涉及的數學推理和極端就會很複雜。還有一種思路,通過“有序度”和“逆序度”這兩個概念來進行分析。
“有序度”是陣列中具有有序關係的元素對的個數。有序元素用數學表示式表示是這樣:
有序元素對:a[i] <= a[j], 如果 i < j。

逆序元素對:a[i] > a[j], 如果 i < j。
逆序度 = 滿有序度 - 有序度
排序的過程就是增加有序度,減少逆序度的過程,最後達到滿有序度
氣泡排序包含兩個操作原子,比較和交換。每交換一次,有序度就加1。不管演算法
怎麼改進,交換次數總是確定的,即為逆序度,也就是n*(n-1)/2-初始有序度。

對於包含n個數據的陣列進行氣泡排序,平均交換次數是多少呢?最壞情況下,初始狀態的有序度是0,所以要進行n*(n-1)/2次交換。最好情況,初始狀態的有序度是n*(n-1)/2,不需要進行交換。我們可以取中間值n*(n-1)/4,來表示初始有序度既不是很高也不是很低的平均情況。
換句話說,平均情況下,需要n*(n-1)/4次交換操作,比較操作肯定要比交換操作多,而複雜度的上限是O(n2),所以平均情況下的時間複雜度就是O(n2).
這個平均時間複雜度推導過程其實並不嚴格,但是很多時候很實用,畢竟概率論的定量分析太複雜,不太好用。快排時,還會用到。
三、插入排序 Insertion Sort
首先,我們將陣列中的資料分為兩個區間,已排序區間和未排序區間。初始已排序區間只有一個元素,就是陣列的第一個元素。插入演算法的核心思想是取未排序區間中的元素,在已排序區間中的元素,在已排序區間中找到合適的插入位置將其插入,並保證已排序區間資料一致有序。重複這個過程,直到未排序區間中元素為空,演算法結束。
插入排序也包好兩種操作,一是元素的比較,一是元素的移動。當我們需要將一個數據a插入到已排序區間時,需要拿a與已排序區間的元素依次比較大小,找到合適的插入位置。找到插入點之後,還需要將插入點之後的元素順序往後移動一位,這樣才能騰出位置給元素a插入。
對於不同的查詢插入點方法(從頭到尾、從尾到頭),元素的比較次數是有區別的。但對於一個給定的初始序列,移動操作的次數總是固定的,就等於逆序度。
為什麼說移動次數就等等於逆序度呢?滿有序度是n*(n-1)/2=15,初始序列的有序度是5,所以逆序度是10。插入排序中,資料移動的個數總和也等於10 = 3+3+4.
// 插入排序,a 表示陣列,n 表示陣列大小
public void insertionSort(int[] a, int n) {
if (n <= 1) return;
for (int i = 1; i < n; ++i) {
int value = a[i];
int j = i - 1;
// 查詢插入的位置
for (; j >= 0; --j) {
if (a[j] > value) {
a[j+1] = a[j]; // 資料移動
} else {
break;
}
}
a[j+1] = value; // 插入資料
}
}
1、插入排序是原地排序演算法麼?
不需要額外的儲存空間,所以空間複雜度是O(1),是一個原地排序演算法。
2、插入排序是穩定的排序演算法麼? 是
3、插入排序的時間複雜度是多少?
最好 O(n)
最壞 O(n2)
在陣列中插入一個數據的平均時間複雜度是 O(n).所以對於插入排序來說,每次插入操作都相當於在陣列中插入一個數據,迴圈執行n次插入操作,所以平均時間複雜度為O(n2).
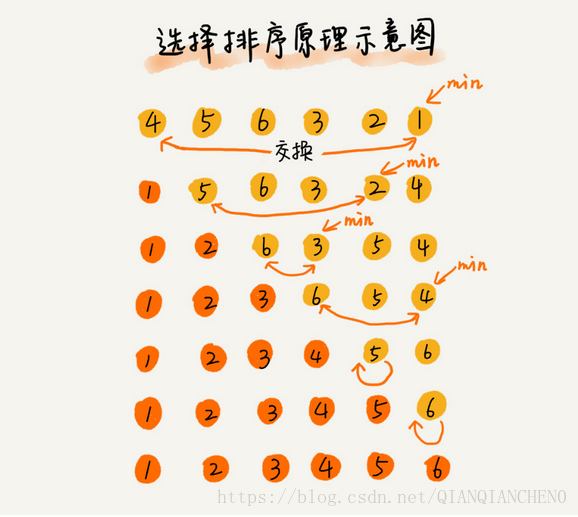
四、選擇排序 Selection Sort
選擇排序演算法的實現思路類似插入排序,也分已排序區間和未排序區間。但是選擇排序每次會從未排序區間中找到最小的元素,將其放到已排序區間的末尾。
1、選擇排序是原地排序演算法麼?是一個原地排序演算法。
2、選擇排序是穩定的排序演算法麼?不是,選擇排序每次都要找剩餘未排序元素中的最小值,並和前面的元素交換位置,這樣破壞了穩定性。正是因此,相對於氣泡排序和插入排序,選擇排序稍微遜色。
3、選擇排序的時間複雜度是多少? 最好、最壞和平均情況時間複雜度都是O(n2).
五、問題:插入排序和氣泡排序的時間複雜度相同,都是 O(n2),在實際的軟體開發裡,為什麼我們更傾向於使用插入排序演算法而不是氣泡排序演算法呢?
氣泡排序和插入排序不管怎麼優化,元素移動的次數是固定值,是原始陣列的逆序度。
但是從程式碼實現上,氣泡排序的資料交換要比插入排序的資料移動要複雜,氣泡排序需要3個賦值操作,而插入排序只需要1個
氣泡排序中資料的交換操作:
氣泡排序中資料的交換操作:
if (a[j] > a[j+1]) { // 交換
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
flag = true;
}
插入排序中資料的移動操作:
if (a[j] > value) {
a[j+1] = a[j]; // 資料移動
} else {
break;
}
我們把執行一個賦值語句的時間粗略記為單位時間 unit_time,然後分別用氣泡排序和插入排序對同一個逆序度是K的陣列進行排序。用氣泡排序,需要K次交換操作,每次需要3個賦值語句,所以交換操作總耗時是3*K單位時間。而插入排序中資料移動操作只需要K個單位時間。