
吳恩達機器學習個人筆記(七)-聚類
聚類屬於無監督學習。在之前的學習中,都是監督學習。監督學習與無監督學習的最大區別為訓練資料集的特點,在監督學習中,訓練集是有標籤的,我們根據這些有標籤的資料,訓練出模型,輸出相應的值。而在無監督學習中,我們的資料集沒有標籤,我們需要使用機器學習演算法尋找出資料集中的內在結構。無監督學習的資料集如下所示

訓練的資料集可以寫成只有一直到
,沒有任何的標籤
。上圖中的資料可以看作兩個分開的點集(稱為簇),能找出這些點集的演算法就稱為聚類演算法。
1k-均值演算法
k-均值演算法是最普及的演算法,該演算法接受一個未標記的資料集,然後將資料集聚類成不同的類。k-均值演算法是一種迭代演算法,假設我們將資料聚類成n個組,那麼步驟如下:
首先隨機選擇K個隨機點,稱為聚類中心(cluster centroids)。對於資料集中的每個資料,計算他們與這些K個聚類中心的距離,然後將其與之關聯起來(可認為每個組即為一個類,關聯即屬於該類),將所有與這個聚類中心關聯的點歸為一類。
下一步是重新設定聚類中心,計算每一個組的平均值,將聚類中心的座標移動到平均值的位置。
然後不斷進行這兩個步驟的迭代,直到聚類中心點不再變化。
迭代10次,用來表示聚類中心,用
來儲存與第
個例項資料最近的聚類中心的索引,k-均值演算法的虛擬碼如下所示:
Repeat{
for
:=index (from 1 to
) of cluster centroid closest to
for =1 to
:=average (mean) of points assigned to cluster
}
就如上述所講,該演算法分為兩個步驟,第一個for迴圈是計算訓練集中每一個樣例,看其屬於哪個類。第二個for迴圈是聚類中心的移動,即計算屬於該組的點的平均值。
K-均值演算法也可以便利的將資料分為不同的組,即使在沒有非常明顯區分的組群的情況也可以。如下圖所示,下圖所示的資料集包含身高和體重兩項特徵構成的,利用K-均值

2優化目標
我們之前的機器學習都有一個優化目標,聚類演算法也一樣。K-均值最小化的問題就是要最小化所有的資料點與其所關聯的聚類中心點之間的距離之和,因此k-均值的代價函式(又稱畸變函式 Distortion function)為
其中上式的 代表與
最近的聚類中心點。優化目標便是找出使得代價函式最小的
和
之前的k-均值的迭代演算法第一個迴圈是用於減小
引起的代價(也就是將訓練資料集歸到某個組),第二個迴圈則是用於減小
引起的代價。迭代的過程一定是每一次迭代都是在減小代價函式,不然就會出錯。
3隨機初始化
之前在執行k-均值演算法之前,我們一開始是選擇隨機的聚類中心,其實k-均值演算法的效果與聚類中心有很大的關係。在執行k-均值演算法之前,我們要隨機的初始化所有的聚類中心。步驟如下
1.我們應該選擇,即聚類中心點的個數要小於所有訓練集例項的數量
2.隨機選擇個訓練例項,然後令
個聚類中心分別與這
個訓練例項相等。也就是隨機選擇
個訓練集中的資料作為聚類中心。
如果執行上訴步驟,那麼就會出現問題。我們隨機選的聚類中心不好怎麼辦?如下所示
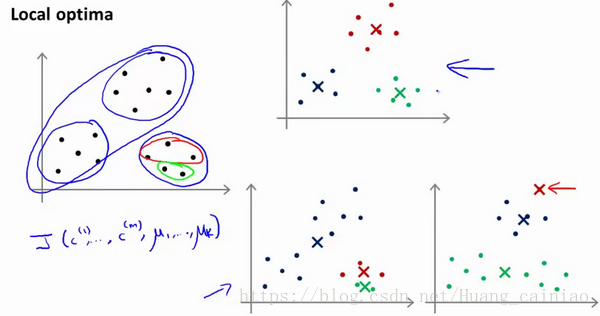
上圖可以看出,隨機選擇不同的聚類中心就會出現不同的結果,結果有符合預期的也有不符合的。為了解決上訴問題,我們需要多次執行K-均值演算法,每次執行之前都進行隨機初始化,最後再比較多次執行的結果,選擇代價函式最下的那次。但是這種方法在K較小時是可行的(2-10),但是如果K較大,那麼這麼做不僅效率低,而且也沒有較明顯的改善。
4選擇聚類數
其實選擇聚類數沒有真正的標準,通常是針對不同的問題,人工進行選擇。選擇的時候我們考慮使用K-均值演算法聚類的目標是什麼,然後根據這個目標進行選擇聚類的個數。
當選擇聚類數目時,有可能會用到一個方法叫做"肘部法則"。關於“肘部法則”,我們所需要的時改變K值,也就是聚類的數目,然後算出選擇這K個聚類的代價函式。
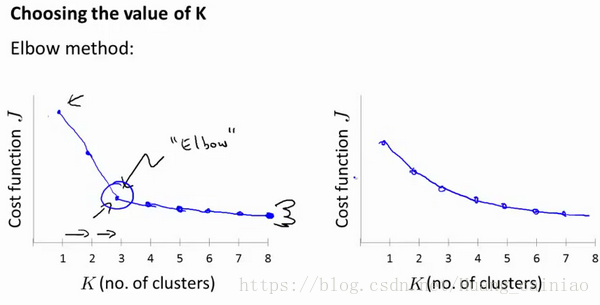
你會得到上述的左邊的圖,在某個點中(其實可以稱為拐點),代價函式會劇烈的下降,然後變化的很緩慢,所以選擇該點作為聚類數目K。但是實際值大部分情況是上述右邊的圖,那麼這時候肘部法則就不管用了.。所以實際過程中還是人工選擇具體的聚類數目。
5聚類相關資料
1相識度/距離計算
(1). 閔可夫斯基距離Minkowski/(其中歐式距離:)
(2). 傑卡德相似係數(Jaccard):
(3). 餘弦相似度(cosine similarity):
n 維向量x 和y 的夾角記做θ ,根據餘弦定理,其餘弦值為:
2.聚類的衡量指標
(1). 均一性:p
類似於精確率,一個簇中只包含一個類別的樣本,則滿足均一性。其實也可以認為就是正確率(每個聚簇中正確分類的樣本 數佔該聚簇總樣本數的比例和)
(2). 完整性:r
類似於召回率,同類別樣本被歸類到相同簇中,則滿足完整性;(每個聚簇中正確分類的樣本數佔該型別的總樣本數比例的和)
(3). 輪廓係數
樣本i 的輪廓係數:
簇內不相似度:計算樣本 到同簇其它樣本的平均距離為
,應儘可能小。
簇間不相似度:計算樣本 到其它簇
的所有樣本的平均距離
,應儘可能大。
輪廓係數值 越接近1表示樣本
聚類越合理,越接近-1,表示樣本
應該分類到另外的簇中,近似為0,表示樣本
應該在邊界上;所有樣本的 的均值
被成為聚類結果的輪廓係數。