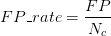效能度量:準確率(Precision)、召回率(Recall)、F值(F-Measure);P-R曲線;ROC;AUC
reference:https://blog.csdn.net/qq_29462849/article/details/81053135
資料探勘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。
在介紹指標前必須先了解“混淆矩陣”:
混淆矩陣
True Positive(真正,TP):將正類預測為正類數
True Negative(真負,TN):將負類預測為負類數
False Positive(假正,FP):將負類預測為正類數誤報 (Type I error)
False Negative(假負,FN):將正類預測為負類數→漏報 (Type II error)

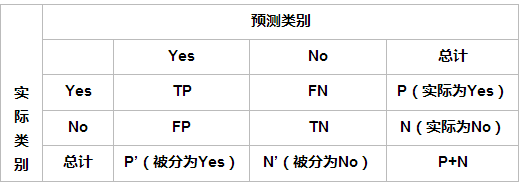
1、準確率(Accuracy)
準確率(accuracy)計算公式為:
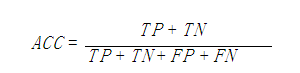
注:準確率是我們最常見的評價指標,而且很容易理解,就是被分對的樣本數除以所有的樣本數,通常來說,正確率越高,分類器越好。
準確率確實是一個很好很直觀的評價指標,但是有時候準確率高並不能代表一個演算法就好。比如某個地區某天地震的預測,假設我們有一堆的特徵作為地震分類的屬性,類別只有兩個:0:不發生地震、1:發生地震。一個不加思考的分類器,對每一個測試用例都將類別劃分為0,那那麼它就可能達到99%的準確率,但真的地震來臨時,這個分類器毫無察覺,這個分類帶來的損失是巨大的。為什麼99%的準確率的分類器卻不是我們想要的,因為這裡資料分佈不均衡,類別1的資料太少,完全錯分類別1依然可以達到很高的準確率卻忽視了我們關注的東西。再舉個例子說明下。在正負樣本不平衡的情況下,準確率這個評價指標有很大的缺陷。
2、錯誤率(Error rate)
錯誤率則與準確率相反,描述被分類器錯分的比例,
error rate = (FP+FN)/(TP+TN+FP+FN),對某一個例項來說,分對與分錯是互斥事件,所以accuracy =1 - error rate。
3、靈敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分對的比例,衡量了分類器對正例的識別能力。
4、特效度(specificity )
specificity = TN/N,表示的是所有負例中被分對的比例,衡量了分類器對負例的識別能力。
5、精確率、精度(Precision)
精確率(precision)定義為:
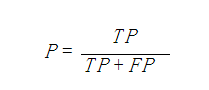
表示被分為正例的示例中實際為正例的比例。
6、召回率(recall)
召回率是覆蓋面的度量,度量有多個正例被分為正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率與靈敏度是一樣的。
7、綜合評價指標(F-Measure)
