
FP-growth 頻繁項集計算方法
自學關聯分析的時候,發現樹和各種部落格上對FP-growth演算法的介紹中主要集中在FP-tree的構建上,而對FP-tree的挖掘,稍微有些不清楚,特別是在獲取頻繁項集的具體做法的介紹有些模糊。
《機器學習實戰》中對從FP-tree中抽取頻繁項集的三個基本步驟介紹如下:
(1)從FP-tree中獲得條件模式基。
(2)利用條件模式基,構建一個條件FP樹。
(3)迭代重複步驟(1)和步驟(2),直到樹包含一個元素項為止。
在此沒有介紹如何在FP條件樹中獲取頻繁項集,韓家煒老師的《資料探勘》也沒有詳細介紹,並且沒有明確的例子。在此我將搜尋資料過程中的遇到的一個圖片,其是基於FP-tree獲取頻繁項集的詳細過程記錄。通過這個圖片,對具體的過程有了更好的理解。
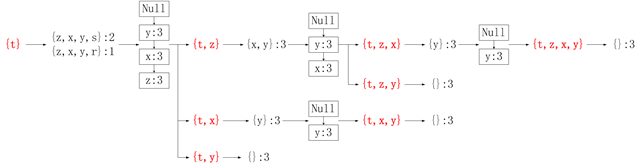
相關推薦
FP-growth 頻繁項集計算方法
自學關聯分析的時候,發現樹和各種部落格上對FP-growth演算法的介紹中主要集中在FP-tree的構建上,而對FP-tree的挖掘,稍微有些不清楚,特別是在獲取頻繁項集的具體做法的介紹有些模糊。 《機器學習實戰》中對從FP-tree中抽取頻繁項集的三個基本步驟介紹如下: (1)從FP-tr
python關聯分析 __機器學習之FP-growth頻繁項集演算法
FP-growth演算法 專案背景/目的 對於廣告投放而言,好的關聯會一定程度上提高使用者的點選以及後續的諮詢成單 對於產品而言,關聯分析也是提高產品轉化的重要手段,也是大多商家都在做的事情,尤其是電商平臺 曾經我用SPSS Modeler做過Apriori關聯分析模型,也能
機器學習之FP-growth頻繁項集演算法
FP-growth演算法專案背景/目的對於廣告投放而言,好的關聯會一定程度上提高使用者的點選以及後續的諮詢成單 對於產品而言,關聯分析也是提高產品轉化的重要手段,也是大多商家都在做的事情,尤其是電商平臺 曾經我用SPSS Modeler做過Apriori關聯分析模型,也能滿足需求,但是效果自然是不及pyt
機器學習之FP-growth頻繁項集算法
算法 image -o 做的 mine 關聯 RoCE 節點 reat FP-growth算法項目背景/目的對於廣告投放而言,好的關聯會一定程度上提高用戶的點擊以及後續的咨詢成單 對於產品而言,關聯分析也是提高產品轉化的重要手段,也是大多商家都在做的事情,尤其是電商平臺 曾
python關聯分析__機器學習之FP-growth頻繁項集演算法
FP-growth演算法 專案背景/目的 對於廣告投放而言,好的關聯會一定程度上提高使用者的點選以及後續的諮詢成單 對於產品而言,關聯分析也是提高產品轉化的重要手段,也是大多商家都在做的事情,尤其是電商平臺 曾經我用SPSS Modeler做過Apriori關聯
R_Studio(關聯)Apriori演算法尋找頻繁項集的方法
使用Apriori演算法尋找頻繁項集 #匯入arules包 install.packages("arules") library ( arules ) setwd('D:\\data') Gary<-
手推FP-growth (頻繁模式增長)算法------挖掘頻繁項集
att 相同 事務 支持 apr 一次 多個 什麽 統計 一.頻繁項集挖掘為什麽會出現FP-growth呢? 原因:這得從Apriori算法的原理說起,Apriori會產生大量候選項集(就是連接後產生的),在剪枝時,需要掃描整個數據庫(就是給出的數據),通過模式匹配檢查候
第12章:使用FP-growth演算法高效發現頻繁項集
原理:通過構建FP樹,在FP樹中發現頻繁項集。如下圖所示。 由圖可知FP樹包含頭指標,父節點,節點的名字,節點的值,節點連結值(虛線),節點的孩子節點,因此構建類定義樹結構,如下所示: class treeNode: d
機器學習實戰(十一)FP-growth(頻繁項集)
目錄 0. 前言 學習完機器學習實戰的FP-growth,簡單的做個筆記。文中部分描述屬於個人消化後的理解,僅供參考。 本篇綜合了先前的文章,如有不理解,可參考: 如果這篇文章對你有一點小小的幫助,請給個關注喔~我會非常開心的~ 0. 前
