
深度學習常用啟用函式之— Sigmoid & ReLU & Softmax
阿新 • • 發佈:2019-01-04
1. 啟用函式
- Rectified Linear Unit(ReLU) - 用於隱層神經元輸出
- Sigmoid - 用於隱層神經元輸出
- Softmax - 用於多分類神經網路輸出
- Linear - 用於迴歸神經網路輸出(或二分類問題)
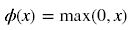
Sigmoid函式計算如下:
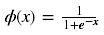
Softmax函式計算如下:
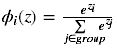
Softmax啟用函式只用於多於一個輸出的神經元,它保證所以的輸出神經元之和為1.0,所以一般輸出的是小於1的概率值,可以很直觀地比較各輸出值。
2. 為什麼選擇ReLU?
深度學習中,我們一般使用ReLU作為中間隱層神經元的啟用函式,AlexNet中提出用ReLU來替代傳統的啟用函式是深度學習的一大進步。我們知道,sigmoid函式的影象如下: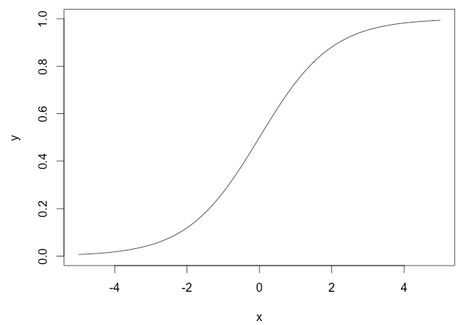
而一般我們優化引數時會用到誤差反向傳播演算法,即要對啟用函式求導,得到sigmoid函式的瞬時變化率,其導數表示式為:
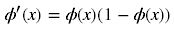
對應的圖形如下:
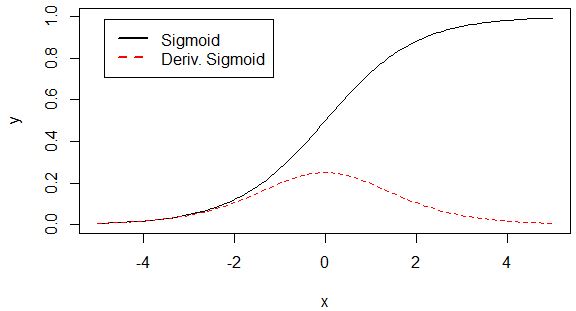
由圖可知,導數從0開始很快就又趨近於0了,易造成“梯度消失”現象,而ReLU的導數就不存在這樣的問題,它的導數表示式如下:
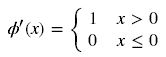
Relu函式的形狀如下(藍色):
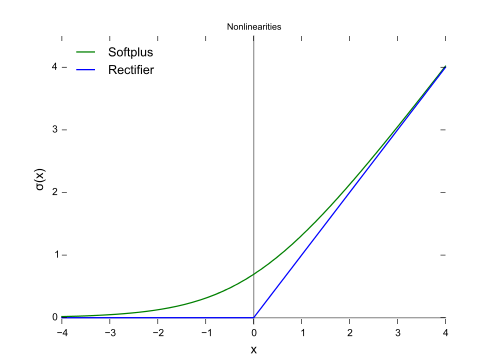
對比sigmoid類函式主要變化是:1)單側抑制 2)相對寬闊的興奮邊界 3)稀疏啟用性。這與人的神經皮層的工作原理接近。
3. 為什麼需要偏移常量?
通常,要將輸入的引數通過神經元后對映到一個新的空間中,我們需要對其進行加權和偏移處理後再啟用,而不僅僅是上面討論啟用函式那樣,僅對輸入本身進行啟用操作。比如sigmoid啟用神經網路的表示式如下: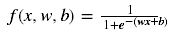
x是輸入量,w是權重,b是偏移量(bias)。這裡,之所以會討論sigmoid函式是因為它能夠很好地說明偏移量的作用。
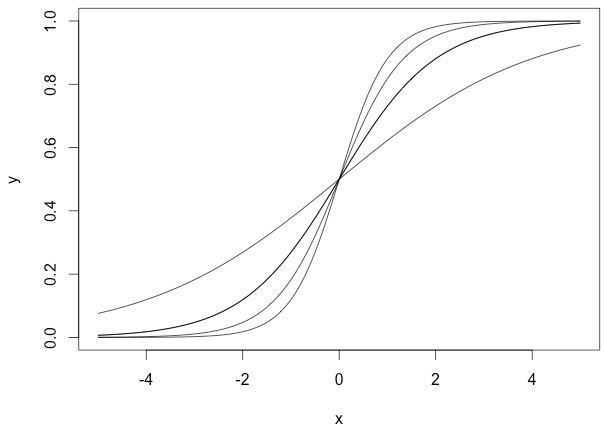
上面的曲線是由下面這幾組引數產生的:
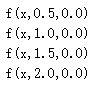
我們沒有使用偏移量b(b=0),從圖中可以看出,無論權重如何變化,曲線都要經過(0,0.5)點,但實際情況下,我們可能需要在x接近0時,函式結果為其他值。下面我們改變偏移量b,它不會改變曲線大體形狀,但是改變了數值結果:
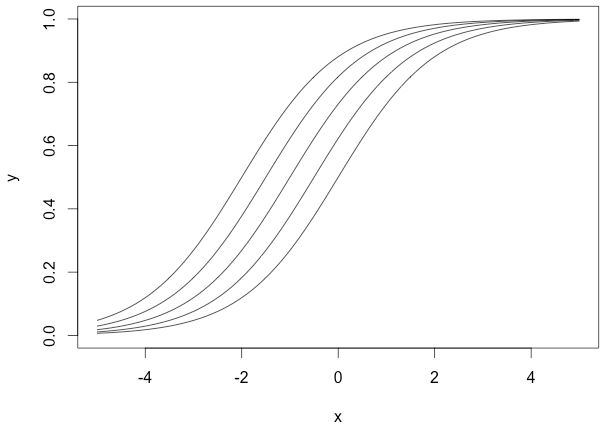
上面幾個sigmoid曲線對應的引數組為:

這裡,我們規定權重為1,而偏移量是變化的,可以看出它們向左或者向右移動了,但又在左下和右上部位趨於一致。 當我們改變權重w和偏移量b時,可以為神經元構造多種輸出可能性,這還僅僅是一個神經元,在神經網路中,千千萬萬個神經元結合就能產生複雜的輸出模式。 放一個福利 ===> 深度學習網紅Siraj Raval關於如何選擇啟用函式的viedo。