P和R指標有時候會出現的矛盾的情況,這樣就需要綜合考慮他們,最常見的方法就是F-Measure(又稱為F-Score)。
F-Measure是Precision和Recall加權調和平均:
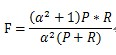
當引數α=1時,就是最常見的F1,也即
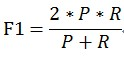
可知F1綜合了P和R的結果,當F1較高時則能說明試驗方法比較有效。
8、其他評價指標
計算速度:分類器訓練和預測需要的時間;
魯棒性:處理缺失值和異常值的能力;
可擴充套件性:處理大資料集的能力;
可解釋性:分類器的預測標準的可理解性,像決策樹產生的規則就是很容易理解的,而神經網路的一堆引數就不好理解,我們只好把它看成一個黑盒子。
下面來看一下ROC和PR曲線:
1、ROC曲線:
ROC(Receiver Operating Characteristic)曲線將偽陽性率(FPR)定義為 X 軸,真陽性率(TPR)定義為 Y 軸。這兩個值由上面四個值計算得到,公式如下:
TPR:在所有實際為陽性的樣本中,被正確地判斷為陽性之比率。TPR=TP/(TP+FN)
FPR:在所有實際為陰性的樣本中,被錯誤地判斷為陽性之比率。FPR=FP/(FP+TN),
ROC曲線下面的面積叫做AUC,如下圖所示:
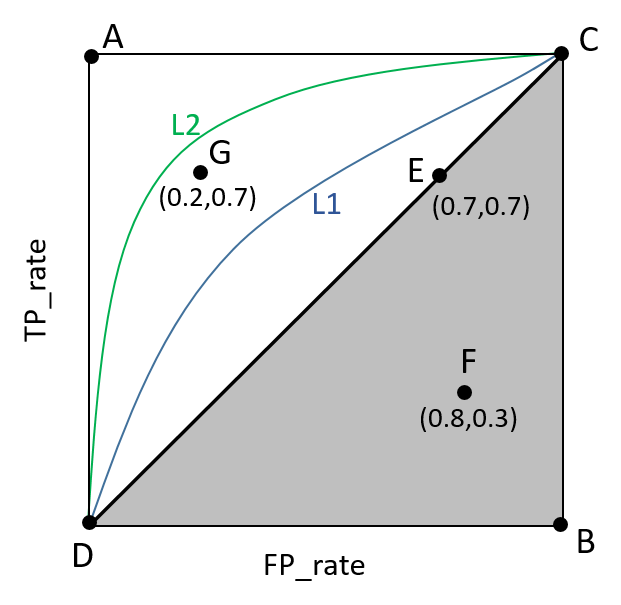
其中:
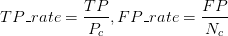
(1) 曲線與FP_rate軸圍成的面積(記作AUC)越大,說明效能越好,即圖上L2曲線對應的效能優於曲線L1對應的效能。即:曲線越靠近A點(左上方)效能越好,曲線越靠近B點(右下方)曲線效能越差。
(2)A點是最完美的performance點,B處是效能最差點。
(3)位於C-D線上的點說明演算法效能和random猜測是一樣的–如C、D、E點。位於C-D之上(即曲線位於白色的三角形內)說明演算法效能優於隨機猜測–如G點,位於C-D之下(即曲線位於灰色的三角形內)說明演算法效能差於隨機猜測–如F點。
(4)雖然ROC曲線相比較於Precision和Recall等衡量指標更加合理,但是其在高不平衡資料條件下的的表現仍然過於理想,不能夠很好的展示實際情況。
2、PR曲線:
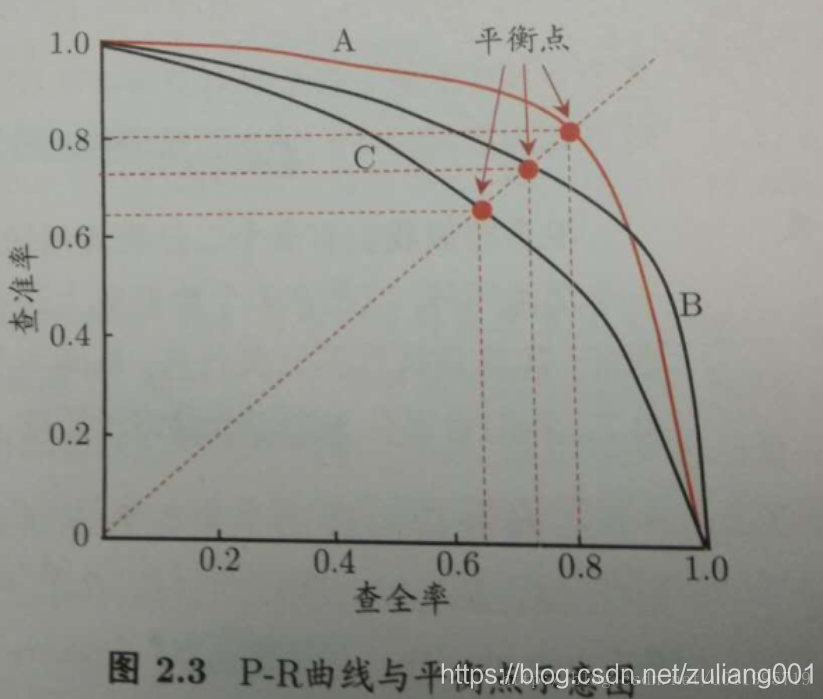
P-R曲線用來衡量分類器效能的優劣,橫軸為recall ,縱軸為precision,P-R曲線是如何衡量分類器效能的呢?
如圖,有三個分類器,A,B,C,若一個學習器的P-R曲線完全被另外一個學習器完全”包住”,則說後則效能優於前者。 如學習器A優於C,但是有交叉時,就要用平衡點(BEP)來衡量。平衡點即precision 等於 recall 時的值。那麼可以認為A優於B。
另外舉個例子(例子來自Paper:Learning from eImbalanced Data):
假設N_c >> P_c(即Negative的數量遠遠大於Positive的數量),若FP很大,即有很多N的sample被預測為P,因為