
深度學習之3D卷積神經網路
一、概述
3D CNN主要運用在視訊分類、動作識別等領域,它是在2D CNN的基礎上改變而來。由於2D CNN不能很好的捕獲時序上的資訊,因此我們採用3D CNN,這樣就能將視訊中時序資訊進行很好的利用。首先我們介紹一下2D CNN與3D CNN的區別。如圖1所示,a)和b)分別為2D卷積用於單通道影象和多通道影象的情況(此處多通道影象可以指同一張圖片的3個顏色通道,也指多張堆疊在一起的圖片,即一小段視訊),對於一個濾波器,輸出為一張二維的特徵圖,多通道的資訊被完全壓縮了。而c)中的3D卷積的輸出仍然為3D的特徵圖。也就是說採用2D CNN對視訊進行操作的方式,一般都是對視訊的每一幀影象分別利用CNN來進行識別,這種方式的識別沒有考慮到時間維度的幀間運動資訊,而使用3D CNN能更好的捕獲視訊中的時間和空間的特徵資訊。
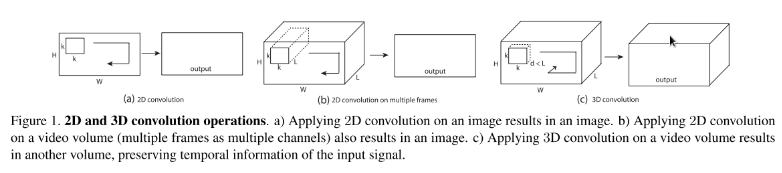
圖一
二、原理
首先我們看一下3D CNN是如何對時間維度進行操作的,如圖二所示,我們將時間維度看成是第三維,這裡是對連續的四幀影象進行卷積操作,3D卷積是通過堆疊多個連續的幀組成一個立方體,然後在立方體中運用3D卷積核。在這個結構中,卷積層中每一個特徵map都會與上一層中多個鄰近的連續幀相連,因此捕捉運動資訊。
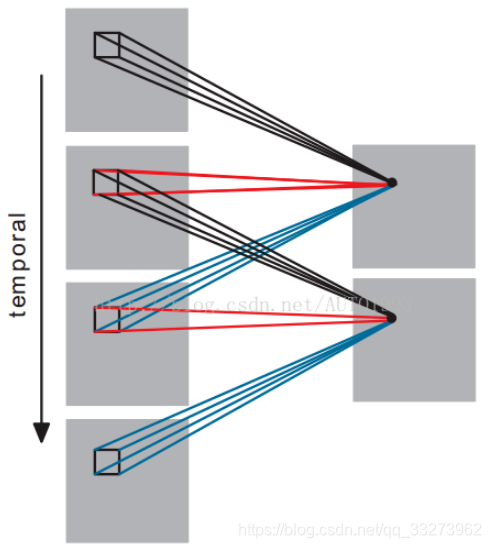
圖二
注:3D卷積核只能從cube中提取一種型別的特徵,因為在整個cube中卷積核的權值都是一樣的,也就是共享權值,都是同一個卷積核(圖中同一個顏色的連線線表示相同的權值)。我們可以採用多種卷積核,以提取多種特徵 。
圖三是3D卷積神經網路的整體架構

圖三
input—>H1
神經網路的輸入為7張大小為60*40的連續幀,7張幀通過事先設定硬核(hardwired kernels)獲得5種不同特徵:灰度、x方向梯度、y方向梯度、x方向光流、y方向光流,前面三個通道的資訊可以直接對每幀分別操作獲取,後面的光流(x,y)則需要利用兩幀的資訊才能提取,因此H1層的特徵maps數量:(7+7+7+6+6=33),特徵maps的大小依然是60* 40。
H1—>C2
用兩個7*7*3的3D卷積核對5個channels分別進行卷積,獲得兩個系列,每個系列5個channels(7* 7表示空間維度,3表示時間維度,也就是每次操作3幀影象),同時,為了增加特徵maps的個數,在這一層採用了兩種不同的3D卷積核,因此C2層的特徵maps數量為:(((7-3)+1)* 3+((6-3)+1)* 2)* 2=23* 2。這裡右乘的2表示兩種卷積核。特徵maps的大小為:((60-7)+1)* ((40-7)+1)=54 * 34。然後為卷積結果加上偏置套一個tanh函式進行輸出。(典型神經網。)

C2—>S3
2x2池化,下采樣。下采樣之後的特徵maps數量保持不變,因此S3層的特徵maps數量為:23 *2。特徵maps的大小為:((54 / 2) * (34 /2)=27 *17
S3—>C4
為了提取更多的影象特徵,用三個7*6*3的3D卷積核分別對各個系列各個channels進行卷積,獲得6個系列,每個系列依舊5個channels的大量maps。
我們知道,從輸入的7幀影象獲得了5個通道的資訊,因此結合總圖S3的上面一組特徵maps的數量為((7-3)+1) * 3+((6-3)+1) * 2=23,可以獲得各個通道在S3層的數量分佈:
前面的乘3表示gray通道maps數量= gradient-x通道maps數量= gradient-y通道maps數量=(7-3)+1)=5;
後面的乘2表示optflow-x通道maps數量=optflow-y通道maps數量=(6-3)+1=4;
假設對總圖S3的上面一組特徵maps採用一種7 6 3的3D卷積核進行卷積就可以獲得:
((5-3)+1)* 3+((4-3)+1)* 2=9+4=13;
三種不同的3D卷積核就可獲得13* 3個特徵maps,同理對總圖S3的下面一組特徵maps採用三種不同的卷積核進行卷積操作也可以獲得13*3個特徵maps,
因此C4層的特徵maps數量:13* 3* 2=13* 6
C4層的特徵maps的大小為:((27-7)+1)* ((17-6)+1)=21*12
然後加偏置套tanh。
C4—>S5
3X3池化,下采樣。此時每個maps的大小:7* 4。通道maps數量分佈情況如下:
gray通道maps數量= gradient-x通道maps數量= gradient-y通道maps數量=3
optflow-x通道maps數量=optflow-y通道maps數量=2;
S5—>C6
進行了兩次3D卷積之後,時間上的維數已經被壓縮得無法再次進行3D卷積(兩個光流channels只有兩個maps)。此時對各個maps用7*42D卷積核進行卷積,加偏置套tanh(煩死了!),獲得C6層。C6層維度已經相當小,flatten為一列有128個節點的神經網路層。
C6—>output
經典神經網路模型兩層之間全連結,output的節點數目隨標籤而定。
三、應用
這裡可以將3D卷積神經網路應用在卷積自編碼器上,最近看了一篇3D CAE在高光譜影象上應用的文章:LEARNING SENSOR-SPECIFIC FEATURES FOR HYPERSPECTRAL IMAGES VIA 3-DIMENSIONAL CONVOLUTIONAL AUTOENCODER。這篇文章將高光譜影象的波段這一維轉化成3D卷積神經網路的時間維,在卷積自編碼器中使用3D卷積,得到了很好的效果,下面是其中卷積核和通道的變化表格。


參考: