
ReLU啟用函式:簡單之美
導語
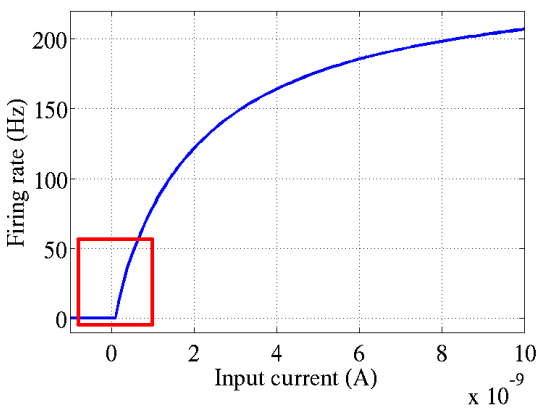
在深度神經網路中,通常使用一種叫修正線性單元(Rectified linear unit,ReLU)作為神經元的啟用函式。ReLU起源於神經科學的研究:2001年,Dayan、Abott從生物學角度模擬出了腦神經元接受訊號更精確的啟用模型,如下圖:
簡單之美
首先,我們來看一下ReLU啟用函式的形式,如下圖:
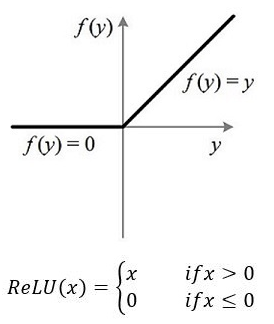
那麼問題來了:這種稀疏性有何作用?換句話說,我們為什麼需要讓神經元稀疏?不妨舉栗子來說明。當看名偵探柯南的時候,我們可以根據故事情節進行思考和推理,這時用到的是我們的大腦左半球;而當看蒙面唱將時,我們可以跟著歌手一起哼唱,這時用到的則是我們的右半球。左半球側重理性思維,而右半球側重感性思維。也就是說,當我們在進行運算或者欣賞時,都會有一部分神經元處於啟用或是抑制狀態,可以說是各司其職。再比如,生病了去醫院看病,檢查報告裡面上百項指標,但跟病情相關的通常只有那麼幾個。與之類似,當訓練一個深度分類模型的時候,和目標相關的特徵往往也就那麼幾個,因此通過ReLU實現稀疏後的模型能夠更好地挖掘相關特徵,擬合訓練資料。
此外,相比於其它啟用函式來說,ReLU有以下優勢:對於線性函式而言,ReLU的表達能力更強,尤其體現在深度網路中;而對於非線性函式而言,ReLU由於非負區間的梯度為常數,因此不存在梯度消失問題(Vanishing Gradient Problem),使得模型的收斂速度維持在一個穩定狀態。這裡稍微描述一下什麼是梯度消失問題:當梯度小於1時,預測值與真實值之間的誤差每傳播一層會衰減一次,如果在深層模型中使用sigmoid作為啟用函式,這種現象尤為明顯,將導致模型收斂停滯不前。