Apriori關聯分析與FP-growth挖掘頻繁項集
1 問題引入 在去雜貨店買東西的過程,實際上包含了機器學習的應用,這包括物品的展示方式、優惠券等。通過檢視哪些商品經常被一起購買,商店可以瞭解使用者的購買習慣,然後將經常被一起購買的物品擺放在一起,有
頻繁項集挖掘之apriori和fp-growth
Apriori和fp-growth是頻繁項集(frequent itemset mining)挖掘中的兩個經典演算法,主要的區別在於一個是廣度優先的方式,另一個是深度優先的方式,後一種是基於前一種效率較低的背景下提出來的,雖然都是十幾年前的,但是理解這兩個演算法對資料探勘
程式碼註釋:機器學習實戰第12章 使用FP-growth演算法來高效發現頻繁項集
寫在開頭的話:在學習《機器學習實戰》的過程中發現書中很多程式碼並沒有註釋,這對新入門的同學是一個挑戰,特此貼出我對程式碼做出的註釋,僅供參考,歡迎指正。 #coding:gbk #作用:FP樹中節點的類定義 #輸入:無 #輸出:無 class treeNode:
第11章:使用Apriori演算法進行關聯分析(計算頻繁項集)
目的:找到資料集中事務的關係,如超市中經常一起出現的物品集合,想找到支援度超過0.8的所有項集 概念: 頻繁項集:指經常出現在一起的物品集合; 關聯規則:指兩個物品之間可能存在很強的關係,如一個人買了什麼之後很大可能會買另一種東西; 支援度:資料集中包含該項集的記錄所佔的比例;保
海量資料探勘MMDS week2: 頻繁項集挖掘 Apriori演算法的改進:基於hash的方法
海量資料探勘Mining Massive Datasets(MMDs) -Jure Leskovec courses學習筆記之關聯規則Apriori演算法的改進:基於hash的方法:PCY演算法, Multistage演算法, Multihash演算法 Apriori演
海量資料探勘MMDS week2: 頻繁項集挖掘 Apriori演算法的改進:非hash方法
海量資料探勘Mining Massive Datasets(MMDs) -Jure Leskovec courses學習筆記之關聯規則Apriori演算法的改進:非hash方法 - 大資料集下的頻繁項集:挖掘隨機取樣演算法、SON演算法、Toivonen演算法 Apri
機器學習實戰(Machine Learning in Action)學習筆記————08.使用FPgrowth演算法來高效發現頻繁項集
機器學習實戰(Machine Learning in Action)學習筆記————08.使用FPgrowth演算法來高效發現頻繁項集關鍵字:FPgrowth、頻繁項集、條件FP樹、非監督學習作者:米倉山下時間:2018-11-3機器學習實戰(Machine Learning in Action,@autho
講講購物籃演算法中的一個核心函式——頻繁項集的選擇
購物籃演算法想必大家並不陌生,隨便翻開任何一本資料探勘的書,開篇都會講牛奶和啤酒的故事,而購物籃演算法中有一個很重要的演算法是Aprioi演算法,演算法詳解可見如下連結。 https://blog.csdn.net/baimafujinji/article
Apriori演算法簡介---關聯規則的頻繁項集演算法
①Apriori演算法的缺點:(1)由頻繁k-1項集進行自連線生成的候選頻繁k項集數量巨大。(2)在驗證候選頻繁k項集的時候需要對整個資料庫進行掃描,非常耗時。 ②網上提到的頻集演算法的幾種優化方法:1. 基於劃分的方法。2. 基於hash的方法。3. 基於取樣的方法。4. 減少交易的個數。
閉頻繁項集的挖掘——Closet演算法
Closet演算法有很大一部分涉及到了FP-Growth演算法,但是FP-Growth什麼的大牛們都寫了很多就不多贅述了吧。 話不多說直接上方法。 首先,對事務資料庫進行掃描,得到一個根據項的支援度從大到小排序的項集合F_list,將不頻繁的項刪除。 然後根據F_li
FPgrowth用python3實現挖掘頻繁項集
輸入: simpDat = [['r', 'z', 'h', 'j', 'p'], ['z', 'y', 'x', 'w', 'v', 'u', 't', 's'], ['z'],