
乾貨 | 論Elasticsearch資料建模的重要性
1、什麼是資料模型?
資料模型是抽象描述現實世界的一種工具和方法,是通過抽象的實體及實體之間聯絡的形式,用圖形化的形式去描述業務規則的過程,從而表示現實世界中事務的相互關係的一種對映。
核心概念:
實體:現實世界中存在的可以相互區分的事務或概念稱為實體。
實體可以分為事物實體和概念實體。例如:一個學生、一個程式設計師等是事物實體。一門課、一個班級等稱為概念實體。實體的屬性:每個實體都有自己的特徵,利用實體的屬性可以區別不同的實體。例如。學生實體的屬性為姓名、性別、年齡等。
2、資料建模的過程?
資料建模大致分為三個階段,概念建模階段,邏輯建模階段和物理建模階段。

2.1 概念建模階段
概念建模階段,主要做三件事:
- 客戶交流
- 理解需求
- 形成實體
確定系統的核心需求和範圍邊界,設計實體與實體之間的關係。
在概念建模階段,我們只需要關注實體即可,不用關注任何實現細節。很多人都希望在這個階段把具體表結構,索引,約束,甚至是儲存過程都想好,沒必要!因為這些東西使我們在物理建模階段需要考慮的東西,這個時候考慮還為時尚早。
概念模型在整個資料建模時間佔比:10%左右。
2.2 邏輯建模階段
邏輯建模階段,主要做二件事:
- 進一步樹立業務需求,
- 確定每個實體的屬性、關係和約束等。
邏輯模型是對概念模型的進一步分解和細化,描述了實體、實體屬性以及實體之間的關係,是概念模型延伸,一般的邏輯模型有第三正規化,星型模型和雪花模型。模型的主要元素為主題、實體、實體屬性和關係。
邏輯模型的作用主要有兩點。
- 一是便於技術開發人員和業務人員或者使用者進行溝通 交流,使得整個概念模型更易於理解,進一步明確需求。
- 二是作為物理模型設計的基礎,由於邏輯模型不依賴於具體的資料庫實現,使用邏輯模型可以生成針對具體 資料庫管理系統的物理模型,保證物理模型充分滿足使用者的需求。
邏輯模型在整個資料建模時間佔比:60—70%左右。
2.3 物理建模階段
物理建模階段,主要做一件事:
- 結合具體的資料庫產品(mysql/oracle/mongo/elasticsearch),在滿足業務讀寫效能等需求的前提下確定最終的定義。
物理模型是在邏輯模型的基礎上描述模型實體的細節,包括資料庫產品對應的資料型別、長度、索引等因素,為邏輯模型選擇一個最有的物理儲存環境。
邏輯模型轉化為物理模型的過程也就是實體名轉化為表名,屬性名轉化為物理列名的過程。
在設計物理模型時,還需要考慮資料儲存空間的分配,包括對列屬性必須做出明確的定 義。
例如:客戶姓名的資料型別是varchar2,長度是20,儲存在Oracle資料庫中,並且建立索引用於提高該欄位的查詢效率。
物理模型在整個資料建模時間佔比:20—30%左右。
3、資料建模的意義?

如下圖所示:
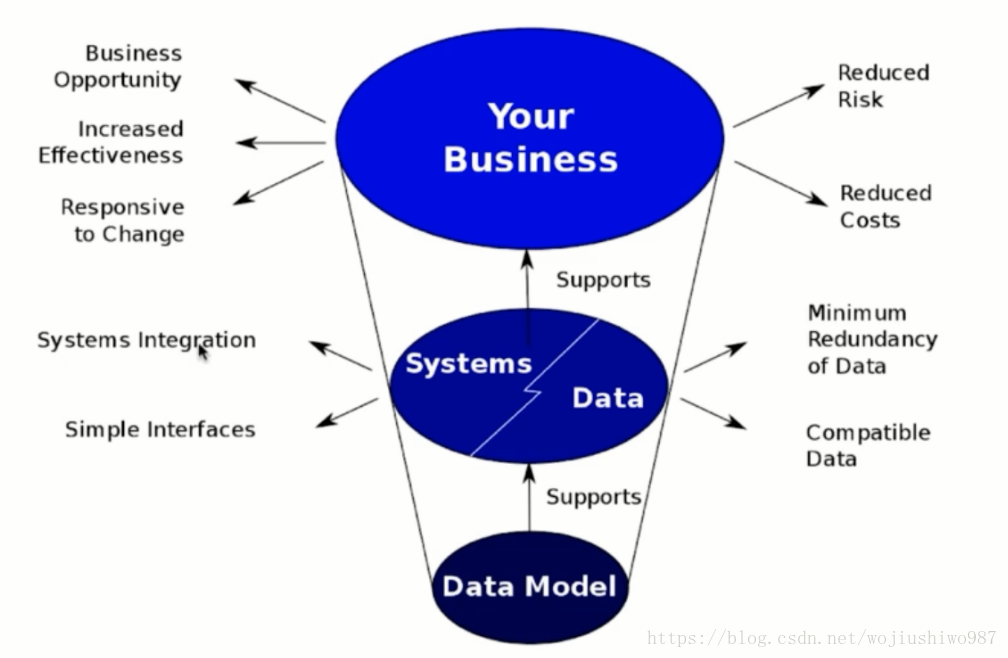
資料模型支撐了系統和資料,系統和資料支撐了業務系統。
一個好的資料模型:
- 能讓系統更好的整合、能簡化介面。
- 能簡化資料冗餘、減少磁碟空間、提升傳輸效率。
- 相容更多的資料,不會因為資料型別的新增而導致實現邏輯更改。
- 能幫助更多的業務機會,提高業務效率。
- 能減少業務風險、降低業務成本。
舉例: 藉助logstash實現mysql到Elasticsearch的增量同步,如果資料建模階段沒有設計:時間戳或者自增ID,就幾乎無法實現。
4、Elasticsearch資料建模注意事項
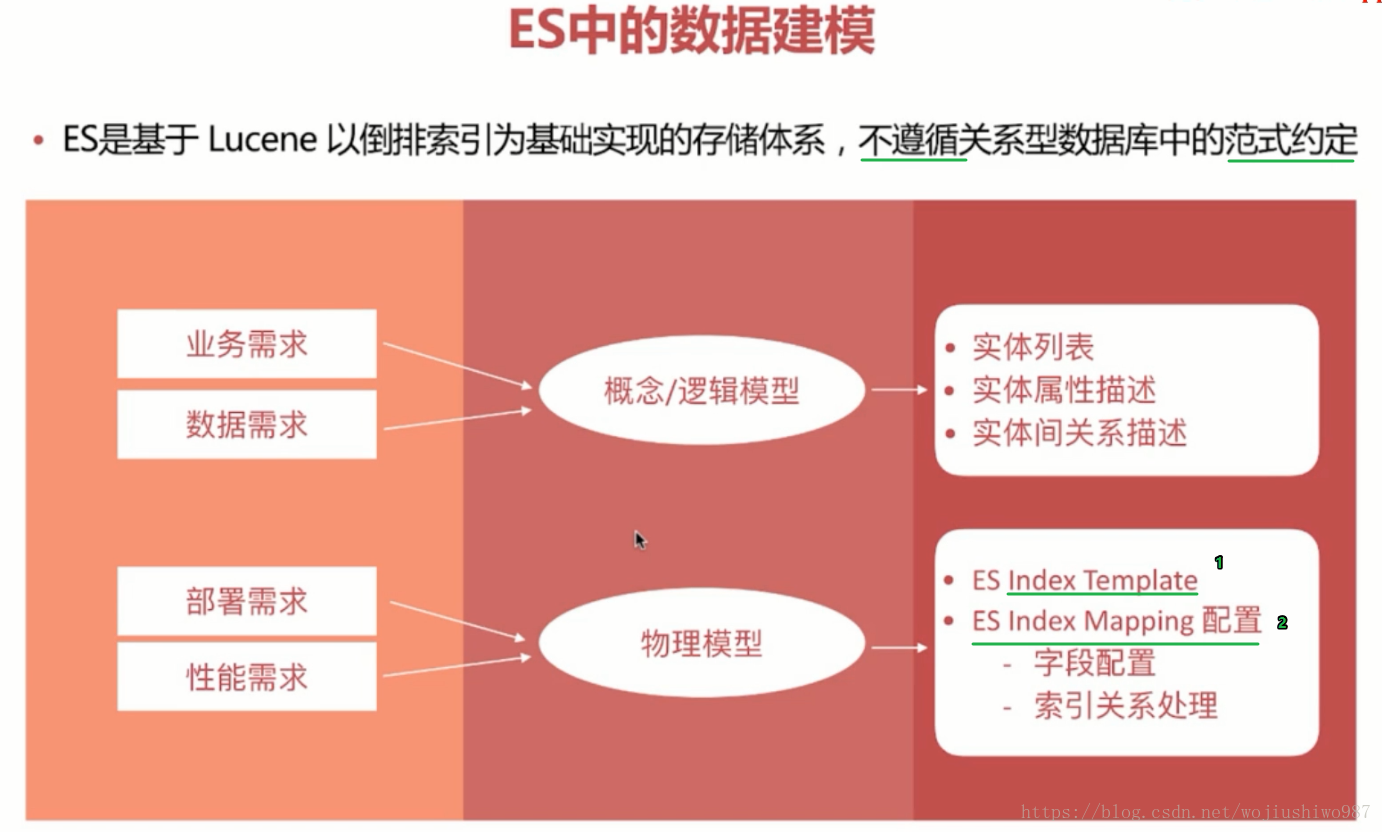
4.1 ES Mapping 設定
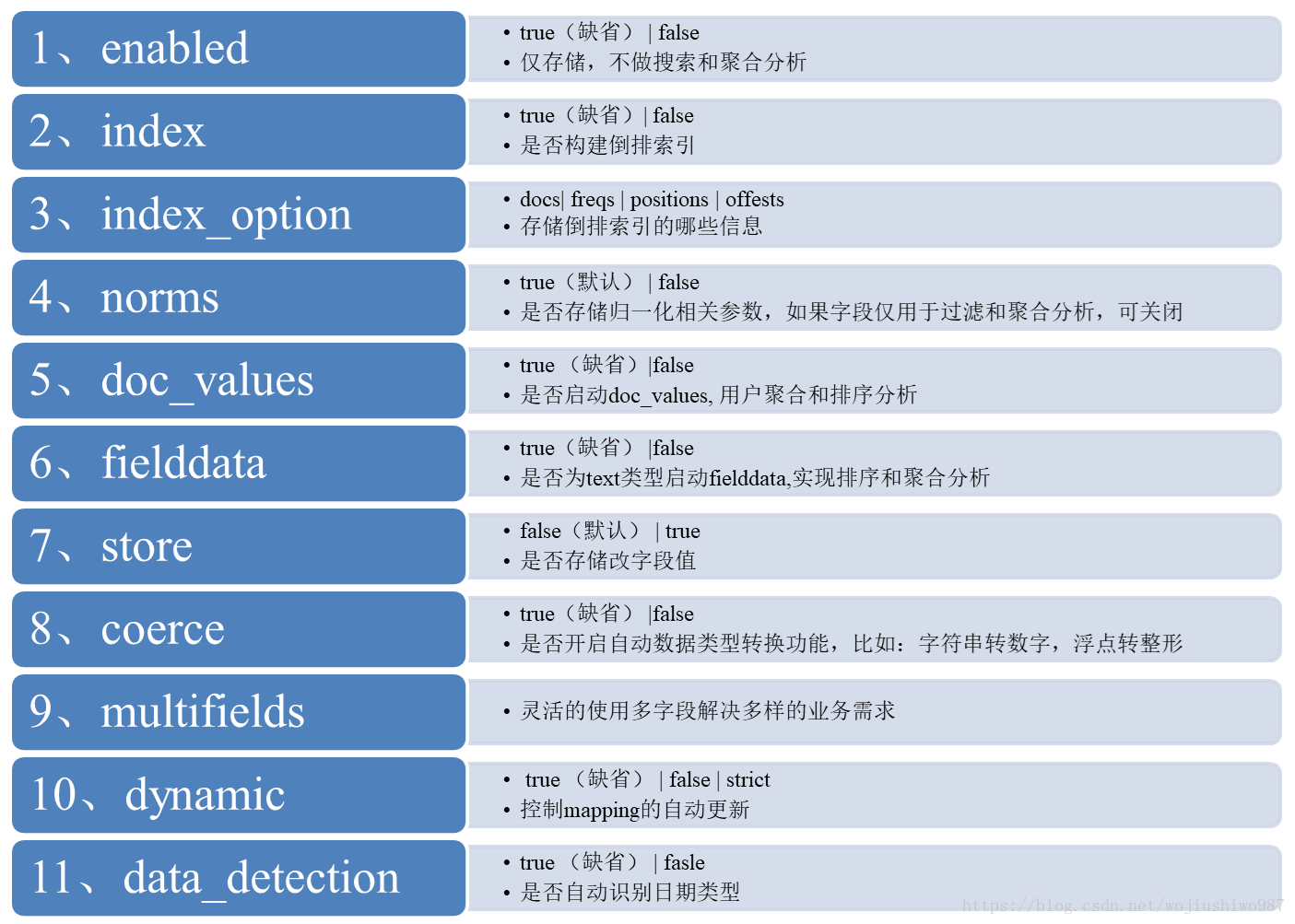
4.2 ES Mapping 欄位設定流程圖
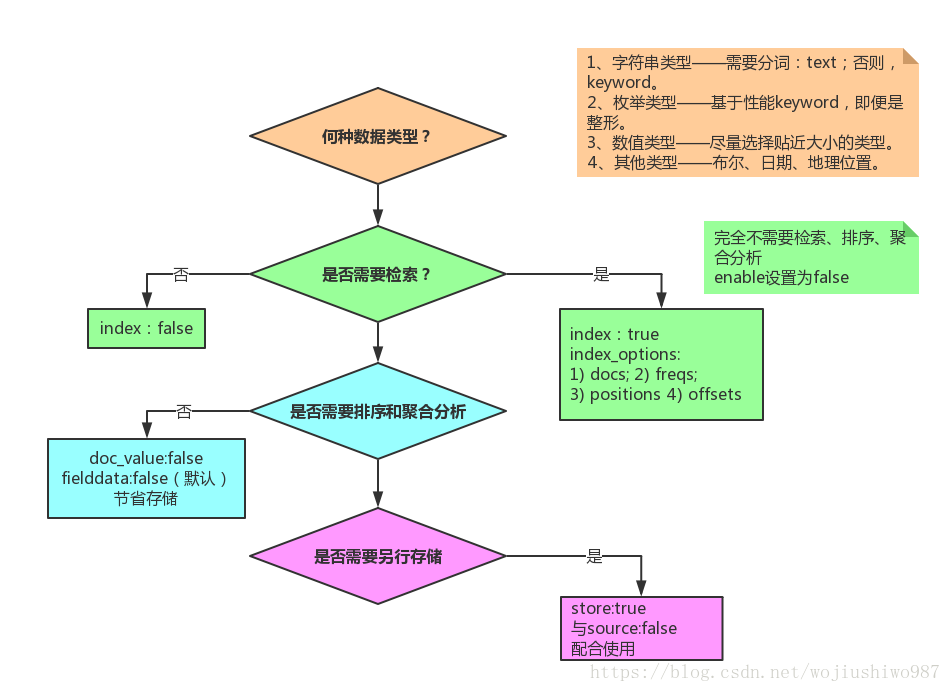
4.3 ES 萬能Mapping 模板參考
以下的索引 Mapping中,_source設定為false,同時各個欄位的store根據需求設定了true和false。
url的doc_values設定為false,該欄位url不用於聚合和排序操作。
PUT blog_index
{
"mappings": {
"doc": {
"_source": {
"enabled": false
},
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 100
}
},
"store": true
},
"publish_date": {
"type": "date",
"store": true
},
"author": {
"type": "keyword",
"ignore_above": 100,
"store": true
},
"abstract": {
"type": "text",
"store": true
},
"content": {
"type": "text",
"store": true
},
"url": {
"type": "keyword",
"doc_values":false,
"norms":false,
"ignore_above": 100,
"store": true
}
}
}
}
}5、不可迴避——ES多表關聯
實際業務問題:多層資料結構,一對多關係,如何用一個查詢查詢所有的資料?
比如資料結構如下:帖子–帖子評論–評論使用者 3層。
現在需要查詢一條帖子,最好能查詢到帖子下的評論,還有評論下面的使用者資料,一個查詢能搞定嗎?目前兩層我可以查詢到,3層就不行了。
如果一次查詢不到,那如何設計資料結構?又應該如何查詢呢?
目前ES主要有以下4種常用的方法來處理資料實體間的關聯關係:
(1)Application-side joins(服務端Join或客戶端Join)
這種方式,索引之間完全獨立(利於對資料進行標準化處理,如便於上述兩種增量同步的實現),由應用端的多次查詢來實現近似關聯關係查詢。這種方法適用於第一個實體只有少量的文件記錄的情況(使用ES的terms查詢具有上限,預設1024,具體可在elasticsearch.yml中修改),並且最好它們很少改變。這將允許應用程式對結果進行快取,並避免經常執行第一次查詢。
(2)Data denormalization(資料的非規範化)
這種方式,通俗點就是通過欄位冗餘,以一張大寬表來實現粗粒度的index,這樣可以充分發揮扁平化的優勢。但是這是以犧牲索引效能及靈活度為代價的。使用的前提:冗餘的欄位應該是很少改變的;比較適合與一對少量關係的處理。當業務資料庫並非採用非規範化設計時,這時要將資料同步到作為二級索引庫的ES中,就很難使用上述增量同步方案,必須進行定製化開發,基於特定業務進行應用開發來處理join關聯和實體拼接。
ps:寬表處理在處理一對多、多對多關係時,會有欄位冗餘問題,適合“一對少量”且這個“一”更新不頻繁的應用場景。寬表化處理,在查詢階段如果只需要“一”這部分時,需要進行結果去重處理(可以使用ES5.x的欄位摺疊特性,但無法準確獲取分頁總數,產品設計上需採用上拉載入分頁方式)
(3)Nested objects(巢狀文件)
索引效能和查詢效能二者不可兼得,必須進行取捨。巢狀文件將實體關係巢狀組合在單文件內部(類似與json的一對多層級結構),這種方式犧牲索引效能(文件內任一屬性變化都需要重新索引該文件)來換取查詢效能,可以同時返回關係實體,比較適合於一對少量的關係處理。
ps: 當使用巢狀文件時,使用通用的查詢方式是無法訪問到的,必須使用合適的查詢方式(nested query、nested filter、nested facet等),很多場景下,使用巢狀文件的複雜度在於索引階段對關聯關係的組織拼裝。
(4)Parent/child relationships(父子文件)
父子文件犧牲了一定的查詢效能來換取索引效能,適用於一對多的關係處理。其通過兩種type的文件來表示父子實體,父子文件的索引是獨立的。父-子文件ID對映儲存在 Doc Values 中。當對映完全在記憶體中時, Doc Values 提供對對映的快速處理能力,另一方面當對映非常大時,可以通過溢位到磁碟提供足夠的擴充套件能力。 在查詢parent-child替代方案時,發現了一種filter-terms的語法,要求某一欄位裡有關聯實體的ID列表。基本的原理是在terms的時候,對於多項取值,如果在另外的index或者type裡已知主鍵id的情況下,某一欄位有這些值,可以直接巢狀查詢。具體可參考官方文件的示例:通過使用者裡的粉絲關係,微博和使用者的關係,來查詢某個使用者的粉絲髮表的微博列表。
ps:父子文件相比巢狀文件較靈活,但只適用於“一對大量”且這個“一”不是海量的應用場景,該方式比較耗記憶體和CPU,這種方式查詢比巢狀方式慢5~10倍,且需要使用特定的has_parent和has_child過濾器查詢語法,查詢結果不能同時返回父子文件(一次join查詢只能返回一種型別的文件)。而受限於父子文件必須在同一分片上,ES父子文件在滾動索引、多索引場景下對父子關係儲存和聯合查詢支援得不好,而且子文件type刪除比較麻煩(子文件刪除必須提供父文件ID)。
如果業務端對查詢效能要求很高的話,還是建議使用寬表化處理*的方式,這樣也可以比較好地應對聚合的需求。在索引階段需要做join處理,查詢階段可能需要做去重處理,分頁方式可能也得權衡考慮下。
6、小結
本篇文章基於rockybean《Elasticsearch從入門到實踐》資料建模篇結合社群精彩問答進行了梳理和擴充套件,“站在巨人的”肩上,更能體會建模的重要性。
實際業務開發中,務必重視建模,前期在建模方面多下苦功夫、後期的業務系統開發才能水到渠成,更健壯、更有擴充套件性!

打造Elasticsearch基礎、進階、實戰第一公眾